今年5月, 北京大學與 銀河通用機器人 共同成立了「 北大-銀河通用具身智能聯合實驗室」,身為 北京大學前沿計算研究中心助理教授、博士生導師的王鶴擔任聯合實驗室主任。
在本月舉辦的WAIC 上 ,王鶴在「人形機器人與 具身智能發展論壇」上,發表了他對通用機器人發展現狀、商業套用及近期趨勢的思考。

(王鶴 / 圖片來源:智東西 )
「通用」的兩個維度
隨著NVIDIA Project GR00T的釋出,「通用機器人」這一概念的熱度隨之高漲。
在王鶴看來, 通用人形機器人要實作專用機器人不能做的柔性工作,滿足多樣任務的需求,並且能夠用自然語言來與人溝通。
「這些目標一旦達到,我們就實作了員工型的機器人,員工型機器人對未來中國制造業勞動力的巨大缺口,以及人口負增長時代的養老缺口,都將起到重要的彌合作用。」

他認為,「通用」可以分為兩個維度:
1、任務通用性: 機器人不能只做一件事情,而是至少在套用場景中完成N件事情,才能真正節省一個人力。
2、環境通用性: 不限於單一場景,而是可以跨場景、跨地形穿梭工作。
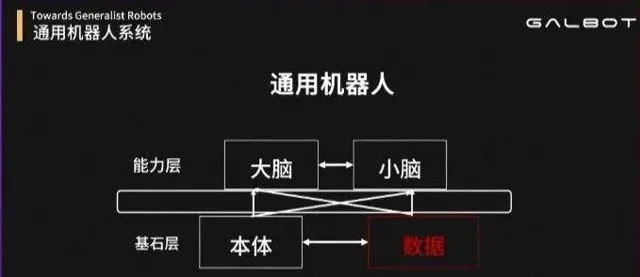
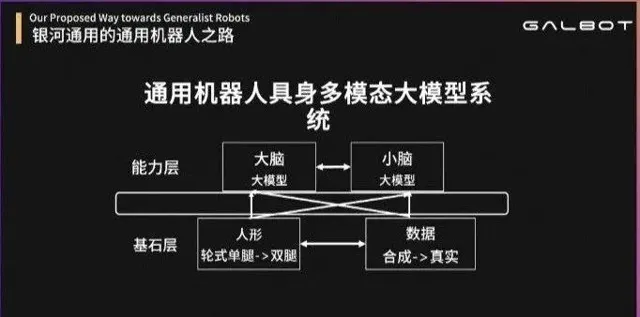
基於這兩點通用性,如今的研發工作要從本體層、數據層去考慮人形機器人的基石——基於本體和數據搭建通用機器人的大腦和小腦。
通用機器人的「體與腦」
王鶴從「四個元素」來講解了銀河通用機器人的思考: 本體、數據、大腦、小腦。
一、本體
顧名思義,人形機器人的形態與人類最為相似。
不過在未來,通用機器人也可能具備各種形態。不過最終,只有最大程度與人類工作需求相匹配的機器人,能夠得到最大的市場比重。
人形機器人可被拆分為上半身的雙手、雙臂、眼腦,以及下半身的雙腿。上半身是幹活兒的核心,主要是靠雙手和雙臂來做的;而雙腿就是為了實作環境通用,讓機器人穿梭於各個場景。
「還有一點大家可能沒有意識到:腿還有一個重要作用是輔助手——如果腿不能下蹲,手就摸不到地。也就是說, 腿能夠擴充套件手的工作空間,從地面一直到2m以上。

王鶴表示,這一點是腿式人形機器人的一大挑戰——除行走之外,類似彎腰撿、蹲下拿的能力比較欠缺,一系列腿部強化學習和能力有待發展。
「當物品從貨架上掉下來,如果人形機器人不能彎腰撿起,那這個場景就做不到閉環,也無法完整替代一個人的工作。所以在今天,甚至未來3年內,除了對成本的考慮之外,我們認為 人形機器人的下半身可以有其他的解決方案,及早實作全空間工作。 」
根據上述思考,銀河通用帶來的一個解決方案——機器人下半身透過一個360度的全相移動底盤,和把兩條腿並成一條腿,實作下蹲撿拾地下的物品。同時,機器人雙臂較長,能摸到2.4m的高處。

