夢晨 發自 凹非寺
量子位 | 公眾號 QbitAI
OpenAI前首席科學家、聯合創始人Ilya Sutskever
曾在多個場合表達觀點:
只要能夠非常好的預測下一個token,就能幫助人類達到通用人工智慧(AGI)。
雖然,下一token預測
已在大語言模型領域實作了ChatGPT等突破,但是在多模態模型中的適用性仍不明確
。多模態任務仍然由擴散模型(如Stable Diffusion)和組合方法(如結合 CLIP視覺編碼器和LLM)所主導。
2024年10月21日,智源研究院
正式釋出原生多模態世界模型Emu3
。該模型只基於下一個token預測,無需擴散模型或組合方法,即可完成文本、影像、視訊三種模態數據的理解和生成。
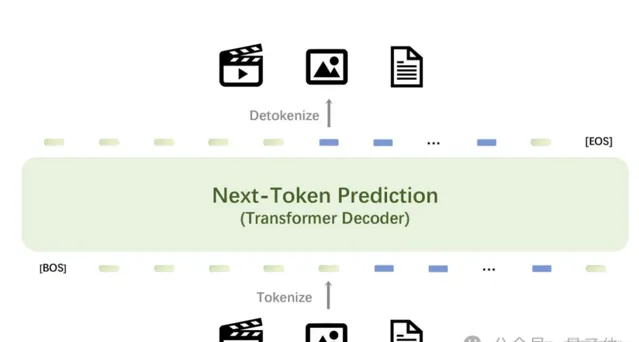
Emu3在影像生成、視訊生成、視覺語言理解
等任務中超過了SDXL 、LLaVA、OpenSora等知名開源模型,但是無需擴散模型、CLIP視覺編碼器、預訓練的LLM
等技術,只需要預測下一個token
。
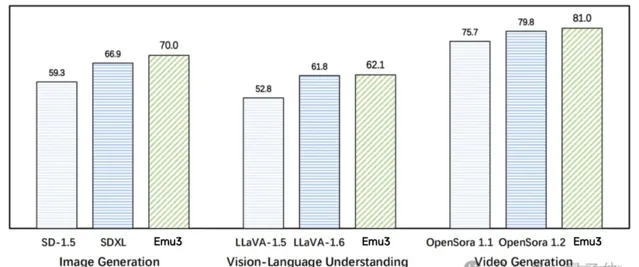
圖註:在影像生成任務中,基於人類偏好評測,Emu3優於SD-1.5與SDXL模型。在視覺語言理解任務中,對於12 項基準測試的平均得分,Emu3優於LlaVA-1.6。在視訊生成任務中,對於VBench基準測試得分,Emu3優於OpenSora 1.2。
Emu3提供了一個強大的視覺tokenizer
,能夠將視訊和影像轉換為離散token。這些視覺離散token可以與文本tokenizer輸出的離散token一起送入模型中。與此同時,該模型輸出的離散token可以被轉換為文本、影像和視訊,為Any-to-Any
的任務提供了更加統一的研究範式。而在此前,社群缺少這樣的技術和模型。
此外,受益於Emu3下一個token預測框架的靈活性,直接偏好最佳化
(DPO)可無縫套用於自回歸視覺生成,使模型與人類偏好保持一致。
Emu3研究結果證明,下一個token預測可以作為多模態模型的一個強大範式,實作超越語言本身的大規模多模態學習,並在多模態任務中實作先進的效能
。透過將復雜的多模態設計收斂到token本身,能在大規模訓練和推理中釋放巨大的潛力。下一個token預測為構建多模態AGI提供了一條前景廣闊的道路。
目前Emu3已開源了關鍵技術和模型
。(開源模型和程式碼地址在文末)
Emu3一經上線便在社交媒體和技術社群引起了熱議。
有網友指出,「這是幾個月以來最重要的研究,我們現在非常接近擁有一個處理所有數據模態的單一架構。」
「Emu3 是一種非常新穎的方法(至少在我看來是這樣),它有機會將多模態合並為一,只需將它們都視為token即可。雖然還處於初期,但演示效果很不錯。想象一下,我們可以無限擴充套件視訊和生成多種模態。」

甚至有網友評價:「也許我們會得到一個真正開放的 OpenAI v2?」
對於Emu3的意義和影響,有評論指出:「Emu3 將徹底改變多模態AI領域,提供無與倫比的效能和靈活性。」
「Emu3在各行各業的廣泛適用性和開源靈活性將為開發者和企業解鎖人工智慧創新能力的機會。」

