編輯:編輯部
【新智元導讀】 MoE已然成為AI界的主流架構,不論是開源Grok,還是閉源GPT-4,皆是其擁躉。然而,這些模型的專家,最大數量僅有32個。最近,谷歌 DeepMind 提出了全新的策略PEER,可將MoE擴充套件到百萬個專家,還不會增加計算成本。
如果你熟悉當前LLM的主流架構,混合專家(MoE)技術想必是老朋友之一。有人甚至會說,MoE是使大模型崛起的關鍵因素之一。
開源的Mixtral、DBRX、Grok等模型都使用了MoE,而且根據 Soumith Chintala 等大佬的推測,GPT-4也是一個規模為8×220B的MoE模型。

類似GPT-4,多數MoE模型都會將專家數量限制在較少數量,一般不會超過16或32。
然而,DeepMind研究科學家Xu Owen He最近就在一篇獨立發表的論文中,提出了一種全新的方法—— PEER(參數高效專家檢索,Parameter Efficient Expert Retrieval) ,可以將專家數量擴充套件到百萬數量級。

論文地址:https://arxiv.org/abs/2407.04153
這究竟是如何做到的?參數量不會爆炸嗎?不會造成收益遞減嗎?如何實作能在百萬個專家中實作高效檢索?
背景與介紹
Transformer架構中,每個塊內都包含註意力層和前饋層(FFW),註意力層用於計算序列中token之間的關系,FFW網路則負責儲存模型知識。
我們當然希望LLM能在參數中隱式儲存更多知識,但FFW的計算成本和啟用記憶體會隨之線性增加。稠密模型中,FFW層已經占據了總參數量的2/3,是擴充套件的主要瓶頸之一。
MoE模型雖然參數量也很大,但每次推理時不會動用整個模型的能力,而是將數據路由到小型且專門的「專家模組」,因此能在LLM參數增加的同時,讓推理所需的計算成本基本不變。
那麽專家數量(即MoE模型的「粒度」)是不是越多越好?
這要考慮多個因素,包括模型參數總量、訓練token數量和算力的預算。
2022年的一項研究認為,模型總參數量不變時,存在一個能達到最優效能的「最佳粒度」。專家數量超過這個與之後,模型效能就會進入「平台期」。
Unified Scaling Laws for Routed Language Models
論文地址:https://arxiv.org/pdf/2202.01169
然而,今年年初Krajewski等人發表的一篇論文反駁了這個觀點。他們發現,如果同時增加訓練所用的token數量,那麽更高粒度可以提高效能。

論文地址:https://arxiv.org/pdf/2402.07871
受到這種細粒度MoE Scaling Law的啟發,作者推斷,模型容量的持續改進將帶來具有高粒度的LLM,即包括大量微型專家的模型。
除了能帶來更高效的擴充套件,增加專家數量還有另外一層好處——終身學習。
之前有研究表明,透過簡單地添加新專家並進行適當正則化,MoE模型就可以適應連續的數據流。凍結舊專家、僅讓新專家權重更新,就可以在保持可塑性的同時防止災難性遺忘。
在終身學習環境中,數據流可能達到無限長度,甚至永無止境,因此論文探索的專家數量的擴大就顯得十分重要。
百萬MoE所系
PEER層設計
形式上,PEER可以表達為函式 ,包含如下三部份:
- N個專家組成的專家池,其中每個專家e
i
和f有相同的函式簽名
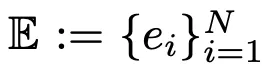
- 一組相應的N個乘積鍵

- 用於將輸入向量x對映到查詢向量q(x)的查詢網路

用𝒯 𝑘 表示top-k運算子,給定輸入x,從N個專家中檢索到k個專家的過程可以表示為:

之後使用 softmax 或sigmoid等啟用函式套用於top-k個專家的查詢-鍵內積,獲得路由分數:

最後,計算路由分數加權的專家分數之和,作為PEER層輸出。

上述的PEER層可以插入到Transformer架構骨幹的中間,或者代替FFW層,整體計算流程如圖2所示。
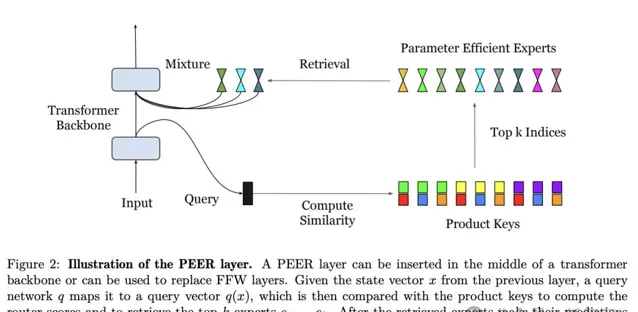
PEER層示意圖
乘積鍵檢索
由於要使用非常多的專家(N≥10 6 ),直接計算公式1中的前k個指標可能會非常耗費資源。
為此,研究人員提出了乘積鍵檢索技術——透過連線來自兩個獨立d/2維的子鍵C和C′(C, C′ ⊂ R d/2 )的向量來進行建立:
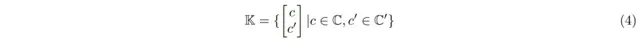
這種K的笛卡爾積結構,能夠高效地找到前k位專家。
也就是,先將查詢向量q(x)拆分為兩個子查詢q1和q2,並分別對子查詢與子鍵之間的內積進行前k個操作:

