作 者:於啟章
來 源:正和島(ID:zhenghedao)自從2022年11月30日那場名為「ChatGPT」的颶風席卷以來,近2年時間內,我們看到了一場人工智慧時代的「淘金熱」。
重金押註的大廠、盆滿缽滿的上遊、躍躍欲試的初創……
「誰會成為中國的OpenAI」?
今天,我們圍繞第二名講一個故事。
一、最接近OpenAI
「未來世界第二的大模型公司應該是一家中國企業。」
爭第二,這不是一個富有吸重力的故事該有的開頭,卻意外引人思考,也是閆俊傑說話的一貫風格——客觀、直白、坦誠到出人意料。
類似的表達還有很多:
「做大模型,快就是好,好就是快。」
「在探索前沿技術的道路上,最好的公司實際上是殊途同歸的。」
「實事求是地講,跟國外先進公司比起來,國內現階段所做的都是彌補差距。」
ChatGPT釋出以來的不到兩年裏,中國的大模型創業圈熱鬧到甚至有些喧囂,與此形成鮮明對比的,是很長一段時間裏「沈默」的閆俊傑。
當ChatGPT還沒釋出,其它中國公司都還沒出來,前東家眼看要上市,閆俊傑卻跳出來要做通用人工智慧的時候,他是沈默的;
當2023年下半年,投註公司80%可用資源去「死磕」MoE (混合專家系統) 模型卻連續失敗兩次,被業內審視的時候,他是沈默的;
當公司MiniMax旗下的星野、Talkie等自有產品月活數千萬,在中國甚至海外市場遙遙領先,公司估值上百億時,他依然是沈默的。
有了解MiniMax的人曾經形容,閆俊傑就像是「掃地僧」,不顯山不露水,但手上都是真功夫。

也正因此,當這樣一個人開始逐漸出現在公眾視野中的時候,難免被問及是發生了怎樣的心態轉變。
閆俊傑仍然思路清晰:「為了高效地吸引人才」,隨後又提到,「最近在辦一場活動,也讓合作夥伴和使用者更加了解我們在做的事情。」
這場活動指的是昨天剛剛結束的MiniMax Link夥伴日,任何一位對AI有所關心的人都會意識到,閆俊傑所說的溝通有多麽必要。
即便當前每天有數百萬的年輕人在「星野」與各種智慧體對話,每輪平均對話時長達到了驚人的100分鐘,即便MiniMax每天與世界發生30億次互動,是中國最接近OpenAI的公司,即便其開放平台目前已服務超 30000家企業使用者和開發者,自有產品累計使用者超過6000萬,看完這場大會,我們仍會覺得對MiniMax缺乏了一些想象力。
舉個簡單的例子,30億次互動什麽概念?
這意味著MiniMax的模型每天要處理超過3萬億的文本Token,相當於3000個人一輩子處理的文本量,更不用說這其中還包括每天生成2000萬張圖、7萬小時的語音。
這個數據處理量放在國內,大機率是所有的頭部公司裏最高甚至可以說是斷層高的,對比近期其他兩家大廠最近披露的5千到1萬億Token處理量,多出2-3倍的MiniMax可謂遙遙領先。
這不禁讓我們想起2023年的那個春節,ChatGPT「新鮮出爐」,通用人工智慧 (AGI) 概念大熱,一眾創業者摩拳擦掌,全中國的風險投資機構都在滿世界尋找「誰是中國的ChatGPT」時,卻發現MiniMax和它的Glow就已經在那兒了。
一位OpenAI的工程師曾說,他判斷一位人工智慧創業者到底有沒有真正的AGI信仰,就看這個人是在ChatGPT釋出之前創業還是在這之後。
MiniMax在ChatGPT出來之前成立,而大部份公司在這之後,這本身就是核心的區別。
只不過,隨著ChatGPT的釋出帶來「世界線收束」,閆俊傑終於不再需要跟每個人解釋他的理想了——
Intelligence with everyone,用最好的技術服務每一個人。

二、有一天,「AI不再是AI」
閆俊傑對通用人工智慧的信仰從何而來?
