深度學習框架作為基礎軟件,不僅促進了深度學習技術的飛速進步,更為⼈⼯智能技術的⼴泛應⽤鋪設了堅實的基礎。
深度學習框架為開發者提供了便捷易⽤的開發接⼝,這些接⼝對數據和操作進⾏了⾼度抽象,使得開發者能夠更專註於演算法和模型的設計,⽽不必深陷底層數據的處理細節。透過這些接⼝,開發者⽆需直接感知和應對復雜的硬件底層開發細節,從⽽極⼤地提升了開發效率和體驗。其次深度學習框架還提供了⾃動微分這⼀強⼤功能,開發者通常只需要編寫前向傳播⽹絡的程式碼,⽽繁瑣的反向傳播⽹絡則交由框架⾃動完成。
飛槳作為中國⾸個⾃主研發、功能豐富、開源開放的深度學習平台,從預設使⽤靜態圖的1.0版本,到預設采⽤動態圖並可實作動靜統⼀與訓推⼀體的2.0版本釋出,飛槳框架已經可以完美融合動態圖的靈活性與靜態圖的⾼效性,並⽀持模型的混合並⾏訓練。
如今,為⼤模型時代⽽精⼼打造的3.0版本正式出爐!飛槳正式開啟了新⼀代框架技術創新之路!
01
設計思想
深度學習框架的設計對於推動⼈⼯智能技術的發展⾄關重要,其核心設計目標是讓深度學習技術的創新與套用更簡單。
要想實作這⼀⽬標,需要考慮以下兩點:
▎框架需要充分考慮開發者和硬件⼚商的需求。
從⽤戶角度出發,⼀個優秀的深度學習框架應當為開發者提供極致的開發體驗。這不僅僅意味著提供⼀個⽤戶友好的開發環境,更重要的是要能夠⼤振幅減少開發者的學習成本和時間成本,同時顯著提升開發的便利性。為此,飛槳框架提出了「動靜統⼀、訓推⼀體、⾃動並列」的理念,極⼤地提⾼了開發效率。
從昇騰適配⻆度出發,框架必須能夠⽀持並且充分發揮昇騰硬件的效能優勢。這要求框架能夠⽀持昇騰硬件接⼝,同時,為了充分發揮昇騰硬件的效能,框架還需要具備軟硬件協同⼯作的能⼒,確保在利⽤昇騰硬件資源時能夠達到最優的效能表現。
▎與此同時,好的框架還需要考慮到 AI 技術發展的整體趨勢、產業的實際落地應⽤的需求。
技術發展層⾯,⼤語⾔模型(Large Language Model,簡稱 LLM)、混合專家系統(Mixture of Experts,簡稱 MOE)、多模態以及科學智能(AI for Science)等前沿技術逐漸成為新的研究熱點。隨著模型復雜性的增加,計算瓶頸、儲存瓶頸、訪存瓶頸以及通訊瓶頸等問題逐漸凸顯,對分布式訓練和通⽤效能最佳化的需求⽇益迫切。
在產業化層⾯,框架⼜需要具備⽀持訓練、壓縮、推理⼀體化的全流程能⼒。這意味著,從模型的訓練到最佳化,再到昇騰硬件實際部署和推理,框架應當提供⼀套完整、⾼效的解決⽅案,才能滿⾜產業界對於深度學習技術的實際需求。
只有跟得上趨勢、經得住打磨的框架,才能為產學研各界開發者提供持續穩定的⽀持。

飛槳框架3.0的設計理念和主要特色
