文 | 思辨財經
自2022年11月ChatGPT問世,這一現象級產品迅速點燃了市場的大模型熱情。新老科技企業紛紛殺入,誓要抓住流動互聯網以來最大的一次產業紅利。當行業如火如荼發展一門心思搞技術之時,又出現了「路線之爭」:
閉源路線:以國外OpenAI的ChatGPT,Anthropic的Claude,谷歌的Gemini,國內百度的文心一言,月之暗面的Kimi等企業為典型代表,傾向於閉源大模型的高效能,強商業化等優勢,其中以百度最為激進,李彥宏近期便一直以「閉源擁躉」頻頻出圈,發表諸如「開源大模型是智商稅「,」大模型場景下開源是最貴的」等出位言論,引發行業熱議;
開源路線:以META的Llama,國內阿裏雲的通義為典型代表,認為開源模式的協作特性可實作技術的快速叠代,可以透過模型托管提高雲端運算的業務成長空間,且該路線有利於數據敏感型組織透過私有雲或本地化內網落地大模型,較之閉源具有高成長性,多落地場景等優點。
與行業往日爭議不同,此次大模型爭論充滿技術情懷,從業者爭論多聚焦在 「技術之爭」,李彥宏就表示「開源模型會越來越落後」,其讓頻頻登上熱搜。
那麽在這場開閉源的爭論中我們要建立怎樣的分析框架?又來如何理性評判當前的路線之爭呢?
其一,根據Scaling laws原理,大模型的成功乃是更大算力,更多數據,更高算力的綜合結果,這背後則是資金的海量投入,基礎設施完善,管理的穩定等等,大模型沒有閃電戰只有持久戰;
其二,百度選擇閉源有技術的考量,但與商業路徑也密不可分;
其三,開源大模型並沒有想象那般弱雞,閉源也不一定能永遠保持先進性;
其四,開閉源大模型共存將會是長期趨勢;
Scaling laws原理:大模型將長期燒錢我們首先從大語言模型中的第一性原理「Scaling laws」入手分析(被轉譯為「縮放原理」或「尺度定律」)。
2020 年 1 月,OpenAI 釋出論文【Scaling Laws for Neural Language Models】,奠定了 Scaling Law的基礎, 為後續 GPT 的叠代指明了方向:更大參數、更多數據和更多算力能夠得到更好的模型智能。
也就從此時開始,OpenAI開啟了大參數模型路線,GPT-3的參數已經達到1750億(GPT-2還只有15億),訓練數據則直接躍升到570億G。
大模型的大參數軍備競賽也由此拉開大幕, 動輒數千億級的大模型流行於市場,帶來技術的快速發展和普及。
由此也就引發了一個新的問題:算力。
根據 Scaling Law 論文,可以用 6ND 來估算模型所需要的訓練算力(N為參數,D為數據集TOKEN數), 算力需求在大模型時代得到指數級提升(長文本大模型所需算力可能還要高於6ND)。
這一方面催生了底層算力提供者輝達為代表的GPU廠商的爆炸式增長,另一方面大模型廠商若要保持技術先進性就必須花大價錢在算力基礎設施方面。

在華泰證券的圖表中我們也能清晰看到大模型與此前的雲端運算爆發式增長一樣,業務的增長是要基礎算力的高投入為前提的。根據Visible Alpha一致預測,2026年全球科技四巨頭(微軟,谷歌,META和亞馬遜)合計資本支出將達2399億美元,2023-2026年CAGR為18.86%。
有觀點曾寄希望於Scaling Law的邊際效應收窄效應,認為只要熬到技術成熟期(Scaling Law效應邊際效應迅速放大之時),算力的投入便會達峰,此時模型只需要維護自身模型的可靠性與穩固性即可,只是站在當下時代,Scaling Law遠未到終點。
清華大學的唐傑教授在2024年 2 月就指出: 我們還遠未到 Scaling law 的盡頭, 數據量、計算量、參數量還遠遠不夠 。未來的 Scaling law 還有很長遠的路要走。
現實中主流大模型廠商的算力仍然在持續增大,模型的參數規模也在增大,行業終局是看不到頭的。
研發人員固然可以透過技術架構最佳化和軟硬件資源協同等方面來提高大模型的效能,只是我們也必須得承認, 指數級的大模型技術叠代仍然仰賴於高參數和強算力。
在上述兩項約束條件下,大模型廠商不得不面臨非常棘手的問題:
如果把算力的資本性支出視為「蛋」,大模型的高效能為「雞」,究竟雞生蛋還是蛋生雞就成了大模型廠商不得不面臨的問題。

我們以閉源大模型的忠實擁躉百度為例,在基石的廣告業務壓力不斷加碼之時,其經營理念已經越加審慎,如對非核心業務的裁撤,人員的最佳化等等。這在資本開支中則反饋表現為支出的越加保守,過去三年表現非常明顯。
2023年META和亞馬遜等科技頭部企業也均在進行資本支出的結構性最佳化,如亞馬遜的物流倉儲成本開始降低,與此同時雲端運算的數據中心等基礎設施仍處於大規模擴張中。百度亦是如此,表面看其資本開支越發慎重,但大模型相關的基礎設施投入必然是高速增長的。
這對百度也就會帶來一個問題,結構化的資本開支縮減終有結束之時,Scaling Law還遠未能看到終端,加之「第二曲線」短期內無法扛起支出重任, 從財務方面就迫使百度不得不在商業路徑上進行考慮。
以賣模型(API介面)的閉源大模型成為首選,對C端使用者文心一言收取會員,對B端以API的介面費為主要變現,又由於閉源大模型乃是企業獨家開發,維護和管理成本也相對低廉,對百度是十分劃算的。 在雞生蛋和蛋生雞的問題上,百度選擇了雞生蛋。
可閉源果真就能戰勝開源嗎?