然後得到一組k
2
候選鍵集合,
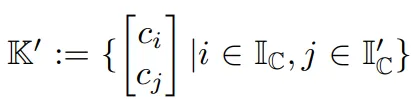 ,在數學上,這可以保證從K中與q(x)最相似的k個鍵在這個候選集合中。
,在數學上,這可以保證從K中與q(x)最相似的k個鍵在這個候選集合中。
此外,候選鍵與q(x)之間的內積只是子鍵與子查詢之間內積的總和: 。
因此,可以再次將前k個操作套用於這k的平方個內積,以從原始的乘積鍵集合K中獲得前k個匹配鍵。
最終,公式1中透過窮舉搜尋進行的top-k專家檢索的復雜度,從O(N·d)降到了O((√N + k 2 )d)。
參數高效專家和多頭檢索
通常的MoE架構中會將專家隱藏層設計為FFW層相同大小,但PEER中的每個專家e i 則小得多,僅僅是包含一個神經元、一個隱藏層的單例MLP:

其中v i 、u i 都不是參數矩陣,而是與x維度相同的向量,𝜎表示ReLU或GELU等啟用函式。
每個專家只有如此少的參數,怎麽可能有強大的表達能力?
此處,作者借鑒了多頭註意力的做法,使用了「多頭檢索」(multi-head retrieval)機制。
也就是說,查詢過程並不是僅有一次,而是使用h個獨立的查詢網路,分別計算自己的查詢向量並檢索出一組top-k專家,但他們共享相同的專家池和每個專家的乘積鍵。
h個「檢索頭」的輸出相加後得到最終檢索結果:
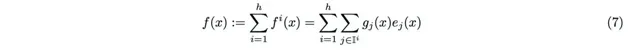
可以證明,當每個頭只檢索一名專家時(k=1),使用含h個檢索頭的PEER層,等效於使用含有h個神經元的專家。
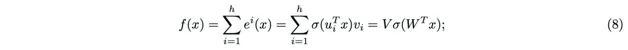
這就意味著,這種多頭檢索的過程相當於動態組裝出含有h個神經元的專家MLP網路。
與現有MoE中多個專家之間完全隔離的狀態相比,這種設計允許專家間共享隱藏神經元,從而提升了參數效率和知識遷移的能力。
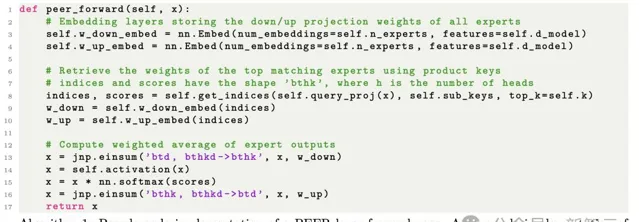
演算法1描述了PEER前向計算的簡化實作。要想達到高效的實作,可能還需要專門的硬體內核來加速embedding尋找,以及與einsum操作的融合。
為什麽用大量的小專家
論文的背景介紹中,我們從直覺和經驗層面推匯出使用大量專家的優點,但作者也在此處用公式推導的方法證明了這一點。
首先,我們可以用3個超參數列征MoE層的設定:參數總量P、每個token啟用的參數P active 以及單個專家的大小P expert 。
之前提及的,Krajewski論文中提出的「細粒度MoE Scaling Law」就可以用這三個參數列示為如下形式:
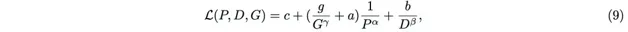
其中,L表示損失值,D是訓練token總量,G是啟用專家的數量,a、b、g、α、β、γ等字母都表示常量。
為了降低損失值、提高模型效能,我們需要提升P、D、G的值,同時也需要限制 P active 的大小,因為計算和記憶體成本主要由啟用參數量決定。
值得註意的是, P active 對應的記憶體占用也和batch中的token數量有關,但與batch大小或序列長度無關,因為在處理batch或序列的每個token時只需要儲存模型的一份副本。
由於專家大小 P expert = P active /G,因此專家數量N=P/P expert =P·G/ P active 。
這就意味著,如果想要在增加P、G的同時保持 P active 不變,就應該減小專家大小 P expert ,並增加專家數量N。
這就解釋了,我們為什麽需要大量的小專家。