綜上需求,飛槳將為開發者提供⼀個「動靜統⼀、訓推⼀體、⾃動並⾏、⾃動最佳化、⼴泛硬件適配」的深度學習框架,開發者可以像寫單機程式碼⼀樣寫分布式程式碼,⽆需感知復雜的通訊和排程邏輯,即可實作⼤模型的開發;可以像寫數學公式⼀樣⽤ Python語⾔寫神經⽹絡,⽆需使⽤硬件開發語⾔編寫復雜的算⼦內核程式碼,即可實作⾼效運⾏。
飛槳框架 3.0 版本應運⽽⽣,延續了2.x 版本動靜統⼀、訓推⼀體的設計理念,其開發接⼝全⾯相容2.x 版本。這意味著,使⽤2.x 版本開發的程式碼,在絕⼤多數情況下⽆需修改,即可直接在3.0版本上運⾏。在飛槳框架3.0-beta 昇騰版中,著重推出了動靜統⼀⾃動並⾏、⼤模型訓推⼀體、⼤模型昇騰硬件適配三⼤新特性。這些特性在飛槳框架2.6版本或更早版本時就已經開始開發,⽬前已達到外部可試⽤的階段。這些新特性顯著提升了使⽤體驗、效能、⼆次開發便利度以及硬件適配能⼒。飛槳正式釋出3.0版本,此版本改進了框架2.x 版本部份已有功能,並且在不使⽤新特性的情況下,表現成熟穩定。
02
框架架構⼀覽
為了實作深度學習框架的上述特性,必須對框架的架構進⾏精⼼設計,確保其能夠⽀持各種復雜的模型構建,同時與多樣化的芯⽚實作⽆縫對接。接下來,將透過直觀的架構圖,詳細展示飛槳新⼀代框架內所涵蓋的功能模組,以及這些模組之間的相互作⽤與聯系。以下為飛槳框架3.0的架構圖。

飛槳框架 3.0 架構圖
豐富接⼝:飛槳框架對外提供了豐富的深度學習相關的各種開發接⼝,如張量表示、數學計算、模型組⽹、最佳化策略等。透過這些接⼝,開發者能夠便捷地構建和訓練⾃⼰的深度學習模型,⽆需深⼊到底層的技術細節中去。
在開發接⼝之下,飛槳框架可以劃分為4個層次:表示層、排程層、算⼦層和適配層。
表示層:專註於計算圖的表達與轉換,透過⾼擴充套件中間表示 PIR,為動轉靜(動態圖轉為靜態圖)、⾃動微分、⾃動並⾏、算⼦組合以及計算圖最佳化等核⼼功能提供堅實⽀撐。
排程層:負責對程式碼或計算圖進⾏智能編排與⾼效排程,並且能夠根據實際需求進⾏視訊記憶體和記憶體的管理最佳化,⽀持動態圖和靜態圖⾼效執⾏。⽆論開發者選擇使⽤動態圖還是靜態圖進⾏模型開發,飛槳框架都能提供⾼效的執⾏環境,同時確保資源利⽤的最佳化。
算⼦層:由神經⽹絡編譯器 CINN 和算⼦庫 PHI 共同構成,涵蓋了張量定義、算⼦定義、算⼦自動融合和算⼦內核實作等關鍵功能。
適配層:則⽤於實作與底層芯⽚適配,包括器材管理、算⼦適配、通訊適配以及編譯接⼊等功能。
03
升級的主要模組介紹
1) ⾼擴充套件中間表示 PIR:透過打造全架構統⼀的中間表示,突破框架層各模組壁壘,提升飛槳在科學計算、編譯最佳化、⼤模型領域的潛⼒;
2) ⾃動並列:降低大模型場景模型開發和效能最佳化的成本,⼤幅提升⼤模型場景的⽤戶體驗
▎⾼擴充套件中間表示 PIR