開源大模型不弱雞前文中我們已經從大模型的原理,技術以及商業路徑角度,簡單勾勒了行業當前的現狀,並對百度對閉源大模型抱以極度的熱忱有了一定的理解。
接下來我們來討論開閉源大模型的趨勢性問題 。
如開篇所言,李彥宏對開源大模型常有鄙夷之情,如開篇「開源模型會越來越落後」,又如「沒有套用,開源閉源模型都一文不值」,閉源大模型果真如此不堪嗎?
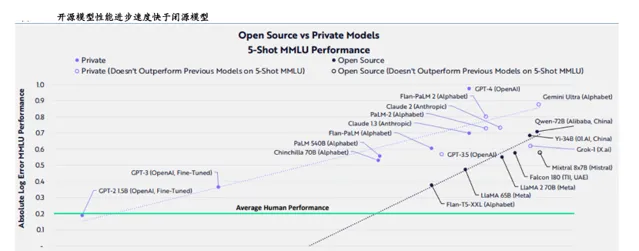
ARK Investment每年都會將其觀點和洞察力發表在年初的「Big Ideas」報告中,在2024年的報告中,」開源模型效能進步快於閉源模型「乃是其重要觀點之一。在上圖中阿裏雲的Qwen-72B乃為閉源大模型之最。
一方面閉源大模型確實有先發優勢,以OpenAI的ChatGPT為典型代表,但另一方面大模型的演進又是一個持久戰(Scaling law為主要因素),對企業的管理,投入以及持續的創新力就有了更高的要求,如此前OpenAI一系列的「人事鬥爭」很難說不會影響核心業務。
與之所對應的開源大模型也在此時開始展示先進性。
2024 年 4 月,Meta 釋出 Llama 3,設計目標是多模態、多語言,根據 Meta 公布的目前訓練數據,其效能與 GPT-4 相當。
Llama大模型的成功給了開源陣營足夠的信心,在權威機構推出全新的大模型測評基準LiveBench AI中,阿裏通義Qwen2拿下美國最新測評榜單開源大模型全球第一,成績超過Meta的Llama3-70B模型。
在基礎算力的投入保障之下,拉長時間線,開源大模型是可以保持足夠競爭力的,僅就此來看李彥宏鄙夷開源大模型效能不進步是站不住腳的。
這再次告訴我們: 閉源和開源絕非技術理念之爭,而是商業路徑的分歧。
那麽究竟哪何種商業路徑最適合大模型的落地呢?
篇幅原因我們省去繁瑣的分析過程,精簡觀點如下:
中短期:閉源大模型在變現方面優勢更明顯,以賣模型為主要商業模式,簡單易操作。百度又可以透過改造原互聯網套用產品(如地圖,文庫,搜尋等),實作模型的落地改進產品力,將業務線由「AI+」向「+AI」過渡。此外需要提醒的是,企業內部原產品線的改造也是伴隨巨大的成本開支需求的,如華泰證券曾測算,META若內容推薦完全以大模型為主,取代原有演算法,將需要至少50萬片輝達GPU,僅此一項就是一筆巨大開支(最近有訊息稱META今年GPU規模將超過30萬塊),這就對短期內閉源大模型的落地和變現提出了更高的要求。
長期:開源大模型走的更遠,如高度客製化的特點將提高大模型對不同行業的滲透率,當不同行業的接入大模型,提高大模型的應有廣度之後,企業開發展則要仰賴於開源大模型背後的算力和雲端運算平台,以實作可持續增長。
在上述兩種路徑中, 「資本」是商業模式運轉的必要條件 ,這又回到了我們前文所言的「雞生蛋」的悖論。
這也就使得采取閉源大模型的往往具有以下特點:套用端具有得天獨厚優勢(如谷歌),又如技術上短期內遙遙領先(如OpenAI);
開源大模型則具有:資金底子雄厚(如META),雲端運算基礎設施健全(如阿裏雲),能夠熬得住,扛得起基礎設施膨脹帶來的巨大成本,又能接得住開源大模型普及後的雲端運算需求。
顯然沒有一種大模型是兼有所有優點而無缺點的,百度此時以激烈語言來鼓吹閉源大模型,其背後應是其短期商業化的焦慮(此前API介面價格戰對閉源大模型影響更大),以及對爭奪目標客戶心智的野心。
基於此 我們並不認為會有包打一切的大模型路徑 ,相反企業選擇適合自己的路徑更多是「權宜之計」,客戶選擇開閉源模式也將會有自己的考量,一些企業也采取開閉源共存的模式來滿足不同客戶需求,如谷歌將輕量級的開源模型系列Gemma進行開源。
不過此時發表出格語言最能出圈,能夠提高閉源大模型優點的普及型,只是忽視了開源大模型絕非「弱雞」,大模型的發展會是持久戰,未來有太多的不可測性,輕易下斷言在其後很可能被反噬。