一般來說,對於只有單個隱藏層的專家模型,其參數大小為:P expert =(2d model +1)d expert ,相應地, P active =(2d model +1)d active 。
其中d model 、d expert 、d active 分別表示表示Transformer的隱藏維度、單個專家的隱藏神經元數量以及每個token啟用的參數總量。
PEER中使用了盡可能小的專家大小,即d expert =1,因此最大程度地降低了d active ,大小僅為檢索頭數量乘以每次檢索的專家數量(h·k)。
實驗
預訓練isoFLOP分析
作者使用isoFLOP分析將PEER與各種基線方法進行了比較。
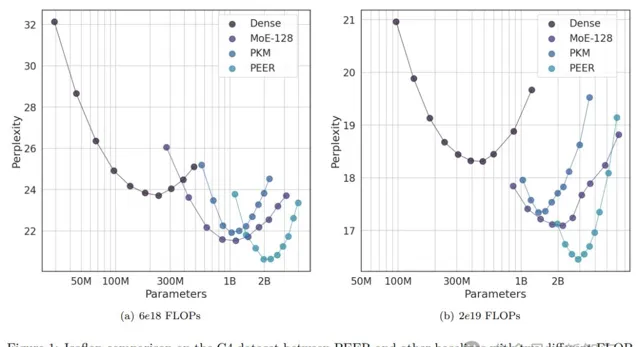
這裏,他選擇了固定的FLOP預算(6e18和2e19),並同時改變模型大小和來自C4數據集的訓練token數,以獲得isoFLOP曲線。
isoFLOP曲線上的每個點,都具有相同的計算成本,作者根據其模型大小和在C4上的最終驗證困惑度(perplexity),來繪制這些點。
對於密集基線模型,透過改變層數、註意力頭數和模型維度來改變它們的大小。
對於MoE、PKM和PEER方法,作者選取了每個考慮的密集模型,並分別用MoE、PKM和PEER層,替換中間塊中的FFN層(例如,在12塊Transformer中,替換第6塊中的FFN)。
在MoE中,作者使用了專家選擇路由演算法。該演算法有效地解決了專家負載不平衡問題,並且通常優於token選擇MoE。
每個專家的大小與相應密集模型中原始MLP的大小相同,作者使用了128個專家來覆蓋與PEER模型相同的模型大小範圍。
這種型別的MoE代表了標準的粗粒度方法,由少量大型專家組成。
在PKM中,作者使用了1024×2個儲存器,8個頭,每個頭選擇32個記憶體(top k=32)。
此外,研究者還套用了查詢批次歸一化,這是原始PKM論文中推薦的,用於提高記憶使用率。
在PEER中,同樣使用了10242個專家,8個頭,每個頭選擇16個記憶體(top k=16)。
預設情況下,作者也啟用了查詢批歸一化(BatchNorm)來增加專家使用率。與專家選擇MoE基線不同,PEER代表了一種細粒度方法,使用了大量小型專家。
在所有模型大小和方法中,保持了一致的批大小(128)和序列長度(2048)。透過將總計算預算除以每個訓練步驟的FLOP來計算訓練步驟數。
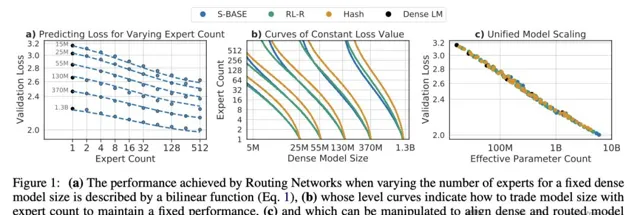
圖1展示的是isoFLOP曲線。
與密集FFW基線相比,稀疏替代方案使isoFLOP曲線向下和向右移動,因為其引入了更多的總參數P,但使用了更少或相同數量的活躍參數P active 。
另外,在相同的計算預算下,PEER模型達到了最低的計算最佳化困惑度。
語言建模數據集評估
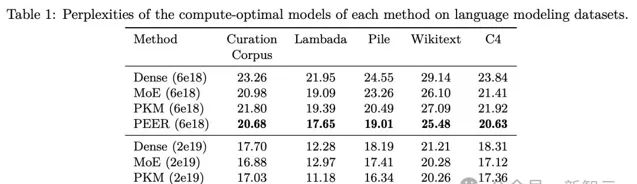
根據isoFLOP曲線確定每種方法的計算最優模型後,研究人員在幾個流行的語言建模數據集上評估了這些預訓練模型的效能,包括Curation Corpus、Lambada、the Pile、 Wikitext 和預訓練數據集C4。
評估結果如表1所示,作者根據模型在訓練期間使用的FLOP預算將其分組。
消融實驗
改變專家總數
圖1中isoFLOP圖所示的模型都有超過一百萬(10242)個專家。
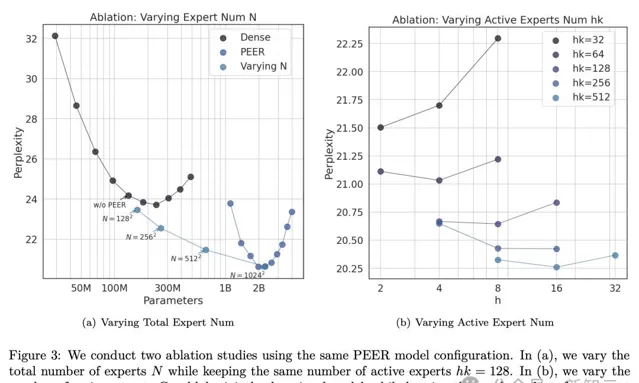
接下來,研究者進行了一項消融研究,研究專家數量N的影響,N決定了等式9中的總參數數量P。