計算圖中間表示(Intermediate Representation,即 IR)是深度學習框架效能最佳化、推理部署、編譯器等⽅向的重要基⽯。近些年來,越來越多的框架和研究者將編譯器技術引⼊到深度學習的神經⽹絡模型最佳化中,並在此基礎上借助編譯器的理念、技術和⼯具對神經⽹絡進⾏⾃動最佳化和程式碼⽣成。在⼤模型時代,對 IR 在靈活性、擴充套件性、完備性有了更⾼的要求。
因此在3.0版本下,飛槳在基礎架構層⾯規範了中間表示 IR 定義,實作全架構統⼀表示,實作上下遊各個⽅向共享開發成果。飛槳的新⼀代 IR 架構聚焦於⾼度靈活和⾼擴充套件性兩個重要維度,透過更加完備且魯棒的語意表達能⼒、訓推全架構統⼀表示和⾼效可插拔的效能最佳化策略(Pass)開發機制,實作復雜語意⽀持,更便捷地⽀撐⼤模型⾃動並⾏下豐富的切分策略,⽆縫對接神經⽹絡編譯器實作⾃動效能最佳化和昇騰硬件適配。
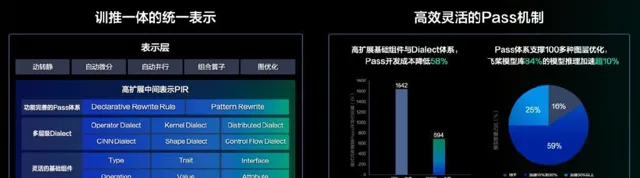
訓推一體的統一表示和效能最佳化策略(Pass)機制
飛槳中間表示(PIR)在底層抽象了⼀套⾼度可延伸的基礎元件,涵蓋 Type、Attribute、Op、Trait 和 Interface,並引⼊了 Dialect 的概念,賦予開發者靈活擴充套件與⾃由客製的能⼒,從⽽提供了全⾯且穩健的語意表達能⼒。在模型表示層,透過多 Dialect 的模組化管理和統⼀多端表示,實作了訓練與推理⼀體化的全架構統⼀表示,實作了算⼦和編譯器的⽆縫銜接,⽀持⾃動最佳化和多硬件適配。在圖變換層,透過統⼀底層模組並簡化基礎概念,向⽤戶提供了低成本、易⽤且⾼效能的開發體驗,以及豐富且可插拔的 Pass 最佳化機制。飛槳 PIR 堅守靜態單賦值(SSA)原則,確保模型等價於⼀個有向⽆環圖,並采⽤ Value 和 Operation 對計算圖進⾏抽象,其中 Operation 代表節點,Value 代表邊。
Operation 表示計算圖中的節點:每個 Operation 表示⼀個算⼦,並包含零個或多個 Region。Region 表示⼀個閉包,它內部可以包含零個或多個 Block。⽽ Block 則代表⼀個符合靜態單賦值(SSA)原則的基本塊,其中包含零個或多個 Operation。這三者之間透過迴圈巢狀的⽅式,能夠構建出任意復雜的語法結構。
Value 表示計算圖中的有向邊:它⽤於連線兩個 Operation,從⽽描述了程式中的 Use-Define 鏈(即 UD 鏈)。其中,OpResult 作為定義端,⽤於定義⼀個 Value;⽽ OpOperand 則作為使⽤端,描述了對某個 Value 的使⽤情況。
飛槳提供了 PatternRewriter 和 Declarative Rewrite Rule(簡稱 DRR)這兩種 Pass 開發機制,兼顧了⾃定義的靈活性與開發的易⽤性。采⽤三段式的 Pass 開發⽅式,使開發者能夠更加專註於 Pass 邏輯的處理,⽽⽆需關註底層IR的細節。
▎動靜統⼀⾃動並⾏
為什麽我們要做⾃動並⾏?