這是一個復雜的命題,但跟他本人聊完,答案又出乎意料的簡單。
回顧閆俊傑的履歷,先是在中科院和清華大學研究電腦視覺,又從實習生一路做到商湯副總裁、研究院副院長和智慧城市事業群CTO,接著自己創業。
做學術的時候論文在Google Scholar上有接近3萬次參照,做企業如今估值也已經上百億 (25億美元) 他好像總能勝任各種職能。
但在他自己看來,這是「被迫」的:
「過去我能做很多工作,可能跟我的成長經歷有關, 我出生在河南一個小縣城,很多東西周圍沒有人教,只能靠自己,這就形成了自己領悟事情的能力。 我也不想這樣,我是被迫變成這樣。」
也正因如此,一旦想清楚自己要做什麽,即便沒做過,閆俊傑也能快速找到一些底層邏輯。
對通用人工智慧的信仰也是如此。
事實上,閆俊傑曾提到:「我有好幾次都是想去當老師的。博士畢業後就拿了教職準備去當老師,甚至前幾年剛從商湯離開的時候本來也準備去當老師的。」
當然,這些最終都沒有發生。
因為閆俊傑意識到: 「不能再把人工智慧單純看成科學了,它更是一個技術,而且不是在遙遠的未來,就在很近的地方。」
當這種感覺一直在腦海中盤旋,並且越來越強烈,引爆,只需要一個觸點。
「有一天,我外公告訴我他想寫一本書,講自己幾十年的經歷。但他沒有辦法,因為這需要非常好的語言組織能力,還至少要會打字。
那個時候,我認為只有人工智慧可以幫他實作這件事。」

圖註:小時候的閆俊傑和外公
可是,當時的人工智慧技術非常依賴根據特殊的需求來客製模型,只能解決特定的問題,比如人臉辨識,語音辨識等。
如果一個有價值的技術只能發揮局限的價值,那一定是方法不對,或者說路線不對。
閆俊傑開始意識到,想解決這個問題,唯一辦法就是把人工智慧變得更加通用,變成普通人生活中的一部份。
「當時整個人工智慧行業遇到困境,我一直在思考什麽樣的技術進步可以給社會帶來足夠高的反饋,想到了電動車、行動網際網路,結論幾乎只有一個——要做出足夠產品化、能服務大眾的人工智慧技術和產品,而不是服務少數大客戶的計畫。」
從做人工智慧轉向做通用人工智慧,閆俊傑決定入局。
至此,MiniMax成為國內第一個說AI to C的公司,彼時,大模型這個詞甚至還沒有風靡,用簡化的語言描述可互動的智慧體,他們一度被當成是在做數位人。
現在,越來越多人開始暢想通用人工智慧真正實作的那一天,閆俊傑對這幅圖景也有一個自己的定義——
「就像我們今天談到抖音,你不會覺得它是一個基於推薦系統的內容分發軟體,你只會覺得抖音就是抖音。
什麽時候大家認為AI不是AI,那一天大概就到來了。」
三、「這是唯一的路,做不出來就完了」
今年1月,MiniMax推出了自己的abab6.5模型,是國內第一個推出MoE (混合專家系統) 架構大模型的。
形容「死磕」MoE模型,堅持做底層研發的那6個月,閆俊傑提到了「痛苦」兩個字。
很多人會問他:為什麽?有必要嗎?值得嗎?