作者選擇了isoFLOP最優模型,並改變PEER層中的專家數量(N = 1282, 2562, 5122, 10242),同時活躍專家的數量不變(h = 8, k = 16)。
實驗結果如圖3(a)所示,可以看出,isoFLOP曲線在10242個專家的PEER模型和相應的密集骨幹模型(未將中間塊的FFW層替換為PEER層)之間進行插值。
這表明,僅僅增加專家數量,就可以提高模型效能。
改變活躍專家的數量
另外,作者還對活躍專家hk數量進行了消融研究,hk等同於等式9中的粒度G。
他系統地改變了活躍專家的數量(hk = 32, 64, 128, 256, 512),同時保持專家總數不變(N = 10242)。
此外,對於給定的hk,同時改變h和k以找到最優組合。結果中的isoFLOP曲線,以頭(h)數為橫軸繪制,如圖3(b)所示。
結果表明,在考慮的數值範圍內,更高的h·k值通常會帶來更好的效能。
值得註意的是,隨著h·k的增加,最優的h也在增加。然而,效能逐漸趨於飽和,增加活躍專家的數量也會增加裝置記憶體消耗,可能需要額外的加速器裝置。
因此,在實際套用中,應該根據效能、裝置數量和計算資源需求之間的權衡來選擇適當的h·k值。
專家使用和查詢批歸一化
由於PEER層中有超過一百萬個專家,對於許多人來說,一定好奇其在推理過程中實際選擇了多少專家?它們的使用是否均勻分布?
為了分析這點,研究者在C4驗證集的所有token中,為每個專家e i 保留一個累積的路由分數(router score),表示為: 。
其中,g i (x)是指當token x作為輸入時用於聚合專家輸出的路由分數。如果專家e i 未被選中,則g i (x)=0。
從這些累積的路由分數中,可以獲得一個經驗機率分布向量,表示為 。
代表C4驗證集上所有專家的分布。
然後,作者計算了Lample等人提出的以下指標來評估專家的使用情況和分布:
- 專家使用:推理過程中檢索到的專家比例:
- 不均勻性:z與均勻分布之間的KL散度
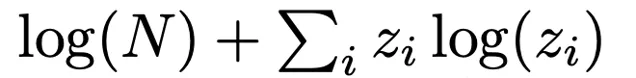
其中,N是專家總數。
預設設定下,作者在查詢網路上添加了一個批歸一化(BN)層,目的是增加訓練過程中的專家使用率。
對此,他研究添加這個BN層對上述指標的影響。
表2展示了不同專家數量下的專家使用和不均勻性,包括使用和不使用BN的情況。
可以看到,即使對於100萬個專家,專家使用率也接近100%,而使用BN可以導致專家的使用更加平衡,並降低困惑度。
這些發現證明了,PEER模型在利用大量專家方面的有效性。

最後,作者還比較了有和沒有批歸一化(BN)的isoFLOP曲線。
如下圖4所示,使用BN的PEER模型通常能達到更低的困惑度。雖然差異不是很顯著,但在isoFLOP最有區域附近最為明顯。

作者介紹

Owen He是Google DeepMind的研究科學家,專註於持續學習和基礎模型。
在加入DeepMind之前,Owen是在格羅寧根大學和不來梅雅各布大學(康斯特大學)攻讀博士學位,導師是 Herbert Jaeger。
在此期間,Owen存取過Mila、馬克斯·普朗克研究所、伯恩大學和蘇黎世聯邦理工學院,並在Google DeepMind進行過實習。
他曾組織過ICML 2021持續學習研討會,目前擔任Conference on Lifelong Learning Agents的出版主席。

參考資料:
https://arxiv.org/abs/2407.04153
https://venturebeat.com/ai/deepminds-peer-scales-language-models-with-millions-of-tiny-experts/











