編輯:編輯部
【新智元導讀】 大模型格局,再次一夜變天。Llama 3.1 405B重磅登場,在多項測試中一舉超越GPT-4o和Claude 3.5 Sonnet。史上首次,開源模型擊敗當今最強閉源模型。小紮大膽豪言:開源AI必將勝出,就如Linux最終取得了勝利。
開源新王Llama 3.1 405B,昨夜正式上線!
在多項基準測試中,GPT-4o和Claude 3.5 Sonnet都被超越。也即是說,閉源 SOTA 模型,已經在被開源模型趕上。
一夜之間,Llama 3.1 405B已成世界最強大模型。
(同時上線的,還有新版70B和8B模型)
LeCun總結了Llama 3.1模型家族的幾大要點:
- 405B的效能,與最好的閉源模型效能相當
- 開源/免費使用權重和程式碼,允許進行微調、蒸餾到其他模型中,以及在任何地方部署
- 128k的上下文,多語言,良好的程式碼生成能力,復雜推理能力,以及工具使用能力
- Llama Stack API可以輕松整合
Meta這次可謂是將開源的精神貫徹到底,同時大方放出的,還有一篇90多頁的論文。
HuggingFace首席科學家 Thomas Wolf 贊賞道:如果想從0開始研究大模型,你需要的就是這篇paper!
它簡直無所不包——預訓練數據、過濾、退火、合成數據、縮放定律、基礎設施、並列處理、訓練方法、訓練後適應、工具使用、基準測試、推理策略、量化、視覺、語音和影片……
AI2的研究員Nathan Lambert估計,這份90頁的Llama 3.1論文,將直接把開源模型的進展往前推上3-9個月!

Meta CEO小紮則自豪地寫下一篇長文:開源人工智能是前進的道路。
 在紐約時報的采訪中,小紮力挺開源AI
在紐約時報的采訪中,小紮力挺開源AI
在這篇文章中,小紮感慨地回憶了Meta在LLM浪潮中的翻身之路——
去年,Llama 2只能與邊緣的舊模型相提並論;今年,Llama 3在某些方面已經領先於最先進的模型;明年開始,未來的Llama模型將成為最先進的模型。
對於自己被多次問到的「是否擔心開源Llama而失去技術優勢」,小紮直接以Linux自比。
他表示,曾經大科技公司都大力投資於自己的Unix版本,然而最終還是開源Linux勝出了,因為它允許開發者隨意修改程式碼,更先進、更安全、生態更廣泛。
AI,也必將以類似方式發展。
為此,Meta特地放寬了自己的特許,首次允許開發者使用Llama 3.1模型的高質素輸出,來改進和開發第三方AI模型。

網友:一個新時代開始
Llama 3.1正式解禁後,在全網掀起軒然大波。
AI大神Karpathy隨即發表了一些自己的感想:
今天,隨著405B模型的釋出,GPT-4/Claude 3.5 Sonnet級別的前沿大模型首次對所有人開放供大家使用和構建。。其權重開源,商用特許、允許生成合成數據、蒸餾和微調模型。
這是Meta釋出的一個真正開放的前沿LLM。除此以外,他們還放出了長達92頁的技術報告,其中包含有大量模型細節: https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
這次模型釋出背後的理念,在小紮的一篇長文中有詳細闡述,非常值得一讀,因為它很好地涵蓋了支持開放AI生態系世界觀的所有主要觀點和論點:
開源AI是未來。
我常說,現在仍處於早期階段,就像電腦發展的1980年代重現一樣,LLM是下一個重要的計算範式,而Meta顯然正定位自己為其開放生態系的領導者。
- 人們將對這些模型進行提示和使用 RAG
- 人們將對模型進行微調
- 人們將把它們蒸餾成更小的專家模型,用於特定任務和套用
- 人們對其進行研究、基準測試、最佳化
另外,開放生態系還以模組化的方式自組織成產品、套用和服務,每個參與方都可以貢獻自己的獨特專業知識。
一個例子是,AI芯片初創Groq已經整合了Llama 3.1模型,幾乎能實作8B模型瞬間推理。
Karpathy稱,由於伺服器壓力,自己似乎無法嘗試執行在Groq上的405B可能是今天能力最強、最快的大模型。

他還預計,閉源模型們很快就會追趕上來,並對此非常期待。
Meta研究員田淵棟稱,一個新的時代已經開始!開源LLM現在與閉源LLM不相上下/更勝一籌!