畢竟在過去一年裏,同行大多在叠代Dense (稠密) 模型,這種模型參數固定,在推理過程中不需要進行復雜的路由選擇或專家啟用操作,有助於提高計算效率,況且結構相對簡單,易於實作和部署,開發者能輕松地將其套用到計畫中。
但它也有一個對國內企業而言致命的缺點——資源消耗大。
隨著模型規模的增大,Dense模型所需的計算資源和儲存資源也會顯著增加。
換句話說,在國內缺算力的大環境下,基於Dense不可能做出一個萬億模型,相當於直接把自己的天花板封死了。
但MoE模型不同,同樣的智慧水平,MoE模型可以用更少的計算量和記憶體需求來實作。這得益於MoE模型在套用中並非要完全啟用所有專家網路,而只需要啟用部份專家網路就可以解決相關問題,很好避免了Dense模型會出現的「殺雞用牛刀」的尷尬局面。
因此,拿出全公司80%的可用資源,耗時6個月,哪怕失敗兩次也絕對不能放棄,這不是閆俊傑在豪賭,而是他心裏清楚:
「我們不是有兩條路可以選擇,而是說為了實作目標,這是唯一的一條路,做不出來就完了。」
當被問及中途失敗兩次的時候慌沒慌過,閆俊傑也並不避諱,說不傷心不緊張那都是假的。
「模型訓了半個月,發現一些指標離前期估測的越來越遠。這就像你發了一個火箭,本來以為它可以到三萬米,但它偏航了。
你開始想哪個地方錯了,把問題解完之後,發現還沒有回到一個好的狀態,又失敗了。」
每一次燒的都是錢,比錢更重要,還有時間。
但最終,隨著模型成功研發出來,閆俊傑神奇地發現,過程中的挑戰其實並不是MoE模型本身帶來的,而是在實際操作中團隊對於實驗方法、網路、數據結構的探索存在不足。
伴隨abab6.5的誕生,一個經過淬煉的團隊也隨之形成,閆俊傑明顯感覺到整個研發部門經此一役後更高效、更科學,甚至士氣都得到了很大的提振,面對技術攻關充滿信心。
在MiniMax的企業文化裏,有一條叫做不走捷徑,聽起來簡單樸實,但這其實在對抗人性。
閆俊傑自己就說:「哪怕去年我們都還在討論要不要走私有化,模型做出來了一賣,快錢就到手了,但這很明顯是不持續的,也沒有給客戶創造真正的價值。」
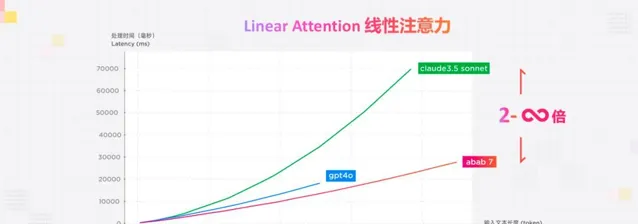
如今,更多國 內大模型創業公司開始投註資源研發MoE模型,當這成為了一個新的行業共識的時候,MiniMax已經在做更進一步的探索了。 就在昨天,MiniMax宣布,他們探索出了更難更好的Linear Attention與MOE相結合架構,這將使MiniMax的模型效率大幅提高。 其實LinearAttention架構作為開啟無限長度輸入跟無線長度輸出的一個關鍵的鑰匙,早 在2019年就被提出了,只是一直沒有人做出來。
這個架構好到什麽程度?它讓MiniMax的abab7.0模型利用國內有限的算力,達到了一個真正可以比肩GPT4o的效果。
當然,MiniMax的努力遠不止於此。
類比人,文字互動只是很小的一部份,多模態的內容,比如聲音,圖文和視訊,才是資訊傳遞的主流。
就在昨天的夥伴日上,MiniMax推出了它的第一個視訊模型,並使用一個全面的「視訊生成模型的評測框架」V-Bench進行了評測。
結果顯示,這應該是全球目前大家能用到的最好的生成模型。
不走捷徑地連 續技術突破,讓MiniMax在創新上一次又一次引領。
四、從Glow到今天, MiniMax不僅僅是賣技術的
說起AI在國內的熱潮,這並不是第一次。
實際上,這兩年熱鬧的大模型創業潮,被業內稱為「AI 2.0」。
與之對應的「AI 1.0」,指的是2015年左右開始的那一波AI創業潮,當時誕生了商湯、曠視、雲從、依圖等明星創業公司,它們以CV技術 (電腦視覺) 為主導,大量融資,風頭無兩。這四家公司,是公認的「AI四小龍」。
「AI四小龍」當年也從投資人手中拿了很多錢,但最後卻沒有從市場上賺到多少錢。
