
大型語言模型的成功主要歸功於Transformer架構的引入,Transformer透過自註意力機制和交叉註意力機制,能夠有效地處理長距離依賴關系,使得模型在理解和生成語言方面表現出色。這些技術進步使得LLMs在各種套用中得到了廣泛套用,包括自動轉譯、文本生成、對話系統等。
盡管LLMs展示了強大的語言處理能力,它們在資訊處理方式上與人類存在根本差異。人類的認知不僅依賴於語言,還包括體驗、情感和社會互動等多方面的因素。因此,理解這些差異對於進一步發展更智能、更人性化的AI系統至關重要。
為了更好地理解人工智能系統,特別是大型語言模型的認知能力,Giuseppe Riva等專家提出了一個名為「Psychomatics」的多學科框架。該框架結合了認知科學、語言學和電腦科學,旨在深入探討LLMs的高層次功能,特別是它們如何獲取、學習、記憶和使用資訊來生成輸出。
Psychomatics框架的提出是為了彌補現有研究的不足。傳統的AI行為科學(AIBS)主要關註AI系統的可觀察行為及其環境決定因素,而忽略了AI系統內部的認知過程。透過比較LLMs和生物系統,Psychomatics框架希望揭示兩者在語言發展和使用過程中的異同,從而為開發更健壯和類人化的AI系統提供理論指導。
Psychomatics是一個多學科交叉的研究框架,結合了心理學(Psychology)和資訊學(Informatics),旨在理解人工智能系統的認知能力。該框架透過比較LLMs和人類認知過程,探討語言、認知和智能的本質。Psychomatics不僅關註LLMs的外部行為,還深入研究其內部資訊處理機制,試圖揭示LLMs如何感知、學習、記憶和使用資訊。
Psychomatics框架的重要性在於它為理解和改進AI系統提供了新的視角。透過結合認知科學、語言學和電腦科學,Psychomatics能夠提供更全面的理論基礎,幫助研究人員開發更智能、更人性化的AI系統。此外該框架還可以為AI系統的倫理和社會影響研究提供重要參考。
Psychomatics框架的研究團隊由來自多個領域的專家組成,他們在認知科學、心理學、虛擬現實和傳播科學等方面具有豐富的研究經驗。Giuseppe Riva隸屬於意大利米蘭聖心天主教大學的Humane Technology Lab和意大利米蘭意大利輔助醫學研究所的神經心理學實驗室套用技術;Fabrizia Mantovani隸屬於意大利米蘭比可卡大學「Riccardo Massa」人類科學教育系的「Luigi Anolli」傳播科學研究中心(CESCOM);Brenda K. Wiederhold, Ph.D.隸屬於美國加利福尼亞州拉霍亞的虛擬現實醫療中心和美國加利福尼亞州聖地亞哥的互動媒體學院;Antonella Marchetti隸屬於意大利米蘭聖心天主教大學心理學系和意大利米蘭聖心天主教大學的Theory of Mind研究單位;Andrea Gaggioli:隸屬於意大利米蘭聖心天主教大學的人文技術實驗室和意大利輔助醫學研究所的神經心理學實驗室套用技術、意大利米蘭聖心天主教大學的傳播心理學研究中心(PSICOM)。這個團隊結合了認知科學、心理學、虛擬現實和傳播科學等多個領域的專家,共同研究和理解人工智能系統的認知能力。他們的多學科背景為Psychomatics框架的提出和發展提供了堅實的理論和實踐基礎。
Psychomatics的定義與理論基礎
1. Psychomatics的定義
