01:58
(央視財經【正點財經】)對於人工智能大語言模型來說,通常給予的訓練數據越多,模型就會越「聰明」。但英國【自然】雜誌最新發表的一項關於大模型的研究顯示,如果只用AI生成的數據來訓練大模型,會使模型效能下降,還可能越練越「傻」。
據了解,這項研究由英國牛津大學、劍橋大學等機構共同參與。研究人員發現,如果在訓練大模型時,只用人工智能生成的內容,會導致大模型出現不可逆的缺陷,逐漸忘記真實數據的分布,這被稱為「模型崩潰」。
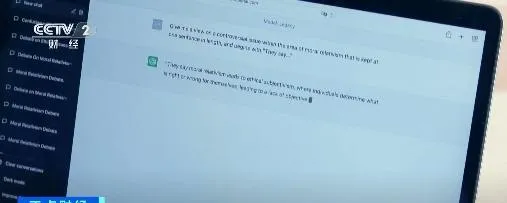
研究人員首先使用大語言模型建立類似維基百科詞條的文本,然後利用這個內容來訓練該模型的新版本,並反復使用前代模型生成的文本訓練更新的版本。在模型的第九次叠代中,它完成了一篇關於英國教堂塔樓的文章,其中一段文字卻在講述野兔尾巴的多種顏色。

研究發現,導致「模型崩潰」的重要原因是,由於模型只能從其訓練數據中采樣,一些在第一代數據中本就低頻出現的詞匯,在每次叠代後出現的頻率變得更低,而一些常見詞匯出現的頻率則逐漸增加。這種變化的結果就是,模型逐漸無法正確模擬真實世界的復雜性。隨著時間推移,這種錯誤會在叠代中被層層累積、逐漸放大,最終導致「模型崩潰」。

不過,應對「模型崩潰」並非束手無策。研究人員表示,如果能在模型微調過程中保留10%左右的真實數據,崩潰就會發生得更緩慢。還可以在大型科技公司的協作下使用浮水印技術,將AI生成的數據與真實數據區分開來。此外,在AI生成的文本重新進入數據池之前,可由人類先篩選過濾,也會有效應對「模型崩潰」。
轉載請註明央視財經
編輯:安琪