「對於研究人員來說,Emu3意味著出現了一個新的機會,可以透過統一的架構探索多模態,無需將復雜的擴散模型與大語言模型相結合。這種方法類似於transformer在視覺相關任務中的變革性影響。」
「Emu3的統一方法將帶來更高效、更多功能的AI系統,簡化多模態AI的開發和套用以及內容生成、分析和理解的新可能性。」
「Emu3 覆寫了多模態人工智慧的規則…Emu3 重新定義了多模態AI,展示了簡單可以戰勝復雜。多模態AI的未來變得更加精煉與強大。」

效果展示
1. 視覺理解
Emu3 展現了強大的影像及視訊的感知能力,能夠理解物理世界並提供連貫的文本回復。值得註意的是,這種能力是在不依賴於基礎LLM模型和CLIP的情況下實作的。
1.1 影像輸入




1.2 視訊輸入

2. 影像生成
Emu3透過預測下一個視覺token來生成高品質的影像。該模型自然支持靈活的分辨率和不同風格。
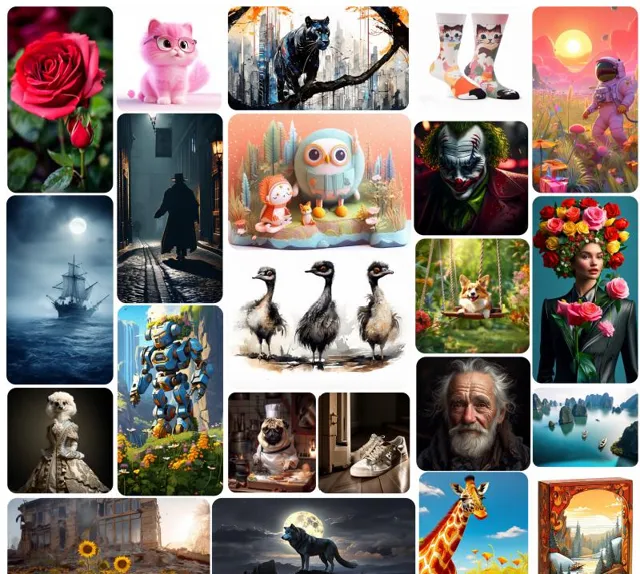
3. 視訊生成
與使用視訊擴散模型以從雜訊生成視訊的Sora不同,Emu3只是透過預測序列中的下一個token來因果性的生成視訊。
4. 視訊預測
在視訊的上下文中,Emu3可以自然地擴充套件視訊並預測接下來會發生什麽。模型可以模擬物理世界中環境、人和動物。
Emu3技術細節
1 數據
Emu3是在語言、影像和視訊混合數據模態上從頭開始訓練的。
語言數據:
使用與Aquila模型相同的語言數據,一個由中英文數據組成的高品質語料庫。
影像數據:
構建了一個大型影像文本數據集,其中包括開源網路數據、AI生成的數據和高品質的內部數據。整個數據集經過了分辨率、圖片品質、型別等方面的過濾過程。訓練了一個基於Emu2的影像描述模型來對過濾後的數據進行標註以構建密集的影像描述,並利用vLLM庫來加速標註過程。
視訊數據:
收集的視訊涵蓋風景、動物、植物和遊戲等多個類別。
整個視訊處理流程包括了場景切分、文本過濾、光流過濾、品質評分等階段。並使用基於影像描述模型微調得到的視訊描述模型來對以上過濾後的視訊片段打標文本描述。
2 統一視覺Tokenizer
在SBER-MoVQGAN的基礎上訓練視覺tokenizer,它可以將4×512×512的視訊片段或512×512的影像編碼成4096個離散token。它的詞表大小為32,768。Emu3的tokenizer在時間維度上實作了4×壓縮,在空間維度上實作了8×8壓縮,適用於任何時間和空間分辨率。
此外,基於MoVQGAN架構,在編碼器和解碼器模組中加入了兩個具有三維摺積核的時間殘留誤差層,以增強視訊token化能力。
3 架構
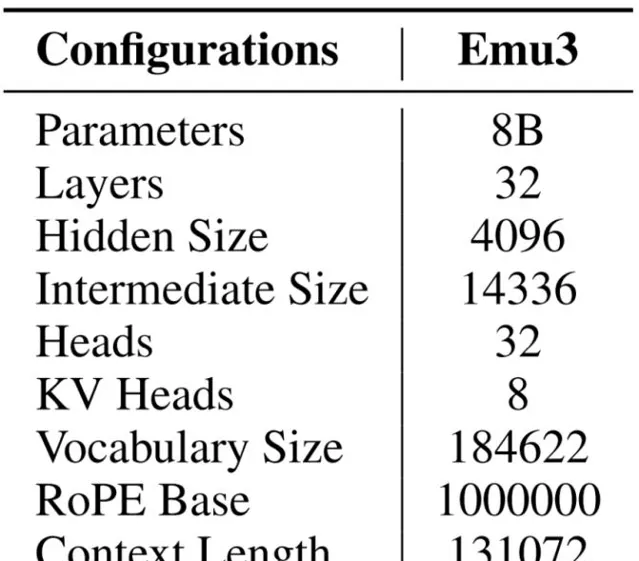
Emu3保留了主流大語言模型(即 Llama-2)的網路架構。不同點在於,其擴充套件了Llama-2架構中的嵌入層,以容納離散的視覺token。網路中使用RMSNorm進行歸一化。其還使用了GQA註意力機制、SwiGLU啟用函式和一維旋轉位置編碼(RoPE)等技術,並並去除了註意力模組中QKV層和線性投影層中的偏置。此外,還采用了0.1的dropout率來提高訓練的穩定性,使用QwenTokenizer對多語言文本進行編碼。詳細架構配置表。
4 預訓練
在預訓練過程中,首先要定義多模態數據格式。與依賴外部文本編碼器的擴散模型不同,Emu3 原生整合了用於生成影像/視訊的文本條件資訊。在視覺和語言的固有token中新增了五個特殊token來合並文本和視覺數據,以為訓練過程建立類似文件的輸入。生成的訓練數據結構如下:
[BOS] {caption text} [SOV] {meta text} [SOT] {vision tokens} [EOV] [EOS]其中,[BOS]
和 [EOS]
是QwenTokenizer中的原始特殊token 。
額外新增的特殊token包括:
[SOV]
表示視覺輸入(包含影像和視訊的meta資訊部份)的開始
[SOT]
表示視覺token的開始
[EOV]
表示視覺輸入的結束。
此外,特殊token [EOL]
和 [EOF]
作為換行符和換幀符插入到了視覺token中。元文本包含影像的分辨率資訊,視訊則包括分辨率、幀率和持續時間,均以純文本格式呈現。在構建理解數據時,Emu3將部份數據中的 「caption text」欄位移至[EOV] token之後。
訓練目標:
由於 Emu3 中的視覺訊號已完全轉換為離散token,因此只需使用標準的交叉熵損失進行下一個token預測任務的訓練。為了防止視覺token在學習過程中占據主導地位,對與視覺token相關的損失加權 0.5。
訓練細節:
Emu3 模型在預訓練期間利用非常長的上下文長度來處理視訊數據。 為便於訓練,采用了張量並列(TP)、上下文並列(CP)和數據並列(DP)相結合的方法。同時將文本和影像數據打包成最大上下文長度,以充分利用計算資源,同時需要確保在打包過程中不會分割完整的影像。
預訓練過程分為兩個階段,第一階段不使用視訊數據,訓練從零開始,文本和影像數據的上下文長度為 5,120;在第二階段,引入視訊數據,並使用 131,072 的上下文長度。
5 SFT階段
5.1 視覺生成
品質微調:
在預訓練階段之後,對視覺生成任務進行後訓練,以提高生成輸出的品質。使用高品質數據進行品質微調。
直接偏好最佳化:
Emu3在自回歸多模態生成任務中采用直接偏好最佳化(Direct Preference Optimization,DPO)技術,利用人類偏好數據來提高模型效能。
5.2 視覺語言理解
預訓練模型經過兩個階段的視覺語言理解後訓練過程:1) 影像到文本的訓練以及 2) 指令調整。
第一階段:
將影像理解數據與純語言數據整合在一起,而與視覺token相關的損失則在純文本預測中被忽略。
第二階段:
利用 LLaVA 數據集中的約 320 萬個問答對進行指令微調。低於 512 × 512 或高於 1024 × 1024 的圖片將被調整到較低或較高的分辨率,同時保持相應的長寬比,而其他圖片則保持原始分辨率。
開源地址
除了先前經SFT的Chat模型和生成模型外,智源研究院還在近日開源了Emu3生成和理解一體的預訓練模型以及相應的SFT訓練程式碼
,以便後續研究和社群構建與整合。
程式碼:https://github.com/baaivision/Emu3
計畫頁面:https://emu.baai.ac.cn/
模型:https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
未來方向
Emu3為多模態AI指出了一條富有想象力的方向,有機會將AI基礎設施收斂到單一技術路線上,為大規模的多模態訓練和推理提供基礎。統一的多模態世界模型未來有廣泛的潛在套用,包括自動駕駛、機器人大腦、智慧眼鏡助手、多模態對話和推理等。預測下一個token有可能通往AGI。











