最近,用AI「復活」逝者這件事,著實是火出了圈,從包小柏用AI復活自己女兒,到各種用AI復活明星的影片,我們發現,透過AI技術,讓死者「重回人間」似乎成了一件輕而易舉的事。

這樣的情節,不禁讓我想起了【流浪地球 2】中,科學家圖恒宇利用量子電腦,「復活」了因車禍去世的女兒丫丫,賜予她數碼生命的情節。
但其實,現實中的這些AI「復活」,要遠比科幻片中來得廉價、簡易,有些甚至已經發展成了一套產業鏈。
在淘寶上你 只需要花10元 ,就可以重新看到死去親友的音容笑貌。
不過,這樣的技術,最多只能做到「讓照片動起來」、「照片開口說話」,而且動作的振幅一般都很小,讓人有種「一眼假」、「一眼AI」的感覺。
而稍微高級一點,表現得更加栩栩如生的,用的大都是現在的 AI數碼人技術 ,也就是透過 收集大量的死者生前的資訊 ,例如照片、影片、文本等,對其聲音、形象和語言風格進行建模,來讓死者「活過來」。
例如,前段時間,在商湯科技的年會上,人們就用數碼人技術,「復活」了已經去世的湯曉鷗教授。

不過,這樣的「復活」效果,其實還是基於真人的一個非常淺層的、表象的數碼映像,跟真實社會當中的人所擁有的智慧差了老遠。
比如像湯曉鷗這段影片,它裏面的台詞其實是工作人員提前編排好的,既不是來自湯教授本人,也不是來自一個能代表湯教授的AI智能體,只能說是一個樣子貨。
不過話雖這麽說,這AI大模型可是眼看著越來越強大了,憑借大模型技術,是否真的有可能把人腦裏的意識和記憶全掃描下來,然後上傳到電腦裏,從而實作「數碼永生」呢?
賽博轉生
就目前來說,讓人們實作「數碼永生」的方式,主要有兩種:
一種是物理掃描,也就是將人類大腦構造的全部物理組成掃描下來,再上傳到終端;
二是透過文本資訊建模,搜集逝者生前所留下的短訊、社交賬號的留言,或是其他人對他的印象等等,透過這些資訊建立一個大致的思維模型。
就第一種情況而言,雖然目前也有一些小規模的初步嘗試和模擬實驗,但其進展都十分有限。
例如,2018年,英國科學家宣稱利用電子顯微鏡技術對 小鼠的小腦 進行了亞分子級別的三維掃描,並在藍光超算中進行了有限的工作模擬。
而在2021年,耶魯大學、普林斯頓大學和芝加哥大學的科學家們,成功地繪制了包含約 130,000個神經元和5300萬個突觸 的成年果蠅大腦連線組。
發現了嗎?這些被掃描的物件,不是老鼠就是蟲子,都是腦子很小的物種。
除了掃描的規模小,這些實驗對神經回路的模擬能力也非常初級,往往只能提供靜態的快照,無法捕捉到大腦的動態變化,而且哪個結構對應哪種功能,也是一頭霧水。
而僅有的一些對人腦的掃描專案,例如德國海涅大學在2013年進行的實驗,也僅僅只能對 20微米見方 的死者腦組織進行掃描。
而從實體層面掃描人腦,之所以如此困難,簡單來說,主要就三點原因:
1、掃描很困難;
2、硬件儲存能力不行;
3、計算能力不行;
首先,人腦那玩意兒實在太復雜細膩了,裏頭有860億個神經元,要想完完整整把這麽多玩意兒的精確到分子級別的結構都掃描出來,可不是件容易的事兒。
就拿現有最先進的透射電子顯微鏡(TEM)來說,它最高分辨率可以做到0.05納米,聽起來已經很牛逼了。
但問題是,為了透過TEM觀察,樣本需要切得非常薄,通常在幾納米厚度以內,人腦組織是極其復雜的,要將其制備成適合觀察的樣本, 既需要保留細胞間的精細結構,又要防止在切割過程中造成損傷, 這是一個極大的挑戰。
並且,TEM啥的,是用高能的電子流來掃描樣品的。所以拍出來的影像分辨率特別高。
但這玩意兒就有個大問題,它那電子流只能聚焦在樣品的一小塊區域,在任何給定時間,都只能照亮並拍下樣品的一小部份。
所以想用它把整個大腦都掃描個遍,那可費了老勁了,就跟用放大鏡想給整個北京拍全景照一樣難。
就算真的解決上述難題了,但你再想想把一個人腦挨個掃描下來得產生多少數據?
