在法蘭·赫伯特的【沙丘】中,沙漠星球厄拉科斯的沙丘下隱藏著一種無價之寶:香料。這種神秘物質使太空旅行成為可能,能延長壽命,並具有擴充套件意識的效果,是宇宙中最寶貴的財富。「誰控制了香料,誰就控制了宇宙」。正如香料在【沙丘】宇宙中占據著至關重要的地位一樣,在當今的生成式人工智能時代,數據也承載著類似角色。
就像【沙丘】中對香料的爭奪,現實世界裏各方勢力也在為數據資源展開激烈角逐。海量的數據如同埋藏在數碼世界沙丘下的「香料」,蘊藏著難以估量的價值。而那些能夠高效采集、管理和利用數據的企業,就像小說中控制香料的勢力,在這場數據爭奪戰中占據著優勢地位。
如同香料在【沙丘】宇宙中的供應並不是無限的如果開采過度或生態系受到破壞,香料的產量可能會大幅減少甚至耗盡,數據也可能被耗盡。根據非營利研究機構Epoch AI的最新論文,大語言模型會在2028年耗盡互聯網文本數據。
大模型真的在吞噬人類的一切數據嗎?我們是否正處在一個看似無盡的數碼香料狂潮中,不斷地向這些饑渴的大模型提供養分?
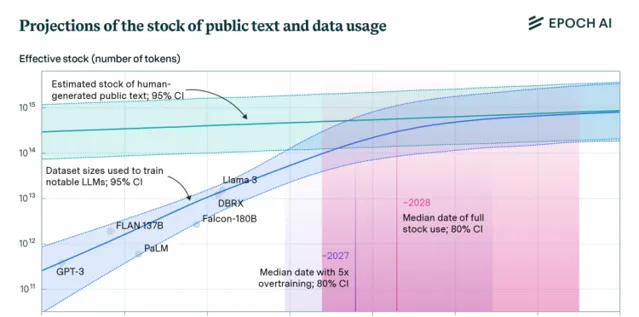
人類生成的數據量有限,一旦這些文本數據被耗盡,可能會成為約束語言模型繼續擴充套件的主要瓶頸。相關論文認為,語言模型將在2026年到2032年之間利用完這些數據,但如果考慮到利潤最大化,過度訓練數據可能會導致數據在2025年就被用完。
月之暗面創始人楊植麟也在近期表達了類似觀點,他認為大模型通向AGI最大的挑戰是數據。楊植麟表示,「假設你想最後做一個比人類更好的AI,但可能根本不存在這樣的數據,因為現在所有的數據都是人產生的。所以最大的問題是怎麽解決這些比較稀缺、甚至一些不存在的數據。」
根據Epoch研究員Pablo Villalobos的觀點,OpenAI在訓練GPT-4時使用了大約1200萬個token,GPT-5需要60到100萬億個token才能跟上預期的增長。關鍵在於即使用盡互聯網上所有可能的高質素數,仍然需要10萬到20萬億token,甚至更多。
面對如此龐大的數據需求,合成數據也是一個學術界和產業界都在嘗試的重要方向。合成數據基於現有數據進行擴充,這種能力對未來的訓練數據規模至關重要。不過,用AI生成的數據進行訓練也存在一些局限性,例如可能導致模型崩潰等問題。
目前,大模型廠商主要從網絡上抓取科學論文、新聞文章、維基百科等公開資訊來訓練模型。從長遠來看,僅依靠新聞文章和社交媒體等內容可能無法維持人工智能的發展需求。這可能迫使企業開始利用一些敏感的私有數據,如電子郵件、聊天記錄等,或不得不依賴於聊天機器人自身生成的質素不高的數據。
數據不夠用是「杞人憂天」?沒有數據就無法訓練大語言模型,但數據真的不夠用了嗎?對於這一問題,也有人持有不一樣的觀點。
星環科技孫元浩認為,這是一個「假新聞的判斷」。在他看來,除了現有互聯網的存量數據,各個企業內部還有大量的數據沒有被利用,「現在數據多到遠遠超過模型可以處理的量」。
「大模型結構和訓練方法都不是秘密了,而語料散落在各種地方,需要把現有語料整理起來訓練或微調模型,工作量非常巨大,這是目前最大的挑戰。」孫元浩告訴矽星人。
其中的一個重要問題,是數據處理範式從結構化數據到非結構化數據的轉變。結構化數據,例如數據庫中的表格數據,有明確的欄位和格式,易於儲存和查詢。而文本文件、合約協定、教材等非結構化數據,雖然包含豐富的資訊和知識,但由於缺乏統一的格式,難以直接儲存和檢索,企業內部的非結構化數據往往也需要更專業的數據標註處理。
