編輯:Lumina
【新智元導讀】 近期微軟的高層人員調動以及新工具的推出,可能暗示著其AI戰略的轉向。
微軟已經有一段時間沒有向外界透露任何有關 GenAI 的訊息了。
在減少對OpenAI技術依賴的過程中,GenAI 本該是微軟的重要戰略,但科技媒體The information了解到的微軟組織變革表明:
微軟在自主開發和訓練生成式人工智慧上遇到了瓶頸。
而同期微軟推出的AI相關的新工具,也佐證了其在生成式人工智慧業務上的戰略轉向。

前途未蔔的合成數據與蒸餾模型
今年的早些時候,微軟似乎在對先前內部的一個名為「蒸餾」計畫加倍投註。
這個計畫的內容大致為先使用OpenAI的模型生成大量數據,然後再利用這些數據來訓練類似ChatGPT的模型。
微軟的目標是讓這些模型在某些任務上幾乎能達到與OpenAI模型相同的表現,這樣微軟就可以根據自身的需要,對自己開發的模型進行「公平市場價格」的定價和自由出售。
在人工智慧的開發中,業內幾乎都會使用某種形式的人工智慧生成的訓練數據,即合成數據。

作為OpenAI的主要資助者,微軟擁有充分的自由來使用OpenAI的模型。
因此,微軟的研究人員能夠要求GPT-4生成數百萬段與教科書品質類似的文本段落,包括文章和教科書風格的練習,這些練習附有解釋的問答內容。
隨後,微軟便可以利用這些數據來訓練一個較小但其效能表現與GPT-4相似的模型。
而大約從一年前開始,微軟就透過提煉OpenAI的模型開發了Phi。
Phi不僅開源,執行成本也更低。
微軟研究人員在他們的論文中表示,雖然Phi的規模要小得多,但其效能幾乎可以與OpenAI的主要旗艦模型相媲美。
微軟CEO納德拉將Phi形容為微軟在AI領域「掌握自己命運」的一種方式。
他向股東們表示,Phi在Azure上與投資公司貝萊德、阿聯航空以及醫療軟體公司Epic等客戶進行了合作。
在某些情況下,特別是當問題相對簡單、不需要復雜解答時,微軟用Phi替代了OpenAI 的模型, 例如在Bing等產品中取代GPT-4作為AI聊天機器人。
在Phi初步成功之後,今年一月,微軟將負責Phi的首席研究員Sébastien Bubeck從微軟研究部門調往一個專註於構建蒸餾模型的新組織。
同年三月,微軟以6.5億美元的協定聘請了Inflection的CEO 穆Mustafa Suleyman並讓他負責公司的消費者AI業務後,Bubeck被調到了蘇萊曼所管理的微軟AI團隊。
據兩位知情人士稱,他負責的是使用OpenAI的大型模型來生成訓練數據。
然而,最近Bubeck已從Suleyman的團隊離職,重新回到微軟研究部門,並再次向研究主管Peter Lee匯報工作。
而在八月,負責將Phi模型添加到Azure和其他微軟產品中的 Misha Bilenko 也離職前往了谷歌的DeepMind AI團隊。
一位微軟AI研究員認為,這些突如其來的人員變動可能表明,Suleyman將不再把合成數據和蒸餾視為部門的發展方向以及微軟的首要目標。
另一方面,今年五月被寄予期望的大型模型MAI-1毫無訊息,且Suleyman團隊之後也再也沒有公開釋出過任何模型的情況,也佐證了這一戰略轉向。
