界面新聞記者 | 於浩 伍洋宇
界面新聞編輯 | 文姝琪
憑借「長文本」標簽,月之暗面從國內一眾AI大模型公司中脫穎而出,打破了這個行業在產品上大同小異、技術上難分伯仲的刻板印象。
去年10月,由楊植麟創辦的月之暗面釋出首款大模型產品智能助手Kimi Chat,將上下文視窗長度擴充套件至20萬字。彼時,Anthropic的Claude2-100k和OpenAI的GPT4-32k支持的最長文本分別為100K(約8萬漢字)和32K(約2.5萬漢字),Kimi是這兩者的2.5倍和8倍。
這一步踩對了C端(使用者端)需求的節奏,大模型技術規模化套用的可能性被刻畫出更清晰路徑。使用者蜂擁而至,Kimi日活使用者從10萬規模直逼百萬量級。
一把火扔進了迷霧中的行業,此前喧囂沸騰但遲遲找不到亮光的競爭者紛紛卷入「長文本」浪潮,百川智能的Baichuan2-192K(約35萬漢字)、零一萬物的Yi-34B(約40萬漢字)等大模型先後打破Kimi的記錄。
但不等半年時間,Kimi重新奪回主動權,並將風浪掀得更高。
3月18日,Kimi將上下文輸入限制突破至200萬漢字。這輪熱度一度致其小程式宕機,甚至於在二級市場形成Kimi概念股板塊,一家創業公司左右資本情緒的戲碼罕見上演。互聯網大廠亦開始明牌上桌,阿裏通義千問開放1000萬字長文件處理功能,百度文心一言也即將釋放200萬至500萬長度處理能力。
長文本戰場的火藥味漸濃,但長文本是否有極限?它對實作AGI(通用人工智能)和大模型技術的套用層繁榮有什麽意義?在這場行動陷入無意義漩渦之前,行業理應對此抱有答案。
直面技術矛盾
由上下文視窗長度所決定的長文本能力是指,語言模型在進行預測或生成文本時,所考慮的前一個詞元(Token)或文本片段的大小範圍。
上下文視窗越大,大模型可以獲得的語意資訊也越豐富,有助於消除歧義、生成更加準確的文本。雲從科技技術管理部負責人在接受界面新聞采訪時表示,以長上下文為重點突破更加貼近人類記憶的特點,相當於擴充套件了AI的記憶庫,讓AI可以參考更多歷史記憶資訊,給出更準確的輸出。
對於多輪對話、長文件處理等場景中,一定長度的上下文視窗是大模型能否高質素完成交流的必要條件。在基礎大模型頻繁叠代的2023年,長文本能力也一直是主流大模型廠商關註的焦點。
但是上下文視窗、模型智能水平、算力成本之間始終存在著矛盾。
Transformer架構中的註意力機制,需要消耗算力來計算Token與Token之間的相對註意力權重。當上下文視窗顯著增大時,模型每次可以處理的文本範圍變得更廣,但這也意味著每次處理所需的計算資源會大幅增加。因此,盡管每次處理的文本量更大,但由於算力資源限制,模型在整個生命周期內能夠處理的總Token數量會減少,導致模型的理解能力下降。
針對這一點,學界自2019年起便開始針對「efficient Transformer」(高效Transformer)為目標進行研究,也出現了諸如稀疏註意力機制等解決方案。核心思路在於透過限制模型必須計算的關系數量,減少計算負擔和儲存需求,從而提高處理長序列時的效率。
「未來真正要追求無失真長文本以及高效推理的話,那改進Transformer架構使其更高效還是很必要的。」波形智能CTO周王春澍表示。
即便是在模型本身的上下文視窗受限的前提下,業內也存在著RAG(Retrieval-Augmented Generation,檢索增強生成)等技術路線來實作與超長文本能力類似的效果。即,使用檢索系統從一個大型的文件集合中檢索出與輸入序列相關的文件,然後將這些文件作為上下文資訊輸入到生成模型中,以輔助生成過程。
在通義千問打出1000萬字的長文件處理功能、360預告500萬字的長文件處理能力後,一個業內普遍存在的推測就是,這類功能是透過RAG輔助之後,基於基座模型本身的上下文視窗實作的;如果由大模型完成千萬漢字長文本的處理,那所耗費的算力資源會相當驚人,不具備商用價值。
