
摘要:海光作为国内高端处理器领军企业,凭借持续的技术创新和市场需求增长,正展现出强劲的发展势头。
目前看来,海光的处理器在对AI服务器市场的争夺中拥有显著优势,特别是其GPGPU系列能够满足大模型应用的通用需求,对于缓解中国算力缺口具有重要意义。
同时,海光正在积极构建广泛产业链生态,推动智能计算与数值计算的深度融合,助力AI在多个领域的规模应用。更重要的是,海光完全兼容x86生态和类CUDA生态,相对而言在生态层面更具竞争力。
以下是正文:
随着人工智能和以服务器为中心的大数据技术飞速发展,芯片产业正迎来前所未有的变革。在这一浪潮中,国产市场正逐步崛起,重塑玩家生态。
这其中,海光是国内高端处理器企业中的一个典型案例。
成立于2014年,海光凭借2018-2022年国内高端处理器需求增加的风口快速起飞,其中每一年增速均超过100%,并于2021年实现盈利。(如图一)
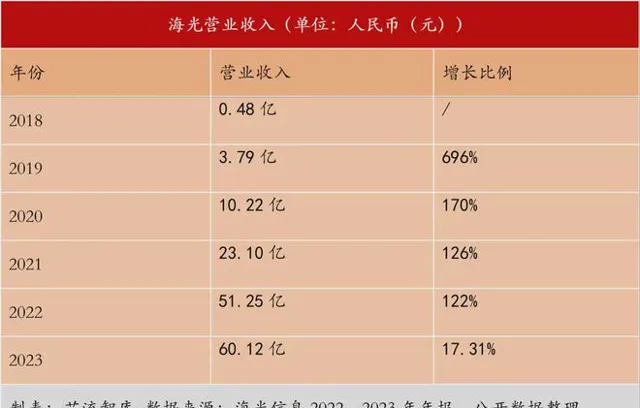 (图一)
(图一)
营收的稳定增长背后包含着产品性能提升的因素。「海光三号」系列CPU相比上一代产品,整体实测性能提升了约45%;而基于「类CUDA」框架的GPGPU「深算二号」实现了相较于前一代性能翻倍的增长,在国内通用图形处理器中领先。
产业界的故事往往如此,多数玩家缘起于某个风口构筑起宏大的梦想,而随着时移世易,如何打磨自身、陪伴行业一同走下去则区分了每位选手。
走到后半程的选手不多,海光的故事则具有独特的启示。
01
师夷长技,攻克国产高端处理器难关
国内半导体产业的发展趋势往往强相关于市场环境,对于高端处理器企业而言,国内市场动向对芯片供求关系的影响十分重要。
值得注意的是,当前中国的服务器产业正在构建一个以实际应用为核心、以终端设备为主导、以AI技术为发展契机的崭新生态环境。
国内服务器市场前景广阔的情况下,一个尖锐的问题在于:服务器的大脑——国产高端处理器仍然处于多半的空白状态。
据统计,外资品牌在高端处理器市场上仍占据主导地位,英伟达和AMD两家美国企业就瓜分了中国GPGPU的90%市场;国产处理器的生态系统相对薄弱,缺乏与英特尔和AMD的x86生态相抗衡的能力。
在这样的条件下,国产高端处理器市场空白急需相关企业填补、供求关系也暗示着国内芯片产业势必在一定时间内迎来需求浪潮。 所有玩家都在试图尽早关注服务器对处理器行业的推动作用,至少在技术研发和商业模式上先摆好姿态。
这其中,技术「硬实力」是首先绕不开的问题。对于拥有永久指令集授权的海光来说,本身拥有足够优质的生态基础,后续的重心在于如何进行改进、提高和自主研发。
从财务数据看,2023年,海光在研发方面的投入高达28亿元,同比增长35.93%,研发投入占营业收入的比例高达46.74%。研发配置上,公司现有研发技术人员1641人,占员工总人数的91.68%,其中超过79.28%的研发技术人员拥有硕士及以上学历。
根据海光2023年年报,公司自主知识产权体系已涵盖发明专利670项、实用新型专利90项、外观设计专利3项,同时获得了集成电路布图设计登记证书228项和软件著作权244项。
从目前来看,人才生态仍然是消化吸收新架构过程中不可或缺的一环。 一位业内的资深人士曾向我们表示,目前以海光为代表的公司已经越过了对x86的吸收消化阶段,自研方面也取得重大突破,鉴于全盘解决x86问题的国内人才往往并不多,目前普遍采取的是分团队逐块进行的方式。
而在背后的现金流支持上,海光可以说是芯片行业罕见具有稳定盈利的公司。
2023年,海光实现17亿元净利润,相较于同行业的寒武纪同期净亏损约8.78亿元、景嘉微同期净亏损约0.60亿元,海光更有能力在高端处理器市场的争夺中站稳脚跟。