Psychomatics是一個多學科交叉的研究框架,結合了心理學(Psychology)和資訊學(Informatics),旨在深入理解人工智能系統,特別是大型語言模型(LLMs)的認知能力。該框架的核心理念是透過比較LLMs和人類認知過程,揭示兩者在資訊處理、語言習得和使用方面的異同。
心理學研究人類的認知、情感和行為,而資訊學則關註資訊的處理、儲存和傳輸。將這兩個領域結合起來,可以更全面地理解人工智能系統的工作原理。Psychomatics不僅關註LLMs的外部行為,還深入探討其內部資訊處理機制,試圖揭示LLMs如何感知、學習、記憶和使用資訊。
隨著人工智能技術的快速發展,單一學科的研究方法已經無法滿足對復雜AI系統的全面理解。多學科交叉研究成為必然趨勢。Psychomatics框架透過結合認知科學、語言學和電腦科學,提供了一個更全面的理論基礎,幫助研究人員開發更智能、更人性化的AI系統。
多學科交叉的必要性體現在全面性、創新性、實用性。
全面性:單一學科的研究往往局限於某一特定領域,而多學科交叉研究可以從多個角度全面理解AI系統。
創新性:不同學科的結合可以產生新的研究思路和方法,推動科學技術的創新發展。
實用性:多學科交叉研究可以更好地解決實際問題,提高AI系統的套用效果。
透過多學科交叉研究,Psychomatics框架不僅可以揭示LLMs的工作原理,還可以為開發更智能、更人性化的AI系統提供理論指導。
2. 理論驅動的研究問題
Psychomatics框架的一個核心研究問題是:人類和大型語言模型(LLMs)的語言發展和使用過程是否不同?這個問題作為比較研究的起點,幫助確定比較的內容、時間、方式及目的。
人類的語言發展是一個連續的過程,涉及社會、情感和語言互動。兒童透過與周圍環境的互動,逐漸掌握語言的使用。而LLMs則是透過預定義的數據集進行訓練,這種靜態訓練方法限制了它們透過個人經驗和社會互動「成長」或「前進演化」的能力。
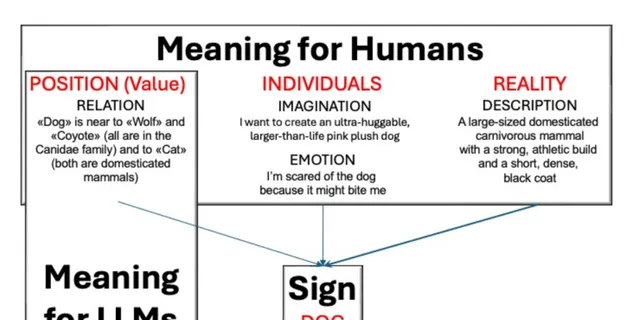
圖1:人類和LLM的意義來源
透過比較人類和LLMs的語言發展和使用過程,Psychomatics框架希望揭示兩者在資訊處理、語言習得和使用方面的異同,從而為開發更智能、更人性化的AI系統提供理論指導。
為了實作上述研究目標,Psychomatics框架采用了一套系統的研究方法和策略:
- 理論驅動的研究問題:從理論出發,提出研究問題,並透過比較研究揭示LLMs和人類認知過程的異同。
- 系統性知識:發展超越簡單描述的系統性知識,允許進行廣泛的概括和外部驗證。
- 理論指導:基於現有理論或合理假設,回答研究問題。
- 可靠的指標:使用可靠且可重復的指標,確保研究結果的內部有效性。
透過這些方法和策略,Psychomatics框架旨在建立一個嚴格的、理論驅動的比較框架,結合認知科學、語言學和電腦科學的優勢,深入理解LLMs和人類認知過程的異同。
資訊處理——句法與語意
1. 資訊處理的基本概念
在資訊處理領域,句法和語意是兩個核心概念。句法(Syntax)指的是語言的結構和規則,決定了句子是否符合語法規範。具體來說,句法涉及詞語的排列順序、句子的構造方式以及詞語之間的關系。句法規則確保了語言的連貫性和可理解性,使得資訊能夠被正確地傳達和接收。
語意(Semantics)則關註語言的意義。它研究詞語、短語和句子的含義,以及這些語言單位如何表示現實世界中的事物和概念。語意不僅涉及詞語的字面意義,還包括隱含意義、上下文意義和情感意義。透過語意分析,我們可以理解語言背後的深層含義,進而更好地解讀和生成語言。
