
作者:haina
編輯:penny

企業要用好 LLM 離不開高質素數據。和傳統機器學習模型相比,LLM 對於數據需求量更大、要求更高,尤其是非結構化數據。而傳統 ETL 工具並不擅長非結構化數據的處理,因此,企業在部署 LLM 的過程中,數據科學家們往往要耗費大量的時間精力在數據處理環節。這一環節既關系到 LLM 部署的效率和質素,也對數據科學家人力的 ROI 產生影響。
Unstructured.io 的 CEO Brian Raymon 捕捉到了這一機會,專註為企業解決非結構化數據處理問題。Unstructured 做的事情是在 data ingestion 環節將非結構化數據提取出來,分割成更小的邏輯單元,並生成的元素級後設資料,再將提取好的、轉化成 JSON 格式的數據返回給使用者。 Data Ingestion 的精細化程度直接決定後續數據處理流程的效果,而目前 Unstructured.io 是這個環節做的最好的公司之一。
Unstructured 的優勢還在於深刻理解大公司和政府的需求,CEO 的政府背景使之擁有充足的資源支持。Unstructured.io 目前已經拿下了不少大企業訂單,也與美國空軍和太空部隊等政府部門達成了合作。
非結構化數據處理領域還在起步階段,Unstructured.io 面臨著雲廠商、上下遊公司和其他初創公司的競爭。未來,Multi-step agents 和多模態技術在該領域的套用,可能會帶來更多機會。我們在矽谷了解到,未來幾個月模型 reasoning 能力會進一步提升,multi-step agent 可能逐步實作,我們也期待非結構化數據領域能解鎖更多的商業價值。
💡 目錄 💡
01 Unstructured.io 的市場機會
02 什麽是 Unstructured.io
03 市場競爭
04 結論與猜想
01.
Unstructured.io 的
市場機會
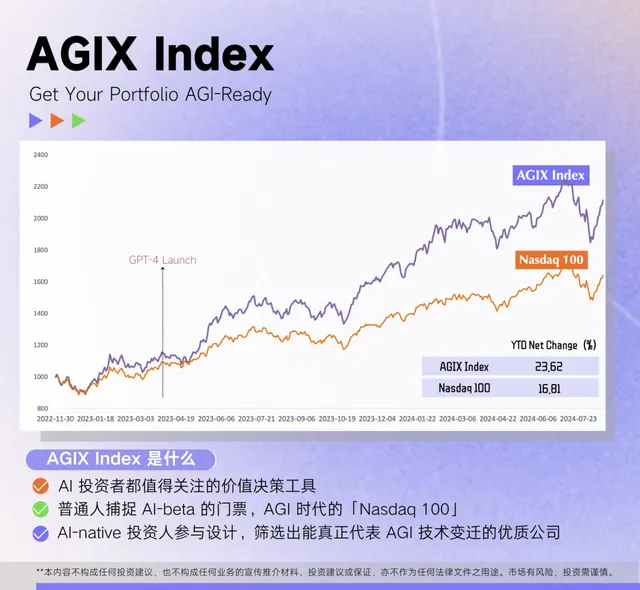
企業正在大規模采用 LLM ,在麥肯錫的調研中,2023 年是 AI 在企業端滲透率最快的一年。 AI 在企業側的滲透率從 55% 增長到 72%,增長了 17 個百分點,如果把 AI 縮小到 GenAI 的範圍,則速度更加驚人,過去一年從 33% 增長到 65%,增長了一倍。根據 Morgan Stanley 2Q24 的 CIO Survey,2025 年預計會繼續迎來企業的大規模 GenAI adoption。
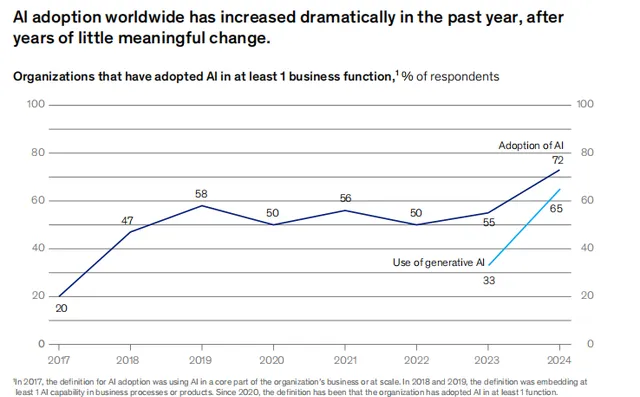
Source: The state of AI in early 2024: GenAI adoption spikes and starts to generate value, May 30, 2024 | Survey, McKinsey & Company
把 LLM 用好的前提條件是為 LLM 提供高質素的數據。企業的封包括結構化數據和非結構化數據,其中非結構化數據占了 80%,但在 LLM 出現之前,企業 ETL 處理的主要是結構化數據。 因為傳統 ETL 工具不能在非結構化數據中提取足夠的特征,同時傳統機器學習模型受智能程度限制,對數據精確度的要求比 LLM 更高,這使得企業一直不能很好的把非結構化數據利用起來。
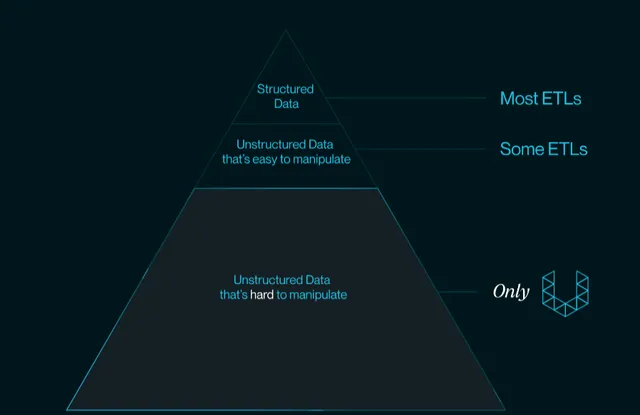
而 LLM 與傳統的機器學習模型相比有兩點不同:
LLM 需要更多數據。企業要用好 LLM,必須要讓 LLM 擁有企業內部、專業領域的特定知識 。實作這一點有兩個主流方式: Fine-tuning model 或做 RAG (Retrieval Augmented Generation)。 Fine-tuning 將特定領域的知識 encode 到 model memory 中,RAG 則是即時的從大量數據中檢索資訊,幫助 model 獲取最新的資訊。這些知識、資訊中包含了大量的非結構化數據。
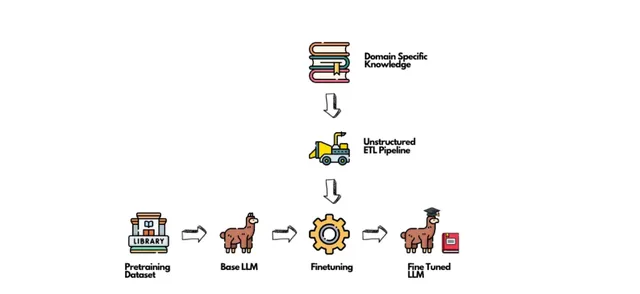
使用 Unstructured 對大模型進行 finetune
二是 LLM 的 next token prediction 的機制使得它對數據的精確程度要求沒這麽高了,
這讓非結構化數據即使沒有被處理的很好,也有機會被用起來了。
所以,LLM、尤其是 RAG 方法的套用大大增加了企業數據處理的工作量。 Unstructured.io 的調研顯示,數據科學家需要花超過 3/4 的工作時間準備數據,人力成本極高。這是因為即便 LLM 對數據的精確度要求降低了,想要做好 RAG 並不容易。 「the devil is in the details.」 Unstructured.io 的優勢就是透過大量細致的工程化工作,處理好了 details。
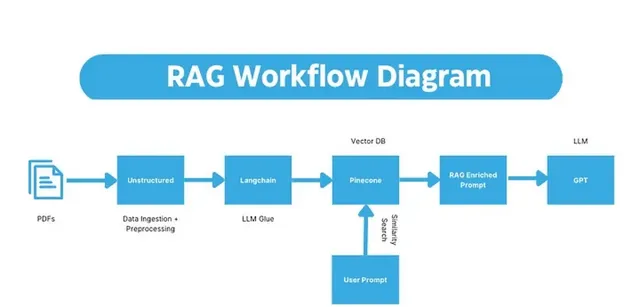
What is RAG
RAG 的工作流大致分為:數據提取及處理 (data ingestion and preprocessing) → 索引建立 (index creation) → 檢索 (retrieval) → 回答生成 (answer generation)。
在 data ingestion 環節,需要將數據提取後分割成更小的邏輯單元(稱為元素)、生成的元素級後設資料,並轉化成 JSON 等結構化格式。這一步的精細程度如何,直接決定了後續數據清理、數據分塊、生成分塊摘要以及 embedding 的效果,這是難點,也是 Unstructured 的優勢所在。
用傳統的方式清理數據,需要編寫大量的正規表式,自訂 Python 指令碼去辨識不需要的內容(如頁首、頁尾、重復樣版或無關章節),但是 Unstructured 做到了每個文件元素都有明確的分類標簽或後設資料標記,數據科學家可以直接使用這些後設資料快速辨識出需要的內容。
Unstructured 能夠依據邏輯和上下文界限的智能分塊(Chunking),也是因為在數據分割階段做的足夠精細化。 在做數據 embedding 時,developer 會先將原始檔分割成若幹塊,因為這樣可以讓 embedding 做的顆粒度更細,檢索更準確;同時 LLM 的上下文視窗有限,每次都處理整個文件的成本過高,也會影響輸出效果。傳統的 chunking 方式是根據字元長度將文件分成大小相等的部份,但是這種方法不能反映文本的邏輯。 而 Unstructured 因為對數據分割的足夠精細,分類了文件元素,所以可以透過內容邏輯來分塊。 它還會生成分塊摘要,也能做到辨識並單獨提取文件文本、影像和表格等元素。 這最終實作了更好的RAG效果,生成更好的答案。

Unstructured Chunking 方式
和傳統 Character Splitting 的不同
💡
Embedding: 使用 embedding models 將文本表示為向量字串(一個浮點數列表),其中編碼了底層數據的語意資訊。embeding 允許根據語意相似性而不僅僅是關鍵字匹配來搜尋文本,是許多 LLM 應用程式的核心。這一流程中,開發者自己選擇好合適的切分技術(chunking techniques)和嵌入模型(embedding models)後,Unstructured 平台會自動處理模型的呼叫、部署和執行,生成的嵌入向量會被整理、輸出,儲存在數據庫,用於後續的分析任務。
02.
什麽是 Unstructured.io