具体分析,海光稳定的盈利能力很大部分来源于技术领先带来的合理产业结构高毛利。集成电路产品作为公司的主营业务,其实现的营业收入高达60.12亿元,占公司总营业收入的绝大部分。
02
双线作战,GPGPU迎战大模型风口
AI与芯片产业的联系绕不开GPU。
GPU有相较于CPU更加强大的并行计算能力,更加贴合AI进行大量计算的需求。GPGPU(通用图形处理器)作为一种特化的专门用于科学计算的处理器,实际为AI产业发展的重要硬件基础。
尽管当前大模型行业正处于蓬勃发展阶段,预计至2028年市场规模将达到1179亿元,但算力却成为各家厂商的头号焦虑。
训练大模型对算力需求尤其大。以大模型ChatGPT3为例,训练该模型所需的算力大约为3640PFlop/s-day(即如果每秒计算一千万亿次,需要计算3640天),约等于64个英伟达A100 GPU训练1年的时间。
在英伟达垄断了全球绝大多数GPU市场的情况下,其在相关芯片上的坐地起价必将导致大模型的高成本。据估计,彼时ChatGPT3训练一轮需要花费1200美元,再加上美国连如同RTX4090一样的GPU都禁止输出到中国,中国实际上面临巨大的算力缺口, 国内的政企、个体用户也急需英伟达的国内平替。
这些需求恰好与海光推出的「深算」系列GPGPU产品路线相适配。
以8000系列为例,海光8000系列展现出卓越的全精度浮点数据及各类常见整型数据的计算能力。它通过深入挖掘应用的并行性,充分释放其大规模并行计算的潜力,从而高效快速地开发高能效的应用程序。
海光GPGPU被设计为在服务器集群或数据中心环境中高效运作,旨在为应用程序提供卓越的性能和能效比。这使得它相较于同行产品成为处理高复杂度和高吞吐量数据任务的理想选择。
在当前AIGC技术迅猛发展的背景下,海光GPGPU能够支持全精度模型训练和千亿级别模型输出,「类CUDA」式设计也极大扩展了泛用性,能够满足如LLaMa、GPT、Bloom、ChatGLM、悟道、紫东太初等大模型的全面应用需求。更值得一提的是,海光GPGPU与国内众多大模型,如文心一言等,实现了全面适配,其性能达到了国内领先水平。
围绕其产品,海光构建了名为「光合组织」的覆盖广泛的软硬件协同的生态体系。
通过与国内主流服务器厂商的紧密合作,海光围绕不同市场需求,基于对处理器和相关软件的应用,推出了多样化的产品系列,包括通用机架式服务器、人工智能服务器、刀片和高密度服务器、存储产品,以及视觉工作站和边缘计算产品等。
同时海光基于海光CPU及海光DCU系列产品,支持各行业构建高效能数据中心和算力平台,推动智能计算与数值计算的深度融合,在智慧城市、生物医药、工业制造、科学计算等领域的AI规模应用都有布局。
随着端侧大模型带动AI PC的爆火,在国产市场面临一系列数据、算力等问题的情况下,海光与一众GPGPU创企都即将迎来赛道狂奔的时刻。
03
尾声:做好国产高端处理器
CPU和GPU市场发展中,生态往往是比性能更难以颠覆的竞争要素,这一点不仅对海光,对其它产业内的玩家来说也同样适用。
基于此,以海光为代表的一众玩家需要考虑的不仅是做高端处理器,更肩负着与国内厂商适配的重要责任。
而这一点恰恰是海光的优势领域。
兼容国际主流的GPGPU生态,海光的产品通用性强,功能丰富,生态可用性高,且适配便捷,具体来说,只需简单工具和一两个人的时间就能完成从英伟达到海光的适配。
商业上,作为纯粹芯片企业,海光与下游客户存在一定的产业链差异,使用更便捷,下游客户负担较小,更容易做到公平分配。
国产半导体市场是一个足够垂直的圈子,但也同样依赖于多方共同的努力,生态和技术永远都是这一产业发展中双螺旋相互促进的核心要素,未来的追赶需要更多「天时」与「人和」。