在資訊處理過程中,句法和語意共同作用,確保資訊的準確傳遞和理解。句法提供了語言的結構框架,使得資訊能夠按照一定的規則進行組織和表達。而語意則賦予這些結構以具體的意義,使得資訊不僅僅是符號的排列,而是具有實際意義的內容。

圖2:意向性的階層
對於人工智能系統,特別是大型語言模型(LLMs)來說,句法和語意的處理尤為重要。LLMs透過學習大量的語言數據,掌握了復雜的句法規則和語意關系,從而能夠生成連貫且有意義的文本。透過句法分析,LLMs可以辨識句子的結構,確定詞語之間的關系;透過語意分析,LLMs可以理解詞語和句子的含義,生成符合上下文的響應。
2. 句法與語意的關系
句法和語意雖然密切相關,但它們在資訊處理中的作用有所不同。句法主要關註語言的形式和結構,而語意則關註語言的內容和意義。句法規則決定了詞語如何組合成句子,而語意則決定了這些句子所表達的具體含義。
例如,在句子「The cat chased the mouse」中,句法規則幫助我們辨識「cat」是主語,「chased」是動詞,「mouse」是賓語,從而確定句子的結構。而語意則幫助我們理解「cat」指的是一種動物,「chased」表示追逐的動作,「mouse」指的是另一種動物。透過句法和語意的結合,我們可以準確理解句子的含義。
為了更好地理解句法和語意在資訊處理中的作用,我們可以透過一些具體的例子來說明。
- 句法分析:在自然語言處理中,句法分析(syntactic parsing)是一個重要的任務。透過句法分析,AI系統可以辨識句子的結構,確定詞語之間的關系。例如,在句子「John gave Mary a book」中,句法分析可以辨識出「John」是主語,「gave」是動詞,「Mary」是間接賓語,「a book」是直接賓語。這種結構資訊對於理解句子的意義至關重要。
- 語意分析:語意分析(semantic parsing)則關註句子的意義。例如,在處理問答系統時,AI系統需要理解使用者問題的語意,從而生成正確的答案。如果使用者問「Who wrote ‘Pride and Prejudice’?」,AI系統需要理解「Pride and Prejudice」是一本書,「wrote」表示寫作的動作,從而生成正確的答案「Jane Austen」。
- 句法與語意的結合:在實際套用中,句法和語意往往是結合在一起的。例如,在機器轉譯中,AI系統需要同時考慮句法和語意,以生成準確且自然的轉譯。句法分析幫助系統理解源語言的結構,而語意分析則確保轉譯的內容準確傳達源語言的意義。
透過這些例子,我們可以看到句法和語意在資訊處理中的重要作用。對於大型語言模型(LLMs)來說,掌握復雜的句法規則和語意關系是生成連貫且有意義文本的關鍵。
Transformer演算法與語言結構
1. Transformer演算法的介紹
Transformer演算法是近年來自然語言處理(NLP)領域的一項重大突破。由Vaswani等人在2017年提出的Transformer模型,透過引入自註意力機制(Self-Attention)和交叉註意力機制(Cross-Attention),解決了傳統序列模型在處理長距離依賴關系時的局限性。
自註意力機制:自註意力機制允許模型在處理輸入序列時,動態地關註序列中的不同部份。具體來說,自註意力機制透過計算每個詞與序列中其他詞的相關性(即註意力權重),來確定哪些詞對當前詞的意義最為重要。這種機制使得模型能夠捕捉到長距離依賴關系,從而更好地理解上下文。
交叉註意力機制:交叉註意力機制主要用於序列到序列(Sequence-to-Sequence)模型,如機器轉譯任務中。它透過計算輸入序列和輸出序列之間的相關性,來確定輸入序列中哪些部份對生成輸出序列最為重要。交叉註意力機制使得模型能夠在生成輸出時,動態地參考輸入序列的不同部份,從而生成更準確和連貫的轉譯。