為此,星環試圖透過提供包括語料處理、模型訓練、知識庫建設在內的工具鏈,提升企業的數據處理能力。「我們意識到不可能一個模型通曉各個領域,企業核心機密是不可能讓你知道的,我們定位為提供工具幫你做訓練,你自己煉一個模型。」
挖掘企業內部數據重要性的另外一個例證是摩根大通擁有150PB的專有數據集,而GPT-4僅在不到1PB的數據上訓練。不過兩者的數據在質素、類別和用途上存在顯著差異。大模型面臨的挑戰主要在於獲取高質素、多樣化且合法可用的訓練數據,而非簡單的數據量不足。
對於「數據荒」,數據服務商景聯文科技創始人劉雲濤也表達了類似觀點。「我們現在真實數據都來不及處理,數據不夠是杞人憂天了。」他向矽星人表示,「我預估洗完之後,中國的高質素數據大概是有150TB,世界上還有很多個國家。」
他認為目前存在的問題主要在於高質素的數據的問題,涉及到數據清洗、數據工程。
劉雲濤表示,大模型時代的核心變化首先是數據量變大了,「以前一個題庫10 萬、20萬道已經很大的專案。現在以億為單位,技術處理能力就變得非常重要了,因為你不可能靠人工。」
第二個變化在標準環節,需要引入專業領域的人工標註,「原來人工標註和自動化標註是一個平行的關系,那現在更像是技術標註放在前一輪,後一輪是專家級的標註。」
專家級標註指的是一種更高級別、更精細的人工標註過程,這種標註工作通常需要專業知識,能夠對自動化標註的結果進行校正和最佳化,以確保數據集的高質素。與此前的用低成本勞動力完成的簡單數據標註工作也有所不同。據稱,OpenAI內部就有一個幾十名博士級別的專業人士組成的團隊來做標註。
大模型廠商在處理數據時遵循的流程通常包括幾個環節:首先,數據從各渠道獲取被獲取後,進入數據工程部門。數據工程師會對數據進行清洗和預處理。接著,處理好的數據會被交給演算法部門,演算法部門會利用多種方法進一步處理,包括調參、透過監督學習對模型進行微調(SFT),以及使用人類反饋來強化學習模型(RLHF),經過這些步驟處理後的數據,最終會被套用到具體的任務或產品中。
在這一過程中,大模型廠商的核心的需求是從分布在各處的數據中提煉出可以用於微調、訓練或持續最佳化模型的高質素數據。
Scale.AI專註於為企業客戶提供訓練數據的數據標註開發。該平台采用自動化標註、半自動化標註和人工稽核等先進技術,提高標註的速度和準確性,並提供數據管理和質素控制工具。
在劉雲濤看來,Scale.AI的核心不在於有很多數據,而是擁有快速處理數據的能力。「Scale AI建立了一整套數據清洗的流程,另外還建立了一套數據引擎,能形成真正的數據飛輪,這是個流程性的技術的問題。」
開源數據的困境大語言模型之所以能夠展現出驚人的理解和生成能力,是因為從海量的預訓練數據中學習了豐富的世界知識。而開源數據,如網頁、書籍、新聞、論文等,正是這些預訓練語料的重要來源。透過開放共享,開源數據為模型提供了廣泛而多樣的知識來源,使其能夠學習到人類社會的方方面面。可以說,沒有開源數據的支撐,大語言模型就難以獲得足夠的「知識養料」來實作快速發展。
由社區和非營利組織推動的開源數據專案,為語言模型的訓練提供了豐富多樣的語料,對推動了自然語言處理技術的發展至關重要。智源研究院林詠華告訴矽星人「如果沒有Common Crawl,整個大模型的發展都會延後。」
她也指出了一個相關的問題,國外誌願者參與的開源數據集的建設,如BookCorpus、古騰堡工程都積累數年時間,而在國內很少有人做類似的事情,這就造成了中文數據的數據孤島問題。
