今天分享的是算力專題研究二:【從訓練到推理:算力芯片需求的華麗轉身】, 幻影視界整理分享摘要內容如下:
一、 如何測算文本大模型 AI 推理端算力需求
推理算力市場已然興起, 24年AI 推理需求成為焦點。 據 Wind 轉引輝達FY24Q4 業績會紀要,公司 2024 財年數據中心有 40%的收入來自推理業務。
放眼國內,IDC 數據顯示,中國 23p 訓練工作負載的伺服器占比達到 49.4%,預計全年的占比將達到 58.7%。隨著訓練模型的完善與成熟,模型和套用產品逐步投入生產,推理端的人工智慧伺服器占比將隨之攀升,預計到 2027 年,用於推理的工作負載將達到 72.6%。
輝達
FY2024數據中心推理與訓練占比
中國人工智慧伺服器負載及預測

如何量化推理算力需求?與訓練算力相比,推理側是否具備更大的發展潛力?我們整理出 AI 推理側算力供給需求公式,並分類討論公式中的核心參數變化趨勢,以此給出我們的判斷。

需要說明的是,本文將視角聚焦於雲端 AI 推理算力,端側AI 算力主要由本地裝置內建的算力芯片承載。基於初步分析,我們認為核心需要解決的問題聚焦於需求側——推理消耗的數據規模如何測算?而供給側,GPU 效能提升速度、算力利用率等,我們認為與 AI 訓練大致無異。
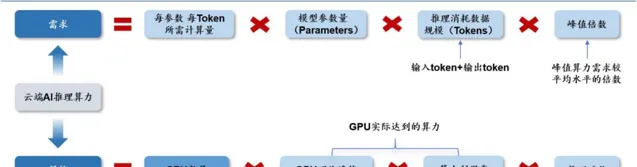
文本大模型雲端 AI 推理算力供給需求公式
二、 Scaling Laws& 長文本趨勢:推理需求的核心驅動力
根據 OpenAI【Scaling Laws for Neural Language Models】,並結合我們對於推理算力的理解, 我們拆解出雲端 AI 推理算力需求 ≈2× 模型參數量 × 數據規模 × 峰值倍數 。
雲端 AI 推理需求公式拆解

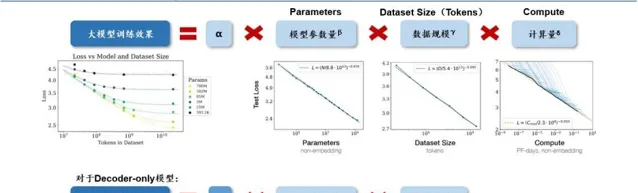
模型的最終效能主要與計算量、模型參數量和數據大小三者相關,而與模型的具體結構(層數/深度/寬度)基本無關。如下圖所示,對於計算量、模型參數量和數據規模,(1)當不受其他兩個因素制約時,模型效能與每個因素都呈現冪律關系。(2)如模型的參數固定,無限堆數據並不能無限提升模型的效能,模型最終效能會慢慢趨向一個固定的值。
因此,為了提升模型效能,模型參數量和數據大小需要同步放大。
Scaling Law
仍然是當下驅動行業發展的重要標準
。
大模型訓練的 Scaling Law
過去幾年來
AI
大模型參數量呈現快速增長。
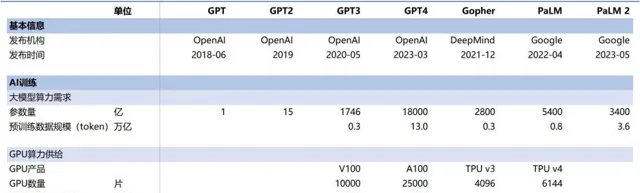
以 OpenAI 為例,GPT-3 到 GPT-4 歷時三年從 175B 參數快速提升到 1.8T 參數(提升 9 倍)。目前國內主流 AI 大模型也逐步突破了千億參數大關,乃至采用萬億參數進行預訓練。
海外主流
AI 大模型訓練側算力供給需求情況
國內主流 AI 大模型訓練側算力供給需求情況