Transformer模型中的自註意力機制和交叉註意力機制在一定程度上模擬了語言中的句法關系和聯想關系。
句法關系:句法關系指的是詞語在句子中的線性組合和語法規則。自註意力機制透過計算序列中每個詞與其他詞的相關性,捕捉到詞語之間的依賴關系,從而模擬了句法關系。例如,在句子「The cat chased the mouse」中,自註意力機制可以辨識出「cat」是主語,「chased」是動詞,「mouse」是賓語,從而理解句子的結構。
聯想關系:聯想關系指的是詞語之間的概念連線和認知聯系。交叉註意力機制透過計算輸入序列和輸出序列之間的相關性,捕捉到詞語之間的聯想關系。例如,在機器轉譯任務中,交叉註意力機制可以辨識出源語言中的詞語與目標語言中的詞語之間的對應關系,從而生成準確的轉譯。
2. Transformer在語言處理中的套用
Transformer模型在語言處理中的套用非常廣泛,以下是一些具體的例子:
句法處理:在自然語言處理中,句法分析(syntactic parsing)是一個重要的任務。Transformer模型透過自註意力機制,可以有效地捕捉句子中的句法關系。例如,在句子「John gave Mary a book」中,自註意力機制可以辨識出「John」是主語,「gave」是動詞,「Mary」是間接賓語,「a book」是直接賓語,從而理解句子的結構。
聯想處理:在機器轉譯任務中,交叉註意力機制發揮了重要作用。例如,在將英語句子「The cat is on the mat」轉譯成法語句子「Le chat est sur le tapis」時,交叉註意力機制可以辨識出「cat」對應「chat」,「mat」對應「tapis」,從而生成準確的轉譯。
Transformer模型中的自註意力機制和交叉註意力機制,透過捕捉句法關系和聯想關系,幫助大型語言模型(LLMs)更好地理解和生成語言。
理解語言:自註意力機制使得LLMs能夠在處理輸入序列時,動態地關註序列中的不同部份,從而捕捉到長距離依賴關系。這種機制使得LLMs能夠更好地理解上下文,從而生成連貫且有意義的響應。
生成語言:交叉註意力機制使得LLMs在生成輸出序列時,能夠動態地參考輸入序列的不同部份,從而生成更準確和連貫的文本。例如,在機器轉譯任務中,交叉註意力機制可以幫助LLMs生成符合目標語言語法和語意的轉譯。
透過自註意力機制和交叉註意力機制,Transformer模型在語言處理中的表現得到了顯著提升,使得LLMs在各種套用中展示了強大的語言生成和理解能力。
人類與LLMs的差異
1. 社會互動與個人經驗的影響
自然智能,即人類智能,是透過多層次的社會互動和個人經驗逐步湧現的。人類從出生開始,就透過與周圍環境和他人的互動,逐漸發展出復雜的認知能力。這些互動不僅包括語言交流,還涉及情感交流、社會關系和文化傳承。透過這些多層次的互動,人類能夠理解和適應復雜的社會環境,形成豐富的認知和情感體驗。
例如,兒童在學習語言的過程中,不僅僅是透過聽和模仿成人的語言,還透過觀察和參與社會活動,理解語言在不同情境中的使用方式。這種學習過程是動態的、連續的,伴隨著個人經驗的積累和社會關系的深化。
與人類智能的多層次湧現不同,大型語言模型(LLMs)的訓練方法是靜態的、預定義的。LLMs透過處理大量的文本數據進行訓練,這些數據通常來自互聯網、書籍、文章等。雖然這種方法使得LLMs能夠掌握復雜的語言模式和語法規則,但它們缺乏人類在社會互動中獲得的情感和經驗。