Unstructured.io 是前美國中央情報局分析師 Brian Raymond 2022 年 7 月成立的。創立 Unstructured 之前,Brian Raymond 和創始團隊均在 NLP 領域的公司工作,他們發現了同樣的問題:由於無法處理非結構化格式的數據,客戶無法很好的套用 AI 模型。
所以,Unstructured.io 成立後首先釋出了開源的非結構化數據提取工具,將企業的非結構化數據解放出來。同時,Raymond 的政府背景很深厚,Unstructured.io 得到了美國空軍、美國特種作戰司令部的支持,與大企業和美國政府合作打磨商業化版本的產品。
上文已經提到過, Unstructured.io 目前專註的是 Data injestion 這一個環節,幫助企業從各種資料來源(以 PDF 為主,還包括 PowerPoints、Google 文件、Slack 訊息、音訊記錄等)提取出所需的內容,進行細致的分類後,將提取好的、轉化成 JSON 格式的數據返回給使用者。 使用者可以結合其他的工具和庫對這些數據進行進一步處理,套用於 LLM。
💡
企業中的非結構化數據處理以 PDF 為主,是因為數據大多數場景下會被轉化為 PDF 格式儲存,包括文章、紀要、財務報表等等。而從 PDF 中提取數據一直是數據科學家非常頭痛的工作,因為經常會遇到表格被鎖住、格式混亂、內容無法存取一系列問題。
不過為了獲取更廣闊的市場,Unstructured.io 也搭建了端到端的企業級平台,支持整個 Workflow。
產品矩陣
Unstructured.io 透過開源起步,不斷豐富產品形態,目前產品包括 SaaS、Serverless 和 Marketplace API,以及企業級平台,滿足了不同客戶的需求。
開源的 Python 庫:
開源的 Python 庫是 Unstructured 最早釋出的產品,官網上顯示已經被下載了六百多萬次,被 4.5 萬個組織使用,這其中包括三分之一的財富 500 強公司。
核心元件 包括 數據提取器、文件分割器和數據轉換器。
數據提取器負責從各種格式的文件中提取內容,如 PDF、Word 等。
文件分割器能夠將文件內容細化為更小的邏輯單元,便於進一步分析。
數據轉換器將提取和分割後的數據轉換成標準化的格式(以 JSON 為主),以便下遊套用和模型使用。
開源 Python 庫適合用於產品的原型開發,目前僅進行基礎的維護工作, 自2024 年開始就不再更新商業版推出的新功能了。 更高級的 chunking 方式、更多格式的檔和影像處理等等功能商業版使用者才能使用。 企業要是想要獲得更好的效能,還是要購買商業版本。
商業版 API:
商業版 API 分為 SaaS API, Serverless API, Marketplace API,核心元件與開源產品類似,但是支持更多的 chunking 方式、檔種類,提供更好的效能。
SaaS API 今年 1 月份推出,由 Unstructured 托管,使用者只需呼叫 API,無需管理底層基礎設施。目前已有超過 1000 個付費使用者了, 適合需要單批次處理的中小企業或個人使用者。
Serverless API 今年 6 月份推出,也是由 Unstructured 托管,但與 SaaS 版不同,Serverless 使得使用者可以更靈活地處理高並行請求。 適合需要高彈性、按需擴充套件的場景,比如非週期性的大批次處理,或需要根據負載自動調整資源的套用。
Marketplace API 今年 2 月份推出,由客戶自行托管在 AWS 或 Azure 等雲平台上,完全在公司內部基礎設施內處理數據。 它適合數據敏感性高的大企業,整合了多種企業級別的數據連結器。
Enterprise Platform:
Enterprise Platform 是一個 企業級、低程式碼、交鑰匙的ETL全流程解決平台。 它提供視覺化的使用者介面,讓使用者可以在不編寫程式碼的情況下建立完整的ETL工作流。商業模式包括 "即用即付 "選項和訂閱計劃,也可以為企業客製解決方案。
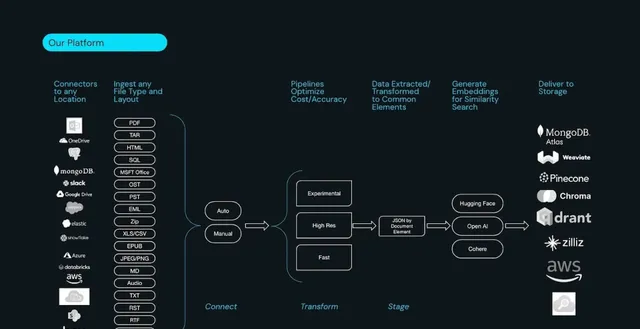
它適合擁有 大量數據的企業級公司和高增長公司。能力包括:
支持從 10 個資料來源提取文件內容(如 Azure Blob Storage、S3、Google Drive 等)。
標準化輸出傳送到10個目標資料來源(如 Pinecone、Weaviate、S3、Postgres 等)。
透過 workflow 連線源和目標,支持執行和排程工作流。
監控工作流狀態。
Unstructured 的產品還處於早期階段,未來有大量的功能值得開發。目前的產品規劃就已經涵蓋了很多功能:包括整合更多源和目標連結器、增加音訊和影像處理功能、支持使用者自訂 embedding 模型、整合 Azure AI Document Intelligence 和 AWS Textract、增加數據儲存和向量同步能力,推出新一代表格和表單提取模型等等。
產品優勢
根據分析產品和客戶訪談,我們發現 Unstructured.io 最突出的優勢有以下幾點:
1. 低延遲
企業反應 Unstructured 大大提升了處理非結構化數據的效率。這是因為處理多個不同類別的檔時, 傳統的方法是全部轉化成影像,然後再透過 OCR 統一流程處理這些影像, 速度很慢,推理成本也很高。而 Unstructured 對不同的檔類別(如 PDF、Word 文件、Excel 表格等)都提供了專門的數據提取方法,可以直接處理原始檔,避免了將檔轉換為影像的步驟,更為高效。 官網表示 Unstructured 的解決方案比將檔轉換為影像,再用 OCR 的方法快了約 100 倍。
2. 能處理的檔類別更多、更準確
很多企業評價 Unstructured 相比競品,可以從更多類別的檔格式中提取數據,而且提取文本時保持原有的語意。市場上還沒有能達到類似準確程度的替代工具。
這是因為 Unstructured 對檔內容的分類能力更強。 一些傳統的預處理工具(如 Azure Document Intelligence)只能對一些特定的檔類別,分類的元素層級也是有限的,比如只能辨識正文和標題。但是 Unstructured 分類更細致,生成 metadata,而且成本還更低。
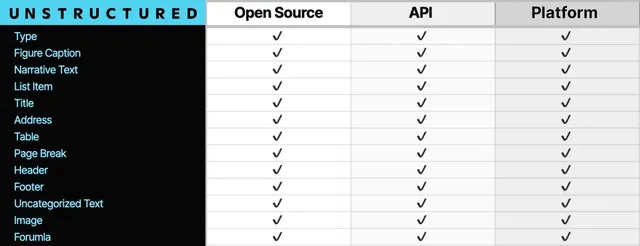
分類細致的好處在於方便做下一步的 cleaning、可以采用混合搜尋和基於metadata過濾的方式實作更加精確的內容控制(比如只處理正文,影像、文本分開處理),並可以按語意分塊, 這是 Unstructured 高準確性的關鍵要素。 不過 Unstructured 也沒有覆蓋所有場景,客戶認為還需要覆蓋更多的數據格式。
3. 廣泛的整合
Unstructured.io 的開放源碼庫包含 25 多個源連結器和 10 個目標連結器,盡量覆蓋了使用者的所有使用工具和場景。如與 LangChain, Llamaindex 等整合,進一步方便的 GenAI 套用的開發。Unstructured 還將這些打包到了商業版企業平台中,企業平台是一套交鑰匙的解決方案,有一個無程式碼使用者介面儀表板,可以直接建立和管理 RAG 工作流。
但綜合來看,Unstructured 的這些優勢更多的是因為起步更早、工程層面做的更細致,很難說是絕對的競爭壁壘。
客戶及商業化