開源模型新王者誕生了。
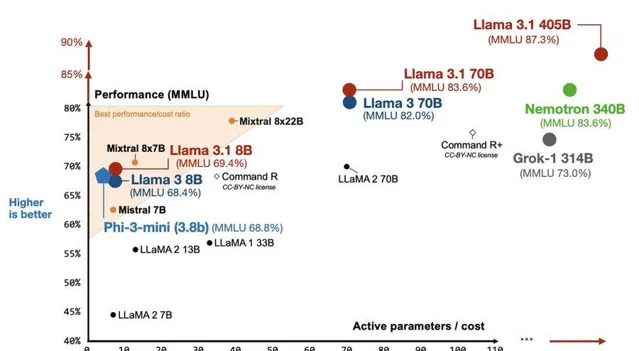
OpenPipe創始人在測試完經過微調的Llama 3.1 8B後感慨道:從未有過如此小且如此強大的開源模型——它在每個任務上的表現都優於GPT-4o mini!
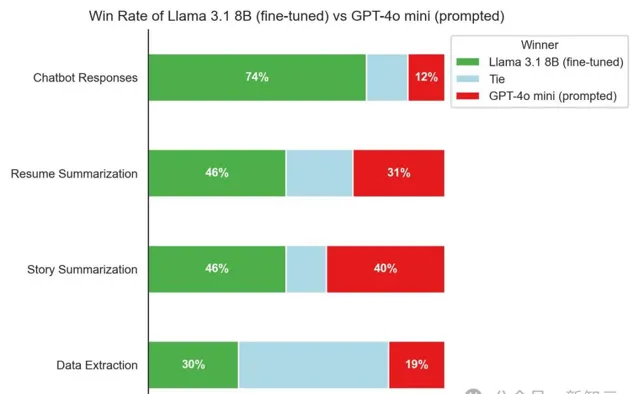
輝達高級科學家Jim Fan表示,GPT-4的力量就在我們手中。這是一個具有歷史性意義的時刻。

鮮有人關註AI模型訓練背後的基礎設施,Pytorch之父Soumith Chintala站出來表示,在16000塊GPU搭建的設施中,也會遇到失敗的時候。
這些細節都藏在了Llama 3.1的論文中,包括如何並列化、保持系統可靠性。值得一提的是,Meta團隊在模型訓練中實作了90%的有效訓練時間。

有網友細數了Llama模型叠代過程中,GPU的用量也在不斷增長。
Llama 1:2048塊GPU
Llama 2:4096塊GPU
Llama 3.1:16384塊GPU(其實,Llama 3是在兩個擁有24,000塊GPU集群完成訓練)
Llama 4:......

最強開源模型家族
其實,關於Llama 3.1系列模型一些要點,在昨天基本上被劇透得體無完膚了。
正如泄露資訊所述,Llama 3.1可以支持8種語言(英語,德語、法語、意大利語、葡萄牙語、印地語、西班牙語和泰語),多語言對話智能體、轉譯用例等。
在上下文長度上,比起Llama 2、Llama 3,Llama 3.1系列模型中所有上下文增加了16倍,為128K。

Meta強調,Llama 3.1還在工具使用方面得到了改進,支持零樣本工具使用,包括網絡搜尋、數學運算和程式碼執行。
基於長上下文,模型不僅知道何時使用工具,還能理解如何使用以及如何解釋結果。
此外, 透過微調,Llama 3.1在呼叫自訂工具方面提供了強大的靈活性。

主要能力
首先,Llama 3.1可以作為一個能夠執行「智能體」任務的系統來執行:
- 分解任務並進行多步驟推理
- 使用工具
- 內建工具:模型內建對搜尋或程式碼直譯器等工具的知識
- 零樣本學習:模型可以透過以前未見過的上下文工具定義來學會呼叫工具
比如問模型:「這是一個CSV檔,你可以描述它裏面有什麽嗎?」
它會辨識出:這份CSV檔包含了多年的每月 通貨膨脹率 ,年份一欄表示了每組每月通貨膨脹率的年份。
接下來,我們可以要求它按時間序列繪制圖表。
接下來,它還能完成一系列刁鉆的任務,比如在同一圖表中繪制S&P500的走勢圖。
完成之後,還能重新調整圖表,把資訊加到不同的座標軸上。
如上所示,Llama 3.1支持8種語言,因此可以勝任多語言的轉譯。
我們可以讓它將童話故事【漢澤爾與格萊特】(糖果屋)轉譯成西班牙語。
即使面對比較復雜的推理題,Llama 3.1也能輕松拿下。
「我有3件襯衫、5條短褲和1條連衣裙。我要出行10天,這些衣服夠我度假用嗎」?
AI將已知的條件,進行分解,對上衣、短褲、裙子設想了一個合理的搭配方案,並建議最好多帶幾件上衣。