當前⼤模型主流訓練⽅式,會⽤到多種並⾏策略,這些並⾏策略基於動態圖模式實作的「⼿動」並⾏⽅式,即在單卡的基礎上,⼿⼯處理切分(切分 Tensor、計算圖)、通訊(添加通訊算⼦)、視訊記憶體最佳化(視訊記憶體共享、Re-Compute)、排程最佳化(流⽔線編排、計算和通訊異步)等策略,開發者既要熟知模型結構,也要深⼊了解並⾏策略和框架排程邏輯, 使得⼤模型的開發和效能最佳化⻔檻⾮常⾼。除了要有專門演算法團隊負責模型演算法創新,還必須有專門負責模型並列最佳化的團隊配合,這給⼤模型的創新和叠代帶來了諸多障礙。
我們舉⼀個簡單的例⼦,來闡釋下⼤模型開發和單卡邏輯的差異,由於並⾏策略會引起 Tensor 運⾏時 shape 發⽣變化,所以與 shape 處理相關的算⼦均需考慮是否會受到並⾏策略的影響。如下⾯ reshape 的處理,切分策略導致輸⼊ shape 發⽣了變換,所以輸出的 shape 需要根據切分策略進⾏合理的調整:
(詳細程式碼請進入百度AI公眾號內同篇文章檢視)
為此,我們提出了動靜統⼀的⾃動並⾏⽅案。開發者僅需少量的張量切分標註,框架便能⾃動推匯出所有張量和算⼦的分布式切分狀態,並添加合適的通訊算⼦,保證結果正確性;最後會根據模型結構和集群資訊,結合視訊記憶體、排程層最佳化,⾃動尋找最⾼效的分布式並⾏策略。
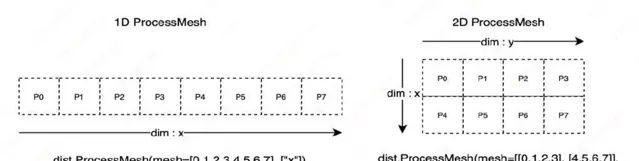
在⾃動並⾏設計中,開發者僅需少量的張量切分標註,我們將切分⽅式進⾏抽象,共需兩類切分⽅式:切分張量(參數,輸⼊)和切分計算圖(流⽔線)。為實作這兩類切分⽅式,框架需要⼀種機制來描述分布式張量和計算器材之前的對映關系,為此我們引⼊ ProcessMesh 和 Placements 兩個分布式概念,其中 ProcessMesh 將⼀塊 GPU 卡對映為⼀個行程,將多個器材對映為多個行程組成的⼀維或多維陣列,下圖展示了由 8 個器材構成的兩種不同 ProcessMesh 抽象表示。
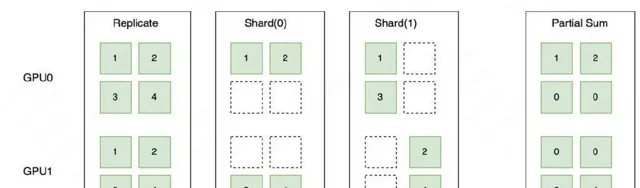
Placements 是由 Replicate、Shard、Partial 三種分布式標記組成的列表,長度和 ProcessMesh 的維度⼀致,⽤於表示分布式張量在對應計算器材的維度上,按照哪種分布式標記做切分,這三種分布式標記的詳細描述如下:
如下圖所示,Replicate 表示張量在不同器材上會以復制的形式存在;Shard 表示按照特定的維度在不同器材上進⾏切分;Partial 表示器材上的張量不完整,需要進⾏ Reduce Sum 或者 Reduce Mean 等不同⽅式的操作後,才能得到完整的狀態。
在完成分布式標記抽象後,我們透過調⽤
paddle.distributed.shard_tensor()
接⼝,實作對張量切分的標記。透過張量切分的標記和⾃動推導,我們可以表示復雜的分布式混合並⾏,下圖展示了⼀個具體的數據並⾏、張量模型並⾏、流⽔線並⾏組成的混合並⾏的例⼦。

以下程式碼展示了混合並⾏的具體例⼦。
(詳細程式碼請進入百度AI公眾號內同篇文章檢視)
透過采⽤⾃動並⾏的開發⽅式,開發者⽆需再考慮復雜的通訊邏輯。以 Llama 任務為例,分布式訓練核⼼程式碼量減少了50%,從⽽⼤⼤降低了開發的難度;從我們的⼀些實驗可知,借助全域的分析等最佳化,效能也優於動態圖⼿動並⾏的效能。
未來,我們將進⼀步探索⽆需使⽤張量切分標記的全⾃動並⾏,讓開發者可以像寫單機程式碼⼀樣寫分布式程式碼,進⼀步提升⼤模型的開發體驗。
