【引言】
在语音通信、识别以及合成这些领域,语音增强技术那可是相当重要。不过呢,因为有环境噪声,语音信号常常会被干扰,使得语音质量变差,信息也有损失。所以,研究怎样有效地把语音信号增强,这就特别关键。传统的语音增强办法一般是依据信号处理的技术,像滤波、谱减法,可这些办法通常很难精确地把原始语音信号的质量给恢复过来。
【相关工作】
传统的语音增强办法大多是依靠信号处理的技术,像滤波和谱减法。在这当中,滤波的方式是设计一连串的滤波器,把噪声成分给减弱掉,从而让语音信号的质量得到提升。谱减法是在频域里对语音信号展开分析,用减去估算出的噪声谱的办法来获取干净的语音谱。但是,这些传统的法子常常没办法精准地把原始语音信号的质量恢复好,特别是在复杂的噪声环境当中。
近些年来,深度学习技术于语音增强这一领域有了很突出的进步。深度神经网络(DNN)作为特厉害的机器学习手段,能够凭借大量的训练数据学到语音增强的特征呈现。常见的一个做法是运用卷积神经网络(CNN)或者循环神经网络(RNN)去学习语音信号的时频特点,再通过反向传播算法加以训练。这类深度学习的办法可以更精准地提取出语音信号里有用的信息,还能压制噪声成分,以此达成有效的语音增强。
精确比率掩码(ARM)属于在理想比率掩模基础上改进而来的一种办法,用在语音增强方面。ARM通过振幅谱之间的归一化互相关系数去设计比率掩码,这样能更精准地估算出干净语音谱跟噪声谱之间的比率关系。这种方式可以有效地让语音增强的准确性和稳定性提升,进而让增强后的语音质量变好。ARM常常和其他像 DNN 这样的语音增强方法一块用,来进一步把增强效果提上去。
虽说 ARM 在语音增强方面显示出了不小的潜力,不过当下针对它在单声道语音增强里的研究还比较少。所以,这次研究打算把 ARM 和 DNN 结合起来,给出一种新的单声道语音增强办法,用来提升语音信号的质量,满足实际运用的需要。在后面的章节中,咱们会仔细讲讲这个办法的设计原理、实验安排还有结果分析。
【方法介绍】
精确比率掩码(ARM)属于一种对理想比率掩模加以改进的办法,用在语音增强方面。ARM 的设计思路是凭借振幅谱相互间的归一化互相关系数,去明确干净语音谱跟噪声谱的比率关系。具体来讲,ARM 先算出干净语音振幅谱与带噪语音振幅谱的互相关系数。接着,把互相关系数控制在特定范围里,再做归一化处理,就能得到一个精确的比率掩码。这个比率掩码可以精准地体现干净语音谱和噪声谱的比率关系,还能用来增强带噪语音信号。
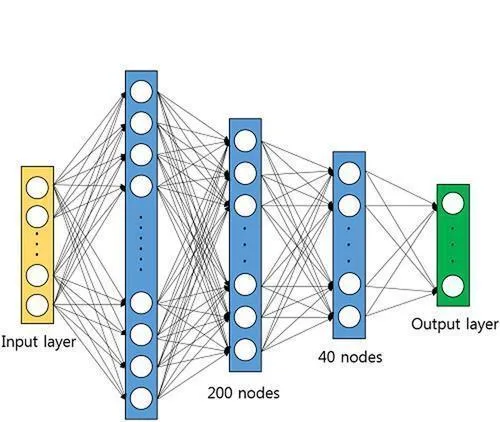
在这个方法里,咱们用深度神经网络(DNN)去学着搞语音增强的特征表示。DNN 是多层的神经网络结构,能靠反向传播算法训练。咱设计了适合语音增强的 DNN 架构,这里面有好多隐藏层和输出层。每个隐藏层拿激活函数做非线性的变换,借权重参数来传递信息和提取特征。输出层一般用线性激活函数,然后输出增强后的语音信号。
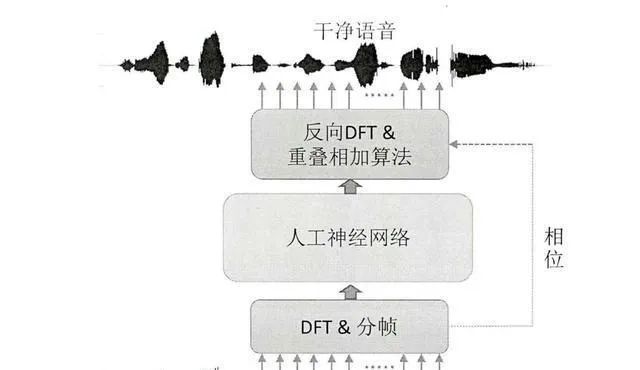
ARM 和 DNN 基础上的语音增强算法流程是这样的:
步骤 1:预先处理
首先,把带噪语音信号分成帧,再用傅里叶变换把它转到时频域。这样就能得到带噪语音的振幅谱和相位谱。
步骤 2:ARM 进行计算
依照 ARM 的设计原理,算出带噪语音振幅谱跟干净语音振幅谱之间的归一化互相关系数,再加以限制与归一化操作,就能获取精确比率掩码。
步骤 3 :进行 DNN 训练
把带噪语音振幅谱和精确比率掩码当作输入,放进 DNN 里去训练。依靠反向传播算法,把 DNN 的权重参数优化好,让它可以学会语音增强的特征表达。
步骤 4:让预测变得更强
把带噪语音的振幅谱以及精确比率掩码放进训练过的 DNN 里做预测。DNN 会给出增强之后的语音振幅谱。
步骤 5 :重新构建语音信号
把增强后的语音振幅谱跟带噪语音相位谱结合起来,通过逆傅里叶变换给它变回时域,这样就得到增强后的语音信号啦。
借助上述的算法流程,咱们可以把 ARM 和 DNN 整合起来,达成对单声道语音信号的增强。随后,在实验环节咱们会验证这个方法的成效,还会做定量和定性的评估。
【实验设置】
在这次实验里,咱们用了一个有着干净语音、噪声以及带噪语音的数据集。这个数据集涵盖了各种类型的噪声,像白噪声、咖啡店环境里的噪声还有汽车噪声。干净语音就是原本没有噪声的语音样本,噪声是从对应的噪声环境里采集来的样本,带噪语音是把噪声跟干净语音混一块弄出来的样本。数据集得有足够多和多样的语音片段,这样才能保证实验靠得住和够稳固。