860億個神經元,就算只掃描神經元的大概形狀和連線方式,也至少得拍上萬億張3D影像。每張影像數據量雖然能壓縮到幾十MB,但加起來總量也是幾十艾字節級別的。
這裏稍微解釋下,艾字節(exabytes),是電腦儲存容量單位。也常用EB來表示, 1EB約等於一百萬TB,也就是2的60次方字節。
現在最高端的數據中心級每塊硬碟也就20TB的容量。你要存幾十艾字節?那得幾萬億幾十萬億塊硬碟啊, 占地面積比整個中國都大!
再者,就算把這些數據存下來了,你還得有一個無與倫比的超級電腦系統,才能基於這些數據精確復制出人腦所有神經元的動態反應和互動。
每個神經元細胞內部,都有數以萬計的各種離子通道、蛋白質分子,而它們的狀態都在不斷運動和變化。
如果要模擬全部860億個神經元,那就等於是在同時解無數個巨大方程式組, 每個方程式組都有上萬個未知數和變量。
由於這些算力、硬件層面的種種限制,從實體層面完整復制人腦的設想,雖然理論上是可行的,但在沒有找個更高效的方法之前,現階段暫時實作不了。
那如果退而求其次,采用第二種方式, 用文本資訊建模, 來模擬一個人的思維結構和特征呢?
人腦大模型
與全實體層面的模擬相比,文本建模似乎是一個更實際可行的替代方案,但是在還原度方面,相較前者而言,實在是有些拉胯……
首先,並不是每個人生前都能留下足夠數量、質素的文本資訊,如果沒有足夠的文本資訊可供學習,訓練出模型的發言就會比較「大路貨」,即便從感官上也無法給我們「這就是那個人」的感覺。
另外,要還原出這個人在各種特定場景下的行為反應、決策判斷等高級認知功能,光用通用的語意關聯可就難辦了,你得針對具體場景做大量訓練,緩解模型偏差。
更關鍵的是,你怎麽保證經過AI建模後的這個系統,真的還能完整繼承逝者的「自我意識」,而不只是個簡單的模仿機器?
要完整繼承一個人的"自我意識",可不止是學習表面的語言和行為那麽簡單。
因為自我意識是一種內在的、高級的心智狀態,包括自我認知、情緒體驗等等, 這些隱藏在內心深處的東西,單純從文字記錄是很難捕捉到的。
比如同樣是說一個「哦」,有時候是表達同意,有時候是漠不關心,甚至有時候是在生氣。
說白了,意識活動太過復雜抽象,不是簡單的語言數據就能還原的。
這是僅有表象的 「數碼皮囊」和真正的「數碼生命」之間的關鍵區別。
就目前來看,在打造數碼生命這件事上,物理建模還原度高,但可行性低,文本建模可行性挺高,但還原度又拉胯。
既然二者各有長短,那何不試著將兩種方式融合一下?