在推理完成後,它還貼心地為我們提供了更詳細的出行穿衣指南、行李清單。

我們還可以讓AI手寫程式碼。
比如讓它建立一個程式,使用遞迴回溯演算法或深度優先搜尋演算法生成一個完美迷宮,並且可以自訂大小和復雜度。
只見AI一上手,直出迷宮程式的Python程式碼。

程式碼完成後,AI還給出了詳細的解釋。

再接下來,若想自訂程式,AI程式碼助手為我們提供了相應的程式碼建議——調整寬度和高度。

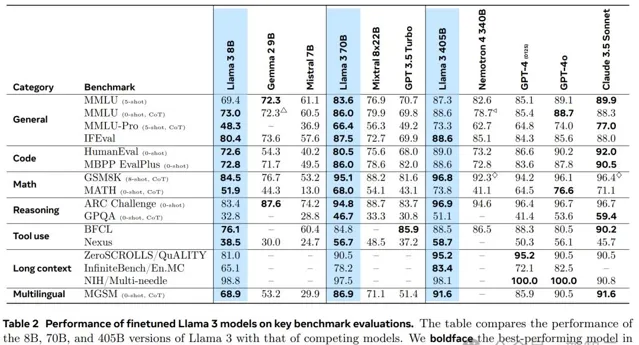
評測結果
為了評估Llama3.1的表現,Meta不僅在測試中囊括了150個涵蓋多語種的基準數據集,並且還在真實場景中進行了比較。
在多種任務中,405B都可以和GPT-4、GPT-4o、Claude 3.5 Sonnet等閉源領先模型掰手腕。

而8B和70B的小模型,在參數量相似的閉源和開源模型中,同樣表現出色。
除了長上下文任務,8B和70B模型在通用任務、程式碼、數學、推理、工具使用、多語言上,取得了SOTA。

人類評估中,Llama 3.1 405B模型與GPT-4不相上下,但略遜於GPT-4o。
不過,在與Claude 3.5 Sonnet相較下,405B大模型更有優勢,勝率為24.9%。

此外,在Scale的排行榜中,Llama 3.1 405B微調版本在指令跟隨評估中,碾壓Claude 3.5 Sonnet、GPT-4o。
在數學任務中,405B僅次於Claude 3.5 Sonnet,位列第二。不過,Llama 3.1在程式碼任務上,得分相對較低。

92頁超詳技術報告
沒有誰能夠像Meta一樣開源徹底,92頁超長技術報告,也在今天一並放出。
論文地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
論文提出,Llama 3.1這種高質素的基座模型有3個關鍵杠桿:數據、規模以及復雜度管理。
數據方面,相比前代,Llama 3.1的數據總量和質素都有所提高,比如對預訓練數據更仔細的預處理和管理管道,以及對訓練後數據更嚴格的質素保證和過濾方法。
Llama 2僅在1.8T token的數據上進行預訓練,而Llama 3.1的多語言預訓練語料則達到了15.6T token,有超過8倍的增長。
規模方面,Llama 3.1的訓練使用了超過1.6萬個輝達p00 GPU,計算總量達到3.8e25 FLOPS,幾乎是Llama 2的50×。
為了更好地實作「scale up」,論文特別提出了「復雜度管理」這個方面。在選擇模型架構和演算法時,需要更關註其穩定性和可延伸性。
值得關註的是,Llama 3.1並沒有使用最受關註的MoE架構,而是decoder-only架構的稠密Transformer,僅將原始的Transformer架構進行過一些修改和調整,以最大化訓練穩定性。
類似的做法還有,使用SFT、RS、DPO等簡潔的訓練後流程,而不是更復雜的強化學習演算法。
和許多大模型類似,Llama 3的開發也主要包括兩個階段:預訓練和後訓練。
預訓練時同樣使用「預測下一個token」作為訓練目標,首先將上下文視窗設定為8K,之後在繼續預訓練階段擴充套件到128K。
後訓練階段透過多個輪次叠代的人類反饋來改進模型,顯著提升了編碼和推理效能,並整合了工具使用的能力。
此外,論文還嘗試使用3個額外階段為Llama 3.1添加影像、影片、語音等多模態功能:
- 多模態編碼器預訓練:影像和語音的編碼器分開訓練,前者的預訓練數據是影像-文本對,後者則采用自監督方法,嘗試透過離散化的token重建語音中被掩碼的部份。
- 視覺介面卡:由一系列跨註意力層組成,將影像編碼器的表示註入到經過預訓練的語言模型中。以影像為基礎,論文還嘗試在影片-文本對上訓練了影片介面卡。
- 語音介面卡:連線語音編碼器和語言模型,此外還整合了「文本到語音」系統。