04
⼤模型昇騰適配
飛槳與昇騰就⼤模型⽀持進⾏了適配,歡迎⼤家按照使⽤教程體驗:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/npu/llama
。我們的技術⼯作包括:
▎融合算⼦
融合算⼦透過將多個操作合並為⼀個操作來有效減少記憶體存取,提升訓練效率。FlashAttention 算⼦最佳化:昇騰⽀持 FlashAttention2最佳化演算法的融合算⼦,計算精度⽀持 FP16、BF16,sequence length ⽀持最⼤8k。在昇騰親和的 Shape 配置下,Flash Attention 計算的硬件利⽤率可以得到有效提升。Sparse attention:FlashAttention 融合算⼦參數使能 Sparseattention 計算,有效減少50%+的 QK 計算量。除此之外,當前飛槳+昇騰⽬前⽀持融合算⼦主要包括:RMSNorm、Swiglu、RotaryMul、ApplyAdamW 等;累計效能收益可達20%~30%。
▎數據類別適配
不同的數據類別可能會對效能產⽣顯著影響,當昇騰使⽤ double 數據類別時,算⼦會透過 AICPU 來執⾏,⽽這可能會導致效能⼤振幅下降,如下圖所示。為了避免類似情況引⼊的效能問題難以發現,我們在昇騰適配層程式碼加⼊告警,以便於問題定位。

AICPU 算子最佳化前
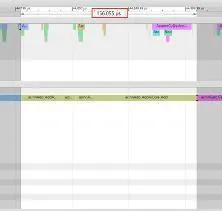
AICPU 算子最佳化後
▎計算與通訊並⾏
在開啟了 TP 和 SP 的⼤模型訓練場景下,存在matmul計算和all-reduce操作的強依賴關系(不開啟 SP),或存在 matmul 計算和 all_gather/reduce_scatter 操作的強依賴關系(開啟 SP)。當模型參數量較⼤時,此處通訊量和計算量都較⼤,在串⾏執⾏時,會引⼊較長的等待閑置時間。解決⽅案:將 matmul 計算和集合通訊操作進⾏融合,將較⼤的計算和通訊任務切分成較⼩的計算⼦任務和通訊⼦任務,透過流⽔的⽅式使得通訊⼦任務和計算⼦任務可以互相掩蓋,從⽽減少等待和閑置時間,提⾼利⽤率。
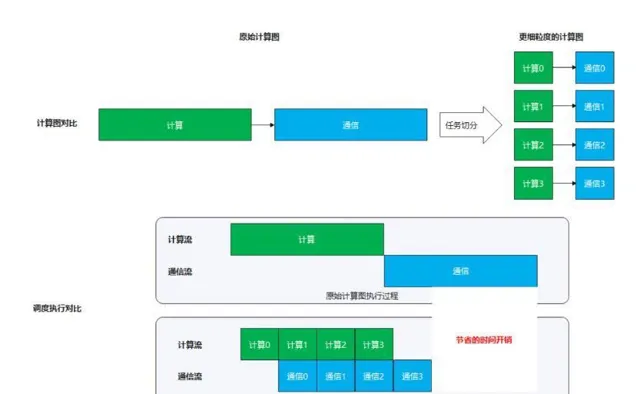
原始計算圖vs切分後的更細粒度的計算圖 & 執行過程模擬對比
▎profile ⼯具
昇騰與飛槳共建了 profile ⼯具,能夠⽅便地⽣成效能分析數據。
(詳細程式碼請進入百度AI公眾號內同篇文章檢視)
接下來使⽤ msprof ⼯具輸出分析結果。
(詳細程式碼請進入百度AI公眾號內同篇文章檢視)
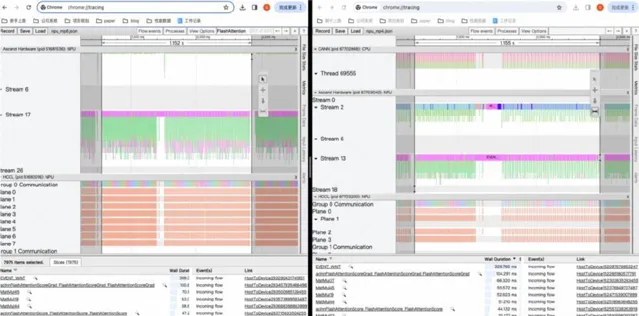
在昇騰硬件上采集 profiling 資訊
05
產業優勢
總的來說,飛槳新⼀代框架——飛槳框架3.0-beta 昇騰版⾯向⼤模型進⾏專屬設計,向下與昇騰硬件適配,充分釋放昇騰硬件潛能;向上⼀體化⽀撐⼤模型的訓練、推理。同時具有動靜統⼀⾃動並⾏、⼤模型訓推⼀體、⼤模型昇騰硬件適配三⼤能⼒,全⾯提升了服務產業的能⼒。
動靜統⼀⾃動並⾏:這⼀功能⼤振幅降低了產業開發和訓練的成本。使用者只需在單卡基礎上進⾏少量的張量切分標記,飛槳框架便會自動完成分布式切分資訊的推導,並添加通訊算⼦以確保邏輯的正確性。同時,根據模型結構和集群資訊,結合視訊記憶體和排程層的最佳化,飛槳能自動尋找最⾼效的分布式並列策略,從⽽大幅降低混合並⾏訓練的開發成本,使開發者能夠更專註於模型和演算法的創新。