最近還真出現了個類似的技術,名叫 DeWave模型。
這個模型的特點,用一句話來說,就是 透過大模型讀取你的想法,並直接轉化成文本。
今年一月,悉尼科技大學的科研人員,透過大語言模型、EEG(大腦活動檢測工具)、腦機介面等技術,開發了一個可自動讀取人類想法,並轉化成文本的AI大模型——DeWave。
這相當於是AI版的「讀心術」了。

DeWave的核心是利用EEG(腦電圖)等器材,直接捕捉大腦的神經活動訊號,作為實體層面的輸入資料來源。
然後DeWave會把這些特征向量再次轉化,變成一串串的離散編碼,這相當於把你的大腦活動給轉換成了機器能讀懂的一堆特殊密碼。
接下來就簡單了,DeWave直接把這些"大腦密碼"丟進一個訓練好的大模型裏,經過模型的「轉譯」,最終就能將你大腦裏的想法,化作人話給生成出來了!
與單純依賴文本不同,DeWave直接從人腦獲取物理訊號,所以在還原度上更有優勢。
就目前來說,DeWave在ZuCo數據集上的表現,用眼動標記的EEG訊號,拿到了41.35的BLEU分數和33.71的ROUGE分數。
這個測試就是為了檢驗DeWave這種直接讀腦的轉譯模型的精確度有多高,看它能不能真正做到"讀心術"把人腦子裏的想法解碼出來。
其中BLEU是評估機器轉譯整體準確性的指標,分數越高說明還原性越好。
而ROUGE分數則更關註重點和關鍵資訊,要是重點漏了太多,分數就高不了了。
之前類似的技術,例如Wave2Vec,這玩意兒本來是用來辨識語音的,後來有人把它改了改,用來辨識大腦訊號。但是,它在同樣的數據集上,BLEU分數只有18.15,ROUGE分數是23.86。
這麽一比,DeWave的表現就是甩了前者好幾條街。
想象一下,倘若在未來,DeWave這類技術更上了一層樓,任何人要想對自己的思維建模,只需要戴上EEG器材一段時間,記錄下自己在各種情況下的思維、想法,之後將其解讀和轉譯,匯入大模型,並進行思維建模,一個完整的「人格拷貝」就誕生了!
而這樣的「人格拷貝」, 這著實和【賽博龐克2077】中,荒阪公司研究的所謂「靈魂殺手」芯片有些相似, 後者就是用來獲取和備份人類意識的一種黑科技裝置。

不過,這樣建模出來的數碼生命,也存在著一個問題,就是它是靜態的,它只能代表你帶上EEG器材的那段時間的水平,而真人是會學習和成長的。如果想讓這個思維模型像真人一樣,在經歷各種人和事之後,思想和心理也跟著變化成長,那人們就必須讓其具備「記憶」和「反思」的能力,讓其能夠透過一次次「前車之鑒」完善自己。
而要做到這點,就要提到另一個關鍵的技術—— SocioMind(數碼大腦) 。
數碼大腦
「人是所有社會關系的總和。」近期,新加坡南洋理工,商湯科技,上海 AI 實驗室共同推出的一個專案「Digital Life Project」(簡稱DLP),可以說忠實地踐行了這一思想。
專案裏有兩個主要部份:
SocioMind:這是一個數碼化的「大腦」,用來模擬角色的個性和社交行為。
MoMat-MoGen:這是一個讓角色的數碼化身體動起來的方法。
其中的 SocioMind就是剛才提到的讓思維模型學會「前車之鑒」的關鍵。

簡單來說,SocioMind就是一個智能社交系統,能讓虛擬角色(數碼生命)根據過去的經歷和對話,模擬出具有人類特征的社交反應和情感變化。