這不是因為它們技術不好,而是商業化很難,客戶主要是B端企業和G端政府,透過提供人臉辨識等AI解決方案來賺錢。
這顯然不是一個好的商業模式,計畫非標準化、落地周期長、成本高,導致後來一提到「AI四小龍」,人們總是會想到虧損、燒錢等標簽。
如今的大模型創業公司,同樣要面對來自商業化的拷問。
這一點,閆俊傑也想得很實際,那就是 一定要在技術快速前進演化的視窗關閉前,做出使用者量巨大的2C產品。
「如果沒有產品承接,即使你有一個技術進展,它最終也不是你的。」
說白了,一味地秀肌肉作用不大,能用它搬起磚、蓋起樓、讓使用者住進去才是正道。
閆俊傑說到做到。
如今,MiniMax是中國大模型創業公司中做產品最早、最多,投入也最大的一家:
MiniMax如今300-400人,其中一半以上是技術團隊,另有40%負責產品。 他們的第一款產品Glow上線於2022年10月,之後又陸續推出了星野、海螺AI等至少4個產品,既有AI內容社群套用,也有問答等生產力套用,多個套用的日活使用者已突破100萬,每天與世界互動30億次。
對於大模型創業公司,李彥宏有個經典的觀點,他認為「雙輪驅動」,即同時做模型和套用不是個好模式,很多人也拿這句話來考驗過閆俊傑。
他實事求是:「一開始創業其實沒資格想這些事,因為你既沒有技術又沒有產品也沒有使用者。前六七個月只是把最原始的模型做出來,才有了後面的產品。」
但是產品要不要做?
必須做。
這就不得不提到MiniMax的另一條企業文化:User-in-the-loop,與使用者共創。
閆俊傑很清醒:「我一直不認為AGI會像一個原子彈、一個大殺器,它就是普通人每天會用的一個產品、一個服務——這也是我們最堅持的。
這也就意味著AGI也不應該是一家公司自己做出來,它要靠這家公司和它的使用者一起做出來。」
實際上也不難理解,當MiniMax的願景是讓好的技術服務每一個人的時候,不去研發產品,不去接受一手的使用者反饋,似乎才是荒謬的。
只是,好的產品,好的使用者體驗究竟從何而來?
行動網際網路時代流行過一個口號,叫做「人人都是產品經理」,產品的設計和使用者的需求推到至高無上的地位,大模型時代會繼承這一點嗎?
MiniMax也曾糾結過,產品和技術同時做,都重要,但哪個才是核心?
最終,閆俊傑在公司成立一年多時將新的四個字加入企業文化——技術驅動。
至此,塵埃落定。
背後緣由,也來自一次慘痛經歷。
2022年底,MiniMax團隊幾乎全員感染新冠,結果最後一次發版裏出現了一個bug,把使用者的對話體驗拉低了15%左右。
僅元旦三天,產品的日活躍使用者直接掉了40%,大家焦頭爛額,終於在放假最後一天找到了那個bug,非常小的一行演算法,改好之後使用者量很快就回來了。
這個事讓閆俊傑意識到,現階段產品價值的來源,核心還是模型效能和演算法能力,不然設計再多產品特性,提升都是有限的。
而在本次夥伴日大會上,MiniMax基於MOE+Linear Attention的abab7模型家族的預熱釋出,更是讓他們對於技術驅動的堅持再次得證。
行勝於言。

圖註:MiniMax成立第一天寫下的初心和藍圖
五、結語
如果我們來總結MiniMax的發展之路,這無疑是一場田忌賽馬的勝利。
「在整體資源劣勢的情況下,創造出局部的優勢,進而有機會獲得整個戰役的勝利。由此,平凡人可以成就非凡事。」
在行動網際網路爆發初期,人們熱衷於談論那些天才的產品設計 (比如微信) 和它背後的美學甚至哲學理念。
但到了大模型人工智慧階段,產品設計的邏輯變了——
在由技術驅動的底層之上,使用者開始在內容上深度共創,他們的使用同時反哺著產品本身前進演化。
率先領悟的,率先成長 。
我們都在遙望通用人工智慧的曙光,MiniMax已經踏入河流。
排版 | 微瀾 編輯 | 張啟玉 執行 主編 | 夏昆