微軟現如今依然要依靠OpenAI的模型來支持自己的人工智慧服務,據一些金融機構的預測,微軟今年有望在Azure上透過轉售OpenAI的模型獲得超10億美元的收入。
值得在意的是,微軟近期推出了一項在Azure AI上的新服務——
「校正」:人工智慧幻覺的糾正工具
現階段阻礙生成式人工智慧在現實中更廣泛地套用落地的最大缺陷,就是「幻覺」(hallucinations)。
幻覺是指缺乏基礎數據支持的內容的生成,輸出誤導性的資訊。
這種現象尤其與大型語言模型( LLMs )相關。
在醫學、自動駕駛等高風險領域,準確的資訊至關重要。
雖然人工智慧有潛力改善對重要資訊的獲取,但幻覺可能會導致誤解,造成嚴重的後果。
雖然業內可以透過「過濾」來解決幻覺問題,但這種方法在輸出的文本因內容被刪減或遮蔽而變得不連貫時,會導致使用者體驗不佳。
而微軟認為,在Azure AI內容安全的接地檢測(groundedness detection)中引入的一項新功能——校正(correction),能夠突破上述局限。
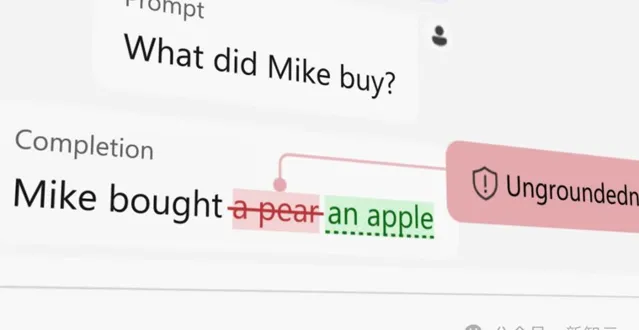
今年三月,微軟在Azure AI引入了接地檢測。它能夠將人工智慧的輸出與原文件進行比較,以辨識生成過程中的幻覺內容。
但在使用者實際體驗這項服務的過程中,一個疑問也隨之產生:「對這些檢測到的幻覺內容除了遮蔽之外,我們還能做什麽?」
為了解決這個問題,微軟在接地檢測中引入了校正功能,讓使用GenAI程式的使用者能夠 遇到幻覺之前, 即時辨識和糾正幻覺。
但校正的運作,需要程式連線到用於文件摘要和給予RAG的接地文件。
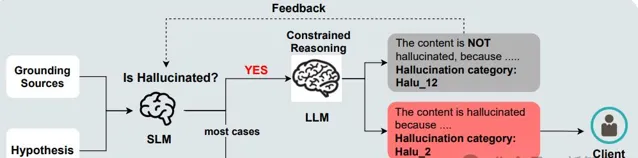
之後,Azure AI上的接地檢測將透過以下幾步執行:
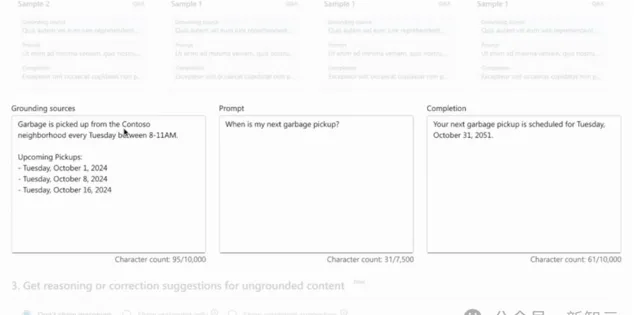
檢測: 首先,Azure AI內容安全會掃描AI生成內容中的無根據部份。
幻覺現象並不是一個完全有或完全無的問題,大多數無根據的輸出實際上也包含了一些有根據的內容。
這就是為什麽有根據性檢測可以精確找到無根據內容的具體部份。
當無根據的內容被辨識出來後,模型會高亮顯示具體不正確、不相關或虛構的文本。
推理: 在辨識出無根據的段落後,模型會生成解釋說明,說明為什麽某些文本被標記。
這種透明性非常重要,因為它可以讓使用者明確無根據的點,並評估其不接地的嚴重性。

修正: 一旦無根據的內容被標記,系統會即時啟動覆寫過程。被標記為不準確的部份會被修改,以確保與相關資料來源保持一致。
但如果該句子缺少任何與基礎檔相關的內容,則可能會被完全過濾掉。
而在使用者看到最初的無根據內容之前,修正就已經完成。
輸出: 最後,修正後的內容將返回給使用者。
但微軟強調,該工具提高的是人工智慧生成的內容和源材料之間的一致性,它並不能保證生成的內容可以到達完美的準確性。
畢竟最根本的是數據來源的真實性和客觀性。或許,這也是微軟決定內部戰略轉向的原因。
而在構建值得信賴的人工智慧的道路上,業界的開發者們還需要更多不同的嘗試。
參考資料:
https://the-decoder.com/microsoft-unveils-ai-hallucination-correction-tool/











