近年來,人工智能技術迅猛進步,其在不同領域的套用及效能表現引發了人們的廣泛關註,特別是在數學領域,人工智能的套用尤為顯著。在這樣的背景下,MathEval評估平台的推出成為了一個備受矚目的焦點,它為大模型在數學解題能力方面的評估提供了一個權威且可靠的衡量標準。這一平台的出現,不僅為評估各類大模型的效能提供了有力的支持,也有助於推動人工智能技術在數學領域的深入套用。

在最近一次MathEval評估中,30種不同的大模型接受了嚴苛的測試。為了確保評測結果的精準無誤與公平公正,評估團隊引入了GPT-4這一前沿大模型技術,負責答案的精準提取與匹配工作。這一創新舉措有效規避了傳統的評測方法可能帶來的誤差,使得評估結果更具說服力。
評估結果揭曉,學而思精心研發的九章大模型、百度的文心一言4.0版本以及科大訊飛的星火V3.5版本脫穎而出,榮獲前三甲的佳績。其中,九章大模型的表現尤為亮眼,不僅在中英文處理能力上展現出了卓越的實力,而且在解答不同教育階段的數學問題上也遊刃有余,成為本次評測中耀眼的明星。
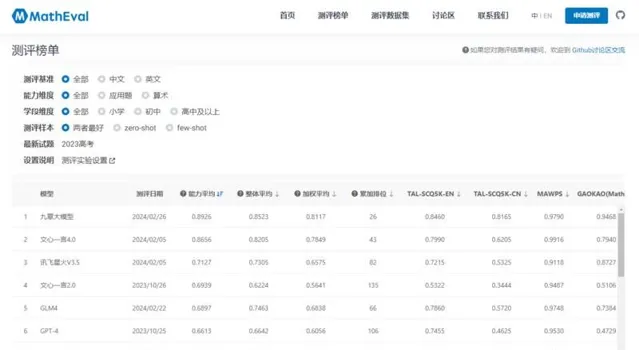
MathEval這一平台的出現,源於對數學領域大模型能力評估的迫切需求。隨著中國大模型釋出數量的激增,目前已超過200個,這些大模型在數學領域的套用日益廣泛,涉及數學題目解答、數據分析、學術探索及教育輔導等多個方面。然而,如何準確評估這些大模型在數學領域的具體能力,成為了一個亟待解決的問題。
目前,市面上的評估方法多側重於模型的通用能力,如推理和自然科學知識等方面,而對於數學能力專門的評估體系卻尚未完善。在這樣的背景下,由國家智慧教育新一代人工智能開放創新平台攜手暨南大學、北京師範大學、華東師範大學、西安交通大學及香港城市大學共同發起的MathEval應運而生,填補了行業空白。
MathEval平台的建立,為大模型在數學解題能力方面提供了一個專業的基準。它不僅關註模型在基礎算術方面的表現,更延伸至高級數學問題的處理,從而全面評估大模型在數學領域的綜合能力。

自2010年起,MathEval平台已經精心匯聚了19個備受推崇的數學測評數據集,這些寶貴的資源均源自ACL、AAAI、ICLR等眾多國際知名人工智能會議的公開數據。這些數據集涵蓋了廣泛的學段、題型、文本格式以及難度級別的數學問題,為大模型在數學解題能力方面的評估提供了豐富而全面的素材。
這一重要成果的取得,標誌著中國在大模型技術套用於數學領域的研究與開發方面邁出了堅實的步伐,彰顯了國產大模型在數學問題解決能力上的卓越潛力。展望未來,隨著技術的不斷進步和最佳化,相信國產大模型將在更多領域展現其強大的套用價值,成為推動人工智能事業發展的重要力量。