遺憾的是,上述的多模態功能依舊在開發階段,因此沒有包含在新釋出的Llama 3.1中。
模型架構
Llama 3.1依舊使用標準的稠密Transformer,與Llama和Llama 2在架構方面並沒有顯著差異,效能的改進主要來自訓練數據質素、多樣性的提升,以及規模擴充套件。

與Llama 3相比,Llama 3.1的架構有以下改進:
- 分組查詢註意力(GQA):帶有8個鍵-值頭,提升推理速度並減少解碼時的KV緩存
- 註意力掩碼:防止同一序列中不同文件之間出現自註意力。這個技巧在標準預訓練中效果有限,但對很長的序列進行繼續預訓練時非常重要
- 128K token詞表:包括tiktoken中的100K以及額外的28K,以更好支持非英語語言。與Llama 2相比,同時提高了英語和非英語的壓縮比率
- 將 RoPE 的超參數θ設定為500,000:更好支持長上下文
模型的關鍵超參數如表3所示,基於數據量和訓練算力,模型的大小達到了Scaling Law所揭示的算力最佳化。

並列效率
要在1.6萬張GPU上訓練405B的模型,僅僅是考慮並列和故障處理,就已經是一個大工程了。
除了模型本身,論文對訓練過程使用的並列化方案,以及儲存、網絡等基礎設施都進行了闡述。
Llama 3.1的訓練采用4D並列(張量+流水線+上下文+數據),在BF16精度下,GPU利用率(MFU)約為38%~41%。

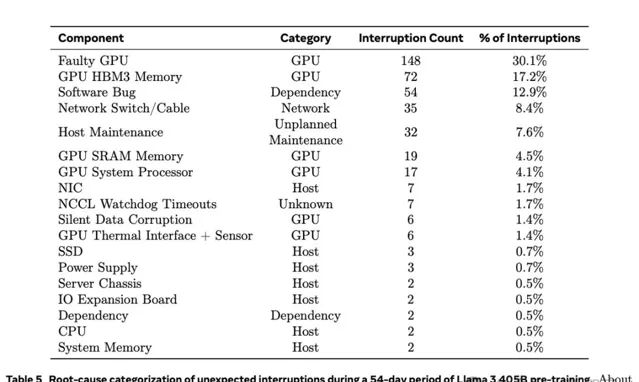
Llama 3.1訓練集群的故障處理也十分出色,達到了超過90%的有效訓練時間,但這依舊意味著,總共54天的預訓練過程中,每天都至少有一次中斷。
論文將全部419次意外中斷的故障原因都詳細列出(表5),對未來的GPU集群搭建有非常重要的借鑒意義。其中確認或懷疑與硬件相關的問題占比達到了78%。

由於集群的自動化運維比較完善,盡管故障次數多,但大部份都可以被自動處理。整個過程中,只有3次故障需要手動幹預。
提高特定能力的效能
程式碼
為了提高模型的編碼能力,Meta采用了訓練程式碼專家、生成SFT合成數據、透過系統提示引導改進格式,以及建立質素過濾器(從訓練數據中刪除不良樣本)等方法。
使用Llama 3將Python程式碼(左)轉換為PHP程式碼(右),以使用更廣泛的程式語言來擴充SFT數據集
透過系統提升,讓程式碼質素提高。左:無系統提示 右:有系統提示
多語種
為了提高Llama 3的多語種能力,Meta專門訓練了一個能夠處理更多多語言數據的專家,從而獲取和生成高質素的多語言指令微調數據(如德語、法語、意大利語、葡萄牙語、印地語、西班牙語和泰語),並解決多語言引導中的特定挑戰。

數學推理
訓練擅長數學推理的模型,面臨著幾大挑戰,比如缺乏提示、缺乏真實的CoT、不正確的中間步驟、需要教模型使用外部工具、訓練和推理之間的差異等。
為此,Meta采用了以下方法:解決提示不足問題、增強訓練數據中的逐步推理過程、過濾錯誤的推理過程、結合程式碼和文本推理、從反饋和錯誤中學習。