月之暗面在這輪「長文本之爭」的特殊之處在於,楊植麟此前在接受采訪時曾明確表示,不會采用小模型、降采樣、滑動視窗等形式來提升上下文視窗。在200萬字上下文對外釋出時,月之暗面工程副總裁許欣然也多次強調,此次上下文長度的提升是「無失真」前提下進行的,不會影響模型的智能水平。
在Kimi宣布將上下文視窗拓展至200萬漢字時,Anthropic所釋出的Claude3上下文視窗為200K(Claude2 100K上下文視窗實測約8萬漢字),百川智能釋出Baichuan2-192K大模型能夠一次處理約35萬個漢字。從這一點上看,Kimi站穩了長文本能力這一產品定位。
Gangtise投研分析師表示,目前Kimi模型的日活躍使用者數已達100萬人,預計月活躍使用者數約為500萬人。其中小程式端日活躍使用者數達60萬人,網頁端達34萬人,APP端達5萬人,留存率也在持續上漲。若Kimi模型保持當前增長趨勢,小程式端市場地位可能顯著提升。
角逐長文本的意義
從基礎模型本身的上下文視窗來看,Kimi在一眾大模型廠商中表現突出。但從長線來看,這能否構成核心壁壘仍有待討論。
除去演算法層面的最佳化,多位從業者告訴界面新聞,拓展上下文視窗的另一個限制在於視訊記憶體容量與視訊記憶體頻寬。
「這其實是一個工程最佳化的問題。」周王春澍說,在計算資源相同的前提下,上下文視窗的增大會對能夠處理的Token數產生影響。換言之,增加計算資源或者使計算資源的利用更高效,是達成長上下文視窗的最直接方案。
受Kimi模型的火熱市場反應影響,阿裏通義千問、百度文心一言、360迅速公布或預告自己的長文件處理功能。盡管在業內的普遍猜測中,上述產品的長文件處理能力是出自RAG輔助的結果,但是實際效果也證實RAG的路線能夠實作與超長文本能力相近的效果。
「如果能確保知識定位的準確性,比如長文本的Chunking(分塊)做的比較好、RAG工程最佳化也比較好的話,其實在涉及到一些推理的Benchmark(基準)上,RAG和長下文的方案在效果上沒有本質性的區別。」周王春澍說。
在C端場景中,百萬字級別的長文本能力可以延伸出財報解讀、總結論文等多種需求,但是在更為廣泛的B端(企業端)場景,模型本身過於長的上下文視窗反而會成為ROI的負累。
「上下文再長也不大可能長過動輒GB、TB級別的企業級數據,」葉懋認為,「在私有化部署過程中,長上下文很難一下覆蓋這些非結構化數據,即使能覆蓋,響應速度和算力需求方面的問題也會更加突出。」
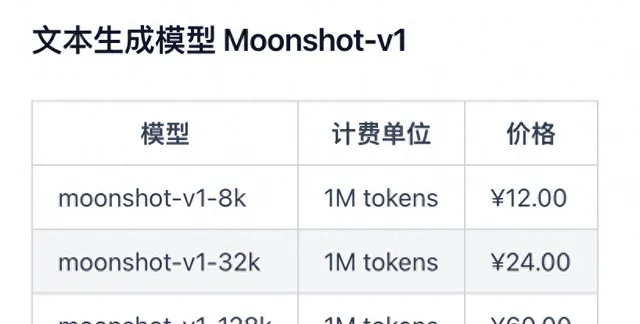
月之暗面官網顯示,大致來說,對於一段通常的中文文本,1Token大約相當於1.5至2個漢字。如果按200萬字粗略計算,使用moonshot-v1-128k的API介面的費用約在60元左右。而據周王春澍所說,如果使用RAG方案,可能需要的成本就只在一分錢或者一毛錢以內。
RAG與長文本能力之間的補足關系在B端場景中體現得尤為明顯。在波形智能的商業實踐中,與200K左右上下文視窗的模型方案相比,企業客戶更傾向於選擇RAG外掛數據庫+8K左右上下文視窗的模型方案。
「在使用量比較多的場景下,很難想象大家會完全拋棄RAG,然後把上下文全給用起來。」周王春澍將RAG與長文本能力形容作個人電腦領域的CPU快取和記憶體,兩者相互配合完成運算任務。
而當一種更具性價比、且效果相近的方案存在時,基礎模型是否有必要持續擴充上下文視窗就成了有待考慮的問題。
誠然,在追求AGI的路上,足夠長的上下文視窗必不可少,但在目前這個階段,成本、效能與長文本之間的「不可能三角」也確實為長上下文視窗的基礎模型的實用性打上了問號。
一名關註AI大模型技術領域的投資人表示,當他看見行業出現這種普遍表征的時候,內心實感是各家公司確實在為搶入頭部陣營做成績,但這件事本質上還是「秀肌肉」。
如果真的要對估值增長產生實際影響,可能還是要等到更明確的落地場景和對應的商業模式出現,「否則市場再熱鬧也是沒有用的。」