人工智能開源開放數據平台OpenDataLab相關負責人告訴矽星人,數據資源持有方普遍存在的一個顧慮是無法明確數據開源行為對自身的價值,單純的數據開源對於中小型企業很難形成短期的回報。「從投資與回報角度看,企業如果開源模型,其帶來的技術的叠代和創新,對企業來講無疑是一種回報,而開源數據則幾乎是純‘利他’的行為,很難有實際的收益。」
因此,相較於國外由非營利機構推動,國內各類事業單位在推動數據開源的過程中扮演了十分重要的角色。不過,隨著使用者規模和數據需求的增長,也為各類數據開源社區的資金與儲存等帶來了現實挑戰。
OpenDataLab從公開數據收錄、開源平台建設、數據工具研發、高質素原創數據集釋出、生態合作等多方面入手,正在著手推動解決研究和開發中數據需求。
OpeninDataLab表示,中文大規模數據集在開源程度、規模以及質素方面與英文數據集相比存在差距,這在一定程度上制約了中文自然語言處理技術的發展。目前OpenDataLab已經聯合多家機構,釋出了一系列原創高質素的大規模AI數據集,他們也希望能與更多機構一道,透過合作來邀請更多人參與到數據開源事業中來。
在公共數據開放和社會力量方面,中國與美國存在一些差異,美國政府在公共數據開放中扮演著重要角色,致力於「應開盡開」。政府建立專門的AI訓練數據開放平台,對數據進行標識、清洗、標註等處理,並提供便捷的檢索和介面服務。社會力量則整合政府開放數據與網絡公開數據,以開源為主形成高質素訓練語料,並在行業大模型中貢獻專業性。
中國的公共數據共享和利用程度上仍有不足。部份領域如天氣、司法的數據開放不如美國充分,在開發利用中也缺乏API支持。社會力量主要結合海外開源數據和國內網絡公開數據形成訓練集在行業大模型中,社會力量雖有貢獻,但受限於專業門檻高、企業共享意願低、公共數據開放不足等困難。
數據采集中的「灰度」生成式人工智能的發展主要依賴大模型以及對大模型的數據訓練,數據訓練又離不開大規模的數據爬取。數據采集是產業鏈的起點,涉及從互聯網、社交媒體、公共數據庫等多個渠道收集原始數據。這一環節需要遵守數據私密和版權法規,確保數據來源的合法性。隨著技術的發展,自動化工具如網絡爬蟲被廣泛使用,但同時也帶來了數據私密和安全等問題。
五號雷達相關負責人童君告訴矽星人,數據爬取方面,Robots協定在網絡數據獲取是一種行業內的約定俗成。不過Robots協定遵循基於爬蟲的自覺性,並不能從根本上阻止數據的獲取。「這個行業水下的產業占80%,比如場外專案制的數據購買,數據進行二次加工之後,源頭的數據是來自於哪裏?這個東西沒辦法追溯。」
景聯文創始人劉雲濤則建議從「灰度」的角度來看待這個問題,「一個全新的行業,無論從國家到企業、個人都在探索,一定是有灰度的」。他認為,在大數據和人工智能的新興行業中,存在著一些灰色地帶,主張應該用技術手段將灰色地帶變成白色,合法合規。
景聯文用技術手段如SFT或人工標註,將獲取的數據轉化為可交付使用的數據,建立高質素大模型訓練數據集。他打了個比方,就像「別人在野地裏采摘的白菜,經過他們的加工,變成了預制菜。」
隨著數據被定義為新的生產要素,全國各地紛紛成立了大量的數據交易所和交易中心。成為解決行業內的灰色地帶問題,提高市場參與者的安全感的一種新的機制。
截至目前,國內已成立了超過40家數據交易所,包括上海數交所、貴陽大數據交易所和北京國際大數據交易所等。這些交易所透過搭建數據要素流通平台,提供數據供需對接撮合機制,以釋放數據要素的價值。