王鶴表示,這樣的設計成本,相對大多人形機器人的雙腿來說,非常低廉。同時,其工作空間和移動範圍可以達到人的水平。
「我們相信未來, 當腿的價格可以慢慢逼近輪,同時如果腿能夠實作穩定的下蹲、彎腰撿等技能,我們將迎來「全面人形」的切換時間點。 而在目前,我們更關註機器人上半身能否完成泛化工作,且整體形態能否支持在場景中完全閉環的作業需求。」
二、數據
如今的機器人,也同樣在以數據驅動,這也是與傳統機器人之間最大的區別。但數據同樣是當下通用機器人的一大挑戰。
在數據采集方式上,王鶴以特斯拉機器人舉例。他表示,Optimus把電池放進盒子裏的動作數據,是依靠戴著VR眼鏡看機械手采集數據。僅這一套動作,就需要出動40人的團隊進行采集。
「這種數據采集的成本能否支持它落地的時候的利潤? 如果我們替代了一個薪金5000元左右的人,但是一套動作的數據采集和神經網絡的訓練就耗費了幾百萬元,那這一商業模式是不是良性的? 這是人形機器人落地最大的挑戰。」
對此,銀河通用認為, 當下可以真正實作規模化量產的數據,就是合成數據。 王鶴表示,只有合成數據才是真正的「想要什麽就有什麽,想要多少就有多少。」
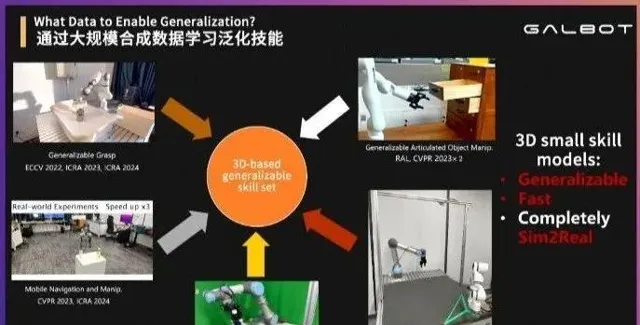
他介紹稱,透過合成數據,關於抓、握、拿等動作相關的標簽,都可以透過計算提前得到,並將海量大數據還給機器人。這種方式才能實作真正泛化,並弱化數據采整合本。
在史丹福大學讀博士期間,王鶴及團隊用了7年時間,利用合成數據克服了物理不一樣、控制不一樣和視覺感知不一樣等問題。如今,他們完全靠合成數據,透過視覺閉環反饋,實作泛化操作的大遷移。
「從我們訓練出來的效果看,對任意物體抓取已經形成了一定能力—— 對於透明物體來說,二維的傳感器有泛化問題,三維傳感器又看不見金屬高光的物體,需要完全靠合成數據,進行千萬場景、十億抓取的大規模合成。 今天真正銀河通用已經達到了對包括半透明物體在內的任何材質的完全泛化。這也給了我們信心——靠合成數據具身智能能夠完全0-1的突破。」
具身智能的Scaling law
據王鶴介紹,銀河通用去年合成了100萬的數據,今年落實得更徹底了,一口氣合成了10億。
他表示,有了這十億規模的靈巧手抓取數據加持,不僅能實作各種形態透明、高光材質,以及各種隨機堆疊物品的高穩定抓取,還能擴散模型,透過生成式大模型抓取各種各樣的東西。
這也使王鶴觀察到了具身智能的scaling law: 當用10億數據的時候,在仿真環境裏進行測試,能夠得到86%的成功率;但如果只用10萬數據的話,只有58%的成功率。
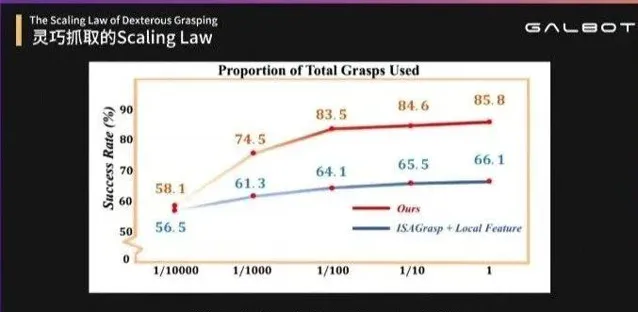
「靠遙操什麽時候能采到10億?而今天我們站在10億規模上,就可以做100億、1000億,這是銀河通用最大的技術特色,完全在合成數據在真實世界實作了泛化。「
基於這樣的合成數據基礎,銀河通用還訓練了端到端的大模型 。
目前端到端可達到的效果,也就是王鶴所說的「言出法隨「——讓機器人在陌生環境中根據指令行動,例如「直走到墻然後左轉,一直走到門然後停下」等等,機器人都能明白,這就是圖文動作大模型給予的泛化導航能力。
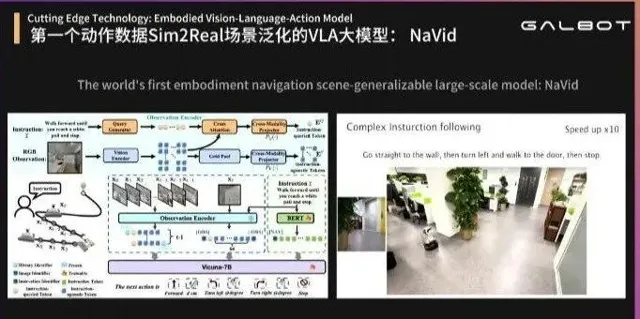
「這樣的數據背後是上百萬條合成的指令和機器人行走的軌跡,這如果只靠人工去采,什麽時候能采出來?」
AI機器人套用前景
在王鶴演示的影片中,基於端到端大模型的機器人,能根據「把‘卡皮巴拉’放在金屬杯子裏」的指令,將河豚玩偶放進制定位置。
「這些能力我們目前超過了Google的RT2系列,因為後者不能做到放什麽方向,只能放到位置上,而且Google是靠人力采集RT1的數據集,用17個月花費上千萬美元進行的數據采集。」
對於這樣的能力,王鶴描繪了一個套用場景——機器人在一排超市貨架上自動進行場景認知,拍照,並自動完成三維語意的建圖和位置理解。這樣它不僅能辨別超市中的商品位置,名稱類別,還能根據下單資訊取來商品。
根據王鶴的預判, 在具身智能基於合成數據,實作大小腦聯合之後,即將走向2B和B2C的各種場景。
「相信未來一兩年、兩三年中,在生活當中將會看到銀河通用帶來的通用機器人具身系統賦能的機器人。」