長上下文
在最後的預訓練階段,Meta將Llama 3的上下文長度從8K token擴充套件到128K。
在實踐中團隊發現,如果僅使用短上下文數據進行SFT,會導致模型長上下文能力顯著退化;而閱讀冗長的上下文非常乏味、耗時,所以讓人類標註此類範例也是不切實際的。
因此,Meta選擇了合成數據來填補這一空白。
他們使用Llama 3的早期版本,生成了基於關鍵長上下文用例的合成數據:(多輪)問答、長文件摘要、程式碼庫推理。
工具使用
Meta訓練了Llama 3與搜尋引擎、Python直譯器、數學計算引擎互動。
在開發過程中,隨著Llama 3的逐步改進,Meta也逐漸復混成了人工標註協定。從單輪工具使用標註開始,轉向對話中的工具使用,最後進行多步工具使用和數據分析的標註。
Llama 3執行多步驟規劃、推理和工具呼叫來解決任務
基於提供檔,要求模型總結檔內容、尋找並修復錯誤、最佳化程式碼、執行數據分析或視覺化等
事實性
對於LLM的公認挑戰幻覺問題,Meta采取了幻覺優先的方法。
他們遵循的原則是,訓練後應該使模型「知道它知道什麽」,而不是添加知識。
可操縱性
對於Llama 3,Meta透過帶有自然語言指令的系統提示,來增強其可操縱性,特別是在響應長度、格式、語氣和角色/人格方面。
「你是一個樂於助人、開朗的AI聊天機器人,為忙碌的家庭充當膳食計劃助手」
團隊成員
Llama 3的團隊可以說非常龐大,單核心成員而言就達到了差不多220人,其他貢獻者也有312人之多。



小紮:開源AI是未來
眾所周知,小紮一直是開源AI的忠誠擁躉者。
這次不僅是釋出一個新的最強模型那麽簡單,而是誓要讓開源AI走上神壇。

在網誌中,小紮直接以史為鑒,曾經,各大科技公司都投入巨資埋頭開發封閉源Unix版本。
Unix戰場打得火熱,沒想到笑到最後的卻是開源的Linux。

Linux最初是因為它允許開發者隨意修改程式碼,並且價格更實惠,廣受開發者青睞。
但隨著時間的推移,它變得更加先進、更安全,並且擁有比任何封閉的Unix更廣泛的生態系支持更多的功能。
今天,Linux已成為雲端運算和大多數流動通訊器材作業系統的行業標準,而所有人都因此受益。
小紮相信,AI的發展軌跡也將如此,並且將矛頭直指「幾家科技公司」的閉源模型。

「今天,幾家科技公司正在開發領先的封閉模型,但開源正在迅速縮小差距。」
小紮敢直接點名自然有他的實力作為底氣,去年,Llama 2還落後於前沿的舊一代模型。
而今年,Llama 3在效能方面已經能與其他巨頭大模型分庭抗禮了。
Llama 3.1 405B作為第一個前沿級別的開源AI模型,除了相對於封閉模型顯著更好的成本/效能比之外,405B模型的開放性使其成為微調和蒸餾小型模型的最佳選擇。
為什麽開源AI對開發者有益?
對於開發者來說,堅持開源模型有五大好處:
第一,開源模型允許開發者自由地訓練、微調和蒸餾自己的模型。
每個開發者的需求不同,器材上的任務和分類任務需要小模型,而更復雜的任務則需要大模型。
利用最先進的開源模型,開發者可以用自己的數據繼續訓練,並蒸餾成理想大小。
第二,可以避免被單一供應商限制。
開發者不希望依賴於自己無法執行和控制的模型,也不希望供應商改變模型、修改使用條款,甚至完全停止服務。
而開源使得模型可以輕松切換和部署,從而打造一個廣泛的生態系。
第三,保護數據安全。
開發者在處理敏感數據時,需要確保數據的安全,這就要求他們不能透過API發送給閉源模型。
眾所周知,由於開發過程更透明,因此開源軟件通常更安全。
第四,執行高效且成本更低。
開發者執行Llama 3.1 405B的推理成本只有GPT-4o的一半,無論是使用者端還是離線推理任務。
第五,長遠眼光來看,開源將成為全行業標準。
實際上,開源的發展速度比閉源模型更快,而開發者也希望能夠在長期具有優勢的架構上構建自己的系統。
在小紮看來,Llama 3.1的釋出將成為行業轉折點,讓開源變得愈發勢不可擋。