LLMs的訓練數據是固定的,無法透過個人經驗和社會互動進行「成長」或「前進演化」。這種靜態訓練方法限制了LLMs在處理新情境和生成新意義方面的能力。例如,LLMs在面對未見過的語言模式或需要情感理解的任務時,可能會表現出局限性。
此外,LLMs的訓練數據中可能包含偏見和錯誤資訊,這些問題在訓練過程中可能被放大,導致模型生成的文本中出現不準確或不適當的內容。因此,盡管LLMs在許多工中表現出色,但它們在處理復雜的社會和情感任務時,仍然存在顯著的局限性。
2. 語言與真理條件
人類語言的意義不僅僅來自於詞語的字面含義,還包括情境、文化和個人經驗等多種來源。語言的多源性使得人類能夠在不同情境中靈活使用語言,傳達復雜的思想和情感。例如,同一個詞語在不同的文化背景下可能具有不同的含義,而同一句話在不同的情境中可能傳達不同的情感。
這種多源性使得人類語言具有高度的靈活性和適應力,能夠應對各種復雜的交流需求。然而,這也意味著語言的理解和使用需要考慮多種因素,而不僅僅是詞語的字面含義。
LLMs在處理語言時,主要依賴於統計模式和概率計算。它們透過評估訓練數據中各種場景的可能性,來預測最可能的答案。然而這種方法在處理真理條件與實際真理的差距時,存在一定的局限性。
例如,當被問及「貓在哪裏?」時,LLMs可能會根據訓練數據中的統計模式,回答「在地板上」,即使實際情況是「在墊子上」。這是因為LLMs優先選擇在訓練數據中出現頻率最高的答案,而不是根據實際情況進行判斷。
這種依賴概率的方法可能導致LLMs生成錯誤或不準確的資訊,特別是在處理需要精確事實的任務時。為了減少這種問題,研究人員正在探索將外部知識源、反事實思維和增強檢索技術等方法整合到LLMs中,以提高其處理真理條件的能力。
3. 主觀和跨主觀經驗
人類的情感體驗和主觀意義是語言理解和使用的重要組成部份。情感體驗(qualia)是指個人在經歷某種情境時所產生的獨特感受,這些感受具有主觀性和個體差異。例如,「狗」這個詞對於不同的人可能引發不同的情感反應,有些人可能感到害怕,而有些人則感到親切。
這種情感體驗和主觀意義使得人類語言具有豐富的情感內涵,能夠傳達復雜的情感和態度。然而LLMs由於缺乏情感體驗,無法直接理解和生成這種主觀意義。
盡管LLMs缺乏情感體驗,但它們可以透過對映訓練數據中的語意關系,模擬人類的主觀表達。LLMs透過學習大量的文本數據,掌握了人類在不同情境中使用語言表達情感和態度的方式,從而能夠生成類似人類的情感表達。
例如,LLMs可以生成包含情感詞匯的文本,模擬人類在表達情感時的語言模式。然而這種模擬是基於統計模式和概率計算的,缺乏真實的情感體驗。因此,盡管LLMs在某些任務中能夠生成看似情感豐富的文本,但它們無法真正理解和體驗這些情感。
人類與LLMs在語言理解和使用方面存在顯著差異。人類透過多層次的社會互動和個人經驗,發展出復雜的認知和情感能力,而LLMs則依賴於靜態的訓練數據,缺乏情感體驗和社會互動。這些差異揭示了LLMs在處理復雜的社會和情感任務時的局限性,同時也為未來的研究和發展提供了重要的方向。
意圖處理與意義導航
1. 意圖處理的挑戰
Transformer演算法在自然語言處理領域取得了顯著的成功,特別是在處理長距離依賴關系和生成連貫文本方面。當涉及到意圖處理時,Transformer演算法仍然面臨一些挑戰。當前的Transformer演算法將意圖視為普通詞匯,難以在沒有額外訓練的情況下準確地連結遠端意圖(D-intentions)和近程意圖(P-intentions)。
