01:58
(央视财经【正点财经】)对于人工智能大语言模型来说,通常给予的训练数据越多,模型就会越「聪明」。但英国【自然】杂志最新发表的一项关于大模型的研究显示,如果只用AI生成的数据来训练大模型,会使模型性能下降,还可能越练越「傻」。
据了解,这项研究由英国牛津大学、剑桥大学等机构共同参与。研究人员发现,如果在训练大模型时,只用人工智能生成的内容,会导致大模型出现不可逆的缺陷,逐渐忘记真实数据的分布,这被称为「模型崩溃」。
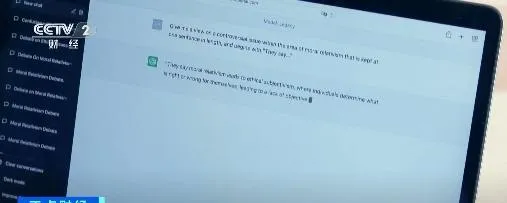
研究人员首先使用大语言模型创建类似维基百科词条的文本,然后利用这个内容来训练该模型的新版本,并反复使用前代模型生成的文本训练更新的版本。在模型的第九次迭代中,它完成了一篇关于英国教堂塔楼的文章,其中一段文字却在讲述野兔尾巴的多种颜色。

研究发现,导致「模型崩溃」的重要原因是,由于模型只能从其训练数据中采样,一些在第一代数据中本就低频出现的词汇,在每次迭代后出现的频率变得更低,而一些常见词汇出现的频率则逐渐增加。这种变化的结果就是,模型逐渐无法正确模拟真实世界的复杂性。随着时间推移,这种错误会在迭代中被层层累积、逐渐放大,最终导致「模型崩溃」。

不过,应对「模型崩溃」并非束手无策。研究人员表示,如果能在模型微调过程中保留10%左右的真实数据,崩溃就会发生得更缓慢。还可以在大型科技公司的协作下使用水印技术,将AI生成的数据与真实数据区分开来。此外,在AI生成的文本重新进入数据池之前,可由人类先筛选过滤,也会有效应对「模型崩溃」。
转载请注明央视财经
编辑:安琪