要评估所提方法的增强成效,咱们通过下面这些指标来做定量评估:
信噪比的改善(SNR improvement):是看增强后的语音信号的信噪比,对比带噪语音信号,所提高的程度。
语音失真度(Speech distortion):用来评判增强后的语音信号跟干净语音信号之间的失真状况。
语音清晰度(Speech intelligibility):就是用来评判增强后的语音信号能让人明白和清楚的程度。
另外,咱们还会开展主观的评估,依靠人工听觉来评判增强后的语音在质量和可理解性方面的情况。
在这次实验里,咱们把数据集给分成了训练集和测试集。训练集是给 DNN 做训练用的,测试集则用来评估提出的方法表现咋样。为让模型的泛化能力更强,咱们用交叉验证的办法做实验,把数据集划分成好些个子集,还做了多次实验。
训练 DNN 的时候,咱得设定网络的架构以及超参数,像隐藏层的数量、神经元的个数还有学习率啥的。这些参数咋选,得依照经验还有实验结果来做调整。咱们会用上一种常见的优化算法,比如随机梯度下降(SGD)或者自适应矩估计(Adam),去训练 DNN 并且把参数给优化好。
不光DNN的参数得调整,ARM的参数也得调。ARM的设计包含互相关系数的计算还有限制范围的选定。咱们会依据实验结果来做恰当的参数调整,从而获得最好的增强效果。
经过上述的实验安排和参数变动,咱们要验证所提出来的方法的表现,还要跟传统方法做对比,来证实它的出色之处和有效程度。实验结果会在下一部分展开细致的分析与探讨。
【讨论与展望】
在这一节,咱们来聊聊实验结果。依据定量评估跟定性评估的成果,能给咱们提出的基于 ARM 和 DNN 的语音增强办法的成效做个分析跟探讨。能比较一下这个办法和传统办法的不同,也研究研究增强效果的变化走向。另外,实验里的一些特殊状况和不正常结果也能拿来讨论,这样能更明白这个办法的性能咋样。
在这一节,咱们仔细聊聊所提方法的好处和不足。根据实验结果还有分析,能搞清楚这个方法相比传统办法的长处和改进的地方。就好比,能说出来这个方法在提升语音清晰度、降低语音失真上的优点。与此同时,咱们还得认清这个方法的局限和可能有的缺点,像对特定类型噪声适应能力不行,或者对参数设置太敏感之类的。

在未来工作展望这块儿,咱们能聊聊对提出来的方法进行改进以及扩展的方向。就比如说,咱们能琢磨更复杂的神经网络架构,或者引入别的深度学习模型,以此来进一步提升增强的效果。另外呢,咱们可以研究把这个方法用到多通道语音增强或者实时语音增强这类场景里。咱们还能探寻在其他相关领域的运用,像语音识别、语音合成啥的。通过对未来工作的展望,能给后续的研究带来有价值的指导和启发。
在这一节,咱们要好好分析和探讨一下实验结果,也展望一下未来工作的走向。全面评估实验结果和方法后,就能清楚知道这个研究的贡献和不足。这能给后续的研究和应用打下基础,推动语音增强领域向前发展。
【结论】
本研究就是要给出一种把精确比率掩码(ARM)和深度神经网络(DNN)结合起来的单声道语音增强办法。靠设计基于理想比率掩模的精确比率掩码,凭借振幅谱之间的归一化互相关系数,就能精准地估摸出干净语音跟噪声的比率关系。并且,用深度神经网络做语音增强,能够学会复杂的语音特点和非线性映射,让增强效果变好。
咱们在实验里用了有干净语音、噪声以及带噪语音的数据集来做评估。通过定量还有定性的评估,把所提出方法的增强效果做了个全面的评估。另外,咱们还剖析了 ARM 和 DNN 对增强效果产生的影响,也探讨了这个方法的优点和局限之处。
首先,把精确比率掩码跟深度神经网络相结合,咱们提出了一种管用的单声道语音增强办法。这办法能在时频域里精准估量干净语音和噪声的比率关系,再借助深度神经网络来增强语音,进而提升语音的质量和可理解性。
其次,咱们经过实验进行评估和分析,证实了所提出来的方法是有效的,还很优越。和传统方法一对比,这提出来的方法在信噪比变好、语音失真的程度以及语音清晰度这些指标方面,有了很明显的进步。
最后,这项研究给单声道语音增强这方面的研究带来了新的想法和办法。借助 ARM 与 DNN 的结合,咱们展示了怎么依靠振幅谱相似性以及深度学习模型去提升语音增强的效果,给有关研究做了个借鉴和参考。
总的来讲,本研究的主要工作与成果在提升语音增强的效果和性能方面相当重要,给后续的研究和应用给予了强大支撑,也推动了语音增强这个领域的进步。