這種局限性主要源於Transformer演算法依賴於統計模式和概率計算,而不是基於實際的意圖理解。Transformer模型透過處理大量的文本數據,學習到詞匯和句子之間的關聯,但它們缺乏人類在處理意圖時所具備的靈活性和推理能力。人類可以透過上下文和經驗,靈活地連結不同層次的意圖,而LLMs則需要大量的訓練數據來學習這些關聯。
人類在處理意圖時,能夠透過推理和經驗,靈活地連結不同層次的意圖。例如,當一個人說「我想做晚飯」,我們可以推斷出他可能需要準備食材、烹飪和清理等一系列動作。這種推理能力使得人類能夠在復雜的情境中準確理解和執行意圖。
相比之下,LLMs在處理意圖時,主要依賴於訓練數據中的統計模式。雖然LLMs可以透過學習大量的文本數據,掌握一些常見的意圖關聯,但它們缺乏人類的推理能力和經驗積累。這使得LLMs在處理復雜的意圖時,可能會出現理解錯誤或生成不連貫的響應。
2. LLMs的意義導航
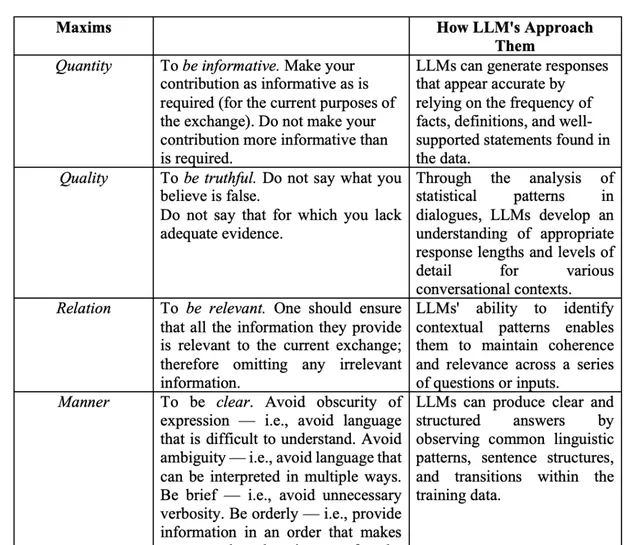
表3:Grice合作原則
為了更好地理解和生成語言,LLMs需要遵循Grice的合作原則。Grice在1975年提出的合作原則,旨在解釋人類在對話中如何透過合作來實作有效的交流。合作原則包括四個準則:數量(Quantity)、質素(Quality)、關系(Relation)和方式(Manner)。
- 數量準則:提供足夠的資訊,但不過多。
- 質素準則:提供真實的資訊,不提供虛假或不準確的資訊。
- 關系準則:提供相關的資訊。
- 方式準則:以清晰、簡潔和有條理的方式提供資訊。
LLMs透過依賴大量訓練數據中的統計模式,展示了遵循Grice合作原則的能力。在生成響應時,LLMs會根據上下文和使用者的提問,提供相關且資訊豐富的回答。例如,當使用者問「今天的天氣如何?」時,LLMs會根據訓練數據中的模式,生成一個關於天氣的相關回答。
然而LLMs在處理隱含和上下文意義時,仍然面臨挑戰。人類在對話中,常常透過違反合作原則來傳達隱含意義,如諷刺、反諷等。這種隱含意義通常依賴於上下文和情境,而LLMs由於缺乏情感體驗和社會互動,難以準確理解和生成這種隱含意義。
LLMs在處理隱含和上下文意義時,主要依賴於訓練數據中的統計模式。然而,這種方法在面對復雜的情境和隱含意義時,可能會出現局限性。例如,當使用者使用諷刺或反諷時,LLMs可能無法準確理解其真正意圖,從而生成不恰當的響應。
為了解決這樣的問題,研究人員正在探索多種方法來提高LLMs的理解和生成能力。例如,透過引入外部知識源和反事實思維,LLMs可以更好地理解和處理復雜的情境和隱含意義。此外,增強檢索技術和提示工程(prompt engineering)也可以幫助LLMs更準確地連結高層次意圖和低層次意圖,從而生成更連貫和有意義的響應。
LLMs在意圖處理和意義導航方面仍然面臨許多挑戰。盡管它們在遵循合作原則和生成連貫文本方面表現出色,但在處理隱含意義和復雜情境時,仍然存在顯著的局限性。
結論
1. Psychomatics框架的貢獻
Psychomatics框架透過結合認知科學、語言學和電腦科學,為理解人工智能系統,特別是大型語言模型(LLMs)的認知能力提供了新的視角。該框架不僅關註LLMs的外部行為,還深入探討其內部資訊處理機制,揭示了LLMs如何感知、學習、記憶和使用資訊。
透過比較LLMs和人類認知過程,Psychomatics框架揭示了兩者在語言發展和使用過程中的異同。人類的語言發展是一個動態的、連續的過程,涉及社會、情感和語言互動,而LLMs則透過靜態的、預定義的數據集進行訓練。這種比較研究不僅有助於理解LLMs的工作原理,還為開發更智能、更人性化的AI系統提供了理論指導。