劉雲濤認為,數據交易所是一個顯著中國特色的新興市場,但建立一個有效的數據交易體系還需要大量的工作來完善。「能不能真正解決數商和購買方之間的問題?如果交易所只是讓我們付出,不能給我們帶來收益,那就沒有意義,這個事是需要時間的。」
五號雷達童君也表示,「大模型廠商基本上不會去交易所買數據。不是說今天我來做大模型,然後買一堆數據回來。」
據介紹,數據交易市場目前存在多種模式。有的大公司建立了平台,提供數據產品和數據集,主要以API形式供企業購買服務。此外,還存在針對特定專案的客製化數據購買模式。在這種情況下,買方了解數據的來源(如氣象局)。並直接與擁有數據的機構或企業進行交易。
「是時候把數據Scale Down了」LLaMA3透過將訓練數據從2T增加到15T,即使模型架構保持不變,模型效能得到了顯著提升,然而,這種「暴力擴充套件」的方法雖然有效,但也面臨著邊際效應遞減和資源消耗增加的問題。
語料規模並非越大越好,而是高資訊密度的語料規模越大越好:Common Crawl是400TB的數據集,包含了互聯網上數十億網頁,內容非常廣泛但未經清洗。而C4則是對CC進行了過濾雜訊、重復內容等清洗後的305GB數據集。經評估發現基於C4訓練的模型效能優於CC,這既說明了數據清洗的重要性,也說明了語料規模不能一味追求大。
近期,DCLM專案組,從Common Crawl中成功提取並清洗出240T的數據,也為數據規模增加的可行性提供了新的證據。這一進展為數據的「Scale Up」策略提供了支持,但同時也提醒人們註意到數據處理和清洗背後的計算成本。

清華博士秦禹嘉表示,前scaling law時代我們強調的是scale up,即努力追求資料壓縮後的模型智能上限,後scaling law時代大家比拼的是scale down,即誰能訓練出「性價比」更高的模型。
例如,PbP團隊利用較小模型的效能評價來過濾數據,從而提升大型模型的訓練效果和收斂速度。類似地,DeepSeek透過使用fastText來清洗高質素數據,為特定場景下的模型訓練提供了優質數據。
這些研究成果暗示,透過徹底最佳化數據的質素,小型模型的訓練效果可以接近或等同於使用大規模「臟數據」訓練的大型模型。這不僅示範了數據清洗在提升模型效率中的重要性,也說明在某些情況下,模型的參數規模並非越大越好,關鍵在於如何有效地利用每一份數據。
隨著AI領域的不斷發展,這種對「效率」和「質素」的追求正在成為研究和實踐中的新趨勢。未來,數據處理的方法,包括數據去噪、覆寫預訓練數據等策略,將成為推動大模型發展的關鍵因素。同時,這也意味著數據質素可能成為衡量AI模型效能的新標準,而不僅僅是數據規模。

在當今快速發展的人工智能領域,數據成為了推動技術前進的基石,它的角色越來越像【沙丘】中珍貴的香料——無處不在,價值巨大。隨著對數據需求的增長,如何有效地收集、處理和利用這些「數碼香料」成為了關鍵問題。從提高數據質素到拓寬數據獲取渠道,未來的AI發展不僅取決於我們如何應對這些挑戰,更在於我們如何在數據的海洋中探尋新的可能。正如【沙丘】展示的那樣,真正的力量來自於對這些資源的理解和利用——誰解決好了數據問題,誰就擁有了未來的鑰匙。
【沙丘】中的領航員透過食用香料獲得了預測未來的能力,人工智能演算法透過處理大量數據集,發現模式和趨勢。在【沙丘】宇宙中,人類在香料混合物的影響下前進演化,獲得新的能力並經歷意識的重大飛躍。同樣,人工智能乃至AGI的發展也可能會為人類帶來類似的深遠影響。
只不過如果知道十年前在社交媒體上釋出的內容,有朝一日會成為推動技術進步的「香料」,或許我們會更加慎重地對待自己的數碼足跡。