⼤模型訓推⼀體:這⼀特性為產業提供了極致的開發體驗。它使訓練和推理的能⼒能夠相互復⽤,為⼤模型的全流程提供了統⼀的開發體驗和極致的訓 練效率。透過動轉靜的⼯作,訓練和推理的⼯作得以⽆縫銜接。可以在訓練過程中⽣成計算復⽤推理最佳化,也可以在推理量化場景復⽤訓練的分布式⾃動並⾏策略,提升效率。
⼤模型昇騰適配:飛槳適配昇騰硬件並充分釋放昇騰硬件潛能。在接⼊機制上,飛槳提供了簡潔⾼效的抽象接⼝和基礎算⼦體系,降低了昇騰適配成本。在運⾏機制上,它最佳化了排程編排和儲存共享等機制,提升了排程效率。同時,飛槳還與昇騰深度合作,建設了程式碼合⼊、持續整合、模型回歸測 試等研發基礎設施。這些機制保障了昇騰硬件被納⼊飛槳的正常發版體系中,⽤戶⽆需編譯即可直接安裝試⽤。

這就是飛槳的新⼀代框架——飛槳框架3.0-beta 昇騰版,⽬前此版本已⾯向開發者開放,並且所有的開發接⼝跟2.0完全相容,歡迎⼴⼤開發者使⽤和反饋。
(詳細程式碼請進入百度AI公眾號內同篇文章檢視)
▎官⽅開放課程
7⽉⾄10⽉特設【飛槳框架3.0全⾯解析】直播課程,邀請百度飛槳核⼼團隊數⼗位⼯程師傾囊相授,內容包括技術解析加程式碼實戰,帶⼤家掌握包括核⼼框架、分布式計算、產業級⼤模型套件及低程式碼⼯具、前沿科學計算技術案例等多個⽅⾯的框架技術及⼤模型訓推最佳化經驗。
▎飛槳動態早知道
為了讓優秀的飛槳開發者們掌握第⼀⼿技術動態、讓企業落地更加⾼效,根據⼤家的呼聲安排史上最強飛槳技術⼤餐!涵蓋飛槳框架3.0、低程式碼開發⼯具 PaddleX、⼤語⾔模型開發套件 PaddleNLP、多模態⼤模型開發套件 PaddleMIX、典型產業場景下硬件適配技術等多個⽅向,⼀起來看吧!

溫馨提示:以上僅為當前籌備中的部份課程,如有變動,敬請諒解。
▎拓展閱讀
【3.0影片教程】
https://aistudio.baidu.com/course/introduce/31815
【3.0官⽅⽂檔】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/index_cn.html
【開始使⽤】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/overview_cn.html#jiukaishishiyong
【動轉靜 SOT 原理及使⽤】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/sot_cn.html
【⾃動並⾏訓練】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/auto_parallel_cn.html
【神經⽹絡編譯器】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/cinn_cn.html
【⾼階⾃動微分功能】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/higher_order_ad_cn.html
【PIR 基本概念和開發】
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/paddle_ir_cn.html
【⻜槳官⽹】
https://www.paddlepaddle.org.cn/