就像我們在現實中,與各色人等打交道多了,就逐漸學會了為人處事之道,知道如何應對不同的社交場景,SocioMind也在幫助虛擬角色「學習」如何在虛擬世界裏,怎麽透過一次次的交流,變得更像個真實的人。
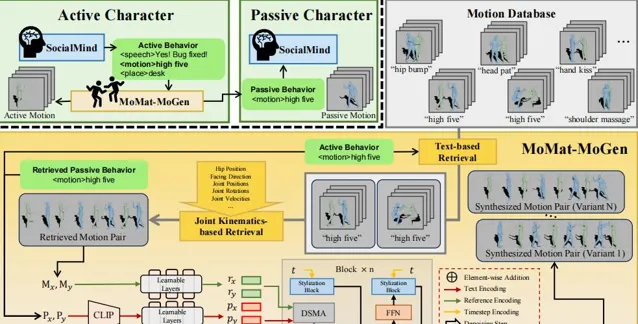
具體地說,SocioMind大致是透過如下步驟,讓數碼生命學會「記憶」和「反思」的。
首先,SocioMind會根據角色的「背景故事」來塑造其個性。 相當於是各類RPG遊戲裏的「建立角色」的環節, 這一步決定了「數碼人格」各方面的基礎值,例如一個樂觀的角色可能會積極的態度,一個內向的角色可能會更加謹慎。
之後,SocioMind為每個虛擬角色構建了一個記憶系統,記錄角色在互動中的經歷,以及基於這些經歷產生的想法,相當於是讓角色有了個 「聊天記錄」 。
雖然嘛,聊天記錄這東西很多系統都有,但SocioMind關鍵的地方,就在於它不僅會保存這些記錄,還能進行 深度理解與上下文關聯。
透過深度學習和自然語言處理技術(NLP),角色能理解各種資訊的含義和背後的情感。
最後,更關鍵的是,基於這樣的深度理解,角色還能透過一系列復雜的演算法, 衍生出動態的適應和學習機制, 而非公式化的機械反應。
舉例來說,如果角色A和B吵了架,按照某種公式化的反應,下次A再見到B,一定會對B很反感。
但現實中的人性是多維和復雜的,假設A是一個寬容的角色,她可能剛開始會反感,但隨著時間推移,反感就沒那麽強烈了。
如果A在爭論後得到了朋友的安慰,或者A自己反思後,認為爭論是不必要的,那麽她對B的態度可能會有所緩和。
而SocioMind正是 透過建立了一個情緒和社交模型,模擬了這種復雜性、動態性。
這個模型,就像一個不斷生長,不斷分叉的樹枝,這棵樹的每個分支代表了角色在社互動動中的一個可能的路徑或結果。
而角色每經歷一件事,或是做出一個不同的選擇,就會導致新的分支生長出來。
隨著時間的推移,角色的個性和情感狀態就像這棵樹的枝葉一樣越來越豐富,形成了一個復雜的結構。
與完全模擬人腦神經元互動的方式相比,這種基因社交理論的技術路徑,成本要低太多,可行性也要高太多了。
加上前面提到的DeWave技術,人們幾乎就有了一套將思想轉譯、匯入、建模並且讓其「活過來」的完整技術路徑。
不過,話說回來,比怎麽實作「數碼生命」更重要的,是 實作了數碼生命以後,它對人類究竟有什麽意義?
這個問題,就目前來說,至少有兩個答案。
其一,從淺層的意義來看,這種真正有靈魂,有思想的數碼生命, 對娛樂業的推動可是大大的。
在電影、遊戲、小說等領域,這些沒有肉身,不會疲勞的數碼生命,可以作為互動角色參與創作,提供更加個人化和另類的體驗。
其二,從更深、更遠的層次來看,這樣的「數碼備份」,實際上可以 當成人類的「集體智慧庫」的組成部份。
中國有句古話:「吾生也有涯,而知也無涯 。以有涯隨無涯,殆已!」
一個人的生命,總是有限的,而 在這有限的生命裏,每個人所能承載和反芻出來知識,也是有限的。
但倘若將來數碼生命成真了,在無限壽命的情況下,一個人究竟能學多少知識,又能凝結出多少智慧?
更不用說,在擺脫了生物大腦的限制後,這些數碼生命的學習效率有多快。
倘若千萬個這樣的數碼生命匯集到一起,人類是否就能湧現出一種更高級,更強大的智慧了?
Emmm……對於這個問題,只能說,有時候比科技更先撞到南墻的,是人類的想象力。
畢竟,即使數碼生命前景再光明,目前人們最先想到的,還是用它搞「復活」業務,從死者身上賺錢。