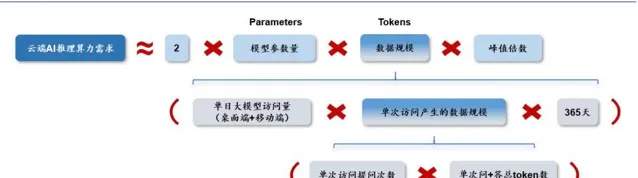
雲端 AI 推理需求公式進一步拆解
從大模型存取量來看, 我們認為需要覆蓋到不同流量入口的存取量之和,包括(1)桌面端,(2)移動端。由於 Similarweb 數據統計了桌面端+移動端所有流量之和,我們以此為基礎測算推理套用產生的 token 數據規模。
文本大模型網站存取量周度數據(單位:萬次)文本大模型網站存取量周度數據(單位:萬次)
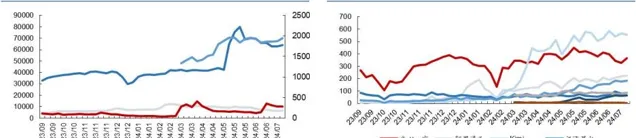
從單次存取產生的數據規模來看,運算公式可以拆解為單次提問的問題與答 案所包含的 token 數總和乘以單次存取提出的問題數,其中單次問答所包含的 token 數取決於字數&每個字對應的 token 數。
(1)字數:單次問答所包含的字數或多或少會受到大模型上下文視窗(Context Window)的限制。隨著上下文視窗瓶頸的快速突破,長文本趨勢成為主流。以 OpenAI 為例,從 GPT-3.5 升級至 GPT-3.5-Turbo,上下文視窗從 4k 升級為 16k;而 GPT-4 版 本時隔一年後升級為 GPT-4-Turbo,也將上下文視窗從 32k 提升至 128k。而以長文本 能力成為「頂流」的 Kimi,2023年10月上線時支持無失真上下文長度最多為20萬漢 字,24年3月已支持200萬字超長無失真上下文,長文本能力提高10倍。按照AI領 域的計算標準,200萬漢字的長度大約為400萬token,在全球範圍內也屬於領先的標準。
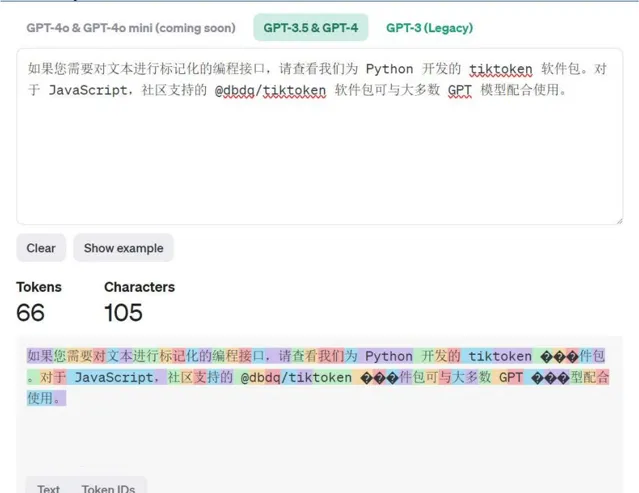
(2)每個字對應的 token 數:不同的大模型均有各自的分詞器設計,以 OpenAI 為例,1000 個 token 通常代表 750 個英文單詞或 500 個漢字。以其官網 Tokenizer 計 算工具結果來看,基本與此結論相契合。
OpenAI Platform Tokenize r
三 、 文本大模型雲端 AI 推理對 GPU 的需求量如何求解?
本文按第一章所示「文本大模型雲端 AI 推理算力供給需求公式」,逐步拆解計算過程。首先,測算 AI 大模型推理所需計算量,隨後透過對單 GPU 算力供給能力的假設,逐步倒推得到 GPU 需求數量。我們發現當前 OpenAI 在全球範圍內的存取量仍然斷層領先,由此我們推斷 OpenAI 在全球推理算力需求中占據較大比重,因此本文測算以 OpenAI 為例。
1. 雲端 AI 推理算力需求
1.1每參數每 token 所需計算量:根據 OpenAI【Scaling Laws for Neural Language Models】,並結合我們對於推理算力的理解,我們拆解出雲端 AI 推理算力需求≈2× 模型參數量×數據規模×峰值倍數,即每參數每 token 推理所需計算量為 2 Flop。
1.2大模型參數量:根據我們此前外發報告【如何測算文本大模型 AI 訓練端算 力需求?】,我們認為 Scaling Law 仍將持續存在,大模型或將持續透過提升參數量、 預訓練數據規模(token 數)帶動計算量提升,進而提升大模型效能,我們按過往提 升速度大致推斷未來增長情況。