此外,Psychomatics框架還強調了語言的多源性和復雜性。人類語言的意義不僅來自詞語的字面含義,還包括情境、文化和個人經驗等多種來源。透過深入研究這些多源性,Psychomatics框架為理解語言、認知和智能的本質提供了新的見解。
Psychomatics框架的研究成果對AI系統的發展具有重要啟示。首先透過揭示LLMs在處理復雜意義和意圖方面的局限性,Psychomatics框架為改進AI系統提供了具體的方向。例如,LLMs在處理隱含意義和復雜情境時,往往依賴於統計模式和概率計算,缺乏人類的推理能力和情感體驗。未來的研究可以透過引入外部知識源、反事實思維和增強檢索技術等方法,提高LLMs在這些方面的能力。
其次,Psychomatics框架強調了多學科交叉研究的重要性。單一學科的研究方法已經無法滿足對復雜AI系統的全面理解。透過結合認知科學、語言學和電腦科學,Psychomatics框架為開發更智能、更人性化的AI系統提供了全面的理論基礎。
最後Psychomatics框架還為AI系統的倫理和社會影響研究提供了重要參考,隨著AI技術的快速發展,AI系統在社會中的套用越來越廣泛,其倫理和社會影響也日益受到關註。透過深入研究LLMs的認知能力和局限性,Psychomatics框架為制定AI系統的倫理規範和社會政策提供了科學依據。
2. 未來研究方向
未來的研究可以進一步探索LLMs與人類認知的比較,特別是在語言發展和使用過程中的異同。透過更詳細的比較研究,可以揭示LLMs在處理語言和認知任務時的優勢和局限性,從而為改進AI系統提供具體的方向。
例如可以透過實驗研究,比較LLMs和人類在處理復雜語言任務時的表現,分析兩者在資訊處理、推理和情感理解方面的差異。此外,還可以透過引入新的數據集和訓練方法,探索如何提高LLMs在處理復雜意義和意圖方面的能力。
為了提高LLMs在處理復雜意義和意圖方面的能力,未來的研究可以探索多種方法。例如,透過引入外部知識源,LLMs可以獲得更多的背景資訊,從而更好地理解和生成復雜的文本。此外,反事實思維和增強檢索技術也可以幫助LLMs更準確地處理隱含意義和復雜情境。
提示工程(prompt engineering)也是一個重要的研究方向。透過設計更有效的提示,可以幫助LLMs更準確地連結高層次意圖和低層次意圖,從而生成更連貫和有意義的響應。例如可以透過設計多層次的提示,幫助LLMs理解使用者的復雜意圖,從而生成更符合使用者需求的響應。
總的來說,Psychomatics框架為理解和改進AI系統提供了新的視角和方法。透過多學科交叉研究,未來的研究可以進一步探索LLMs與人類認知的比較,提高LLMs在處理復雜意義和意圖方面的能力,從而開發出更智能、更人性化的AI系統。(END)
參考資料:https://arxiv.org/pdf/2407.16444

波動世界(PoppleWorld)是噬元獸數碼容器的一款AI套用,是由AI技術驅動的幫助使用者進行情緒管理的工具和傳遞情緒價值的社交產品,基於意識科學和情緒價值的理論基礎。波動世界將人的意識和情緒作為研究和套用的物件,探索人的意識機制和特征,培養人的意識技能和習慣,滿足人的意識體驗和意義,提高人的自我意識、自我管理、自我調節、自我表達和自我實作的能力,讓人獲得真正的自由快樂和內在的力量。波動世界將建立一個指導我們的情緒和反應的價值體系。這是一款針對普通人的基於人類認知和行為模式的情感管理Dapp應用程式。