1.3數據規模(tokens):從大模型存取量來看,我們以 Similarweb 統計的存取 量數據為測算基礎,透過趨勢的判斷,以及對 AI 推理能力提升帶動 AI 套用滲透趨 勢的信心,我們預計 24-26 年 OpenAI 存取量有望同比增長 60%/50%/30%。
需要說明 的是,由於 OpenAI 在 Similarweb 統計的存取量數據中以斷層優勢處於領先地位,我 們認為 OpenAI 在全球 AI 推理需求中占據相當大的比重。從單次存取產生的數據規 模來看,運算公式可以拆解為單次提問的問題與答案所包含的 token 數總和乘以單次 存取提出的問題數,其中單次問答所包含的token數取決於字數&每個字對應的 token 數。
(1)首先,我們假設 23 年大模型單次存取的問答次數為 5 次,隨著大模型的使 用頻率提高,使用者黏性增強,該次數有望穩步提升。
(2)我們假設單次提問一般對 應 30tokens 左右,另外我們取 23 年一次問答實驗中 12 次回答的平均字數(523 個漢 字)作為假設,基於 1:2 的換算比例,得到 23 年單次問答產生的 token 數為 1077 字 節。我們假設 24-26 年單次問答產生的 token 數有望跟隨大模型上下文視窗的長文本 化趨勢,而呈現爆發式增長。
1.4峰值倍數:我們假設 1、推理需求在一日之記憶體在峰谷,算力儲備比實際需 求高,2、隨算力套用的進一步泛化,峰值倍數有望逐漸下降。
2. 雲端 AI
2.1 GPU 計算效能:根據我們此前外發報告【如何測算文本大模型 AI 訓練端算力需求?】,我們假設未來輝達新產品的 FP16 算力在 Blackwell 架構的基礎上延續過往倍增趨勢。此外,我們假設訓練卡供不應求,由此推斷推理需求的實作相較於訓練需求的實作或延遲半代,AI 推理側或以輝達新一代及次新一代 GPU 為主,我們假設二者各占50%,以其平均 FP16 算力作為計算基準。
2.2 訓練時間&算力利用率:我們假設推理套用需求在全年 365 天是持續存在的, 由此假設全年推理時間為 365 天。根據我們此前外發報告【如何測算文本大模型 AI 訓練端算力需求?】,我們假設算力利用率在 30-42%區間,逐年提升。
四 、 結論: 若以輝達當代&前代 GPU 卡供給各占 50%計算,我們認為 2024-2026 年 OpenAI 雲端 AI 推理 GPU 合計需求量為 148/559/1341 萬張。
OpenAI 雲端 AI 推理算力需求-供給測算

綜上,我們首先根據前述邏輯測算得到 AI 大模型推理所需要的計算量,隨後透過單 GPU 算力供給能力、算力利用率等數值的假設,逐步倒推得到 GPU 需求數量。若以輝達當代 & 前代 GPU 卡供給各占 50% 計算,我們認為 2024-2026 年 OpenAI 雲端 AI 推理 GPU 合計需求量為 148/559/1341 萬張。
本文僅供參考,不代表我們的任何投資建議。 幻影視界 整理分享的資料僅推薦閱讀,使用者 獲取的資料 僅供個人學習,如需使用請參閱報告原文。