雖然有開源版本,但 Unstructured.io 在付費客戶獲取上做的很好,在 2024 年 3 月完成 B 輪融資時,其 1 月份推出的商業版 SaaS API 就有超過 1000 個付費客戶了,其中包括不少大型企業以及政府訂單。
根據客戶訪談,我們發現很少有客戶會選擇 Enterprise platform 這個 ETL 全流程解決方案,更多的是從開源轉向商業版 API,僅僅將 Unstructured.io 用於 data injestion 環節,整合在企業已有的工作流中, 與其他工具(如 Milvus、Elasticsearch、LlamaIndex、LangChain 等)一起使用。比如 Qualcomm 采購了商業版 SaaS API,用於從財務檔和產品數據表(PDF、Word、Excel)中提取資訊。而 Adobe 將 Unstructured.io 用於內部模型訓練和微調的數據準備 pipeline 中,也用於 PDF 和 Photoshop 中的摘要和問答功能的實作。
Unstructured.io 的價值體現在節省數據處理的時間和成本,客戶訪談中,大部份客戶已經從開源產品轉化為付費使用者,付費從四位數/年~六位數/年不等,部份客戶有增加預算的計劃。 如 Adobe 預計會在 5000 美元/年的基礎上有 2-3倍的增長,IQVIA 也表示試點階段投入相對較低,如果全面投入使用成本可能在 500 萬到 1000 萬美元之間。
這是因為商業版本準確性更強,覆蓋的檔類別更多,也提供企業級的部署支持,Unstructured 從開源到商業化的過程是相對順暢的,我們預計未來的收入會持續提升。 Unstructured.io 在多個行業(如新聞、金融、法律、醫療等)都有套用案例,表明它的數據提取能力的通用性還是很強的。
不過客戶也普遍認為 Unstructured 面臨著來自大型雲廠商、上下遊公司以及其他創業公司的潛在競爭。 企業是否會遷移到其他產品很大程度上取決於使用深度, 目前來看,遷移成本是較低的。 針對特定行業領域的需求提供針對性的解決方案是 Unstructured 建立壁壘的潛在機會。
團隊及融資情況
團隊
Unstructured.io 的 Founder 及 CEO Brian Raymond 早期是一名政客,曾在美國中央情報局(CIA)擔任情報官員,後來在白宮負責伊拉克和 ISIS 的外交政策。在 ISIS 於伊拉克和敘利亞迅速崛起期間,Raymond 與奧巴馬總統和拜登副總統緊密合作。
後來,他加入初創公司 Primary AI,為公共部門和國家安全領域提供精確、安全的 NLP 解決方案。Brian 深入研究了如何基於 Transformer 構建知識圖譜和企業工作流。他意識到數據預處理在 AI/ML 專案中,其是在處理復雜的政府內部檔時非常重要。這使他決定創立 Unstructured.io,為企業和政府簡化數據準備過程。
Unstructured.io 的團隊由開源社區、大型企業和美國國防情報機構的技術專家組成。在商業化產品推出後,Brian 搭建起了銷售團隊。目前,Unstructured 有一支技術、市場和客戶服務領域實力都很強的團隊,有能力承接大型企業和政府機構的需求。

融資
Unstructured.io 獲得了累計 6500 萬美元的投資,投資方包括 AI 生態上層公司 LangChain 和 databricks,可以看出它在 Gen-AI 生態系中的重要性是被認可的。

03.
市場競爭
非結構化數據的提取是企業數據處理工作流中的一個環節,如果市場機會足夠大,工作流中的玩家都有動機、也有機會延伸到這個場景。根據客戶訪談分析,我們認為 Unstructured.io 主要面對來自大型雲廠商、上下遊公司及其他初創公司的潛在競爭。
大型雲廠商
根據客戶訪談,我們得知 Amazon、Azure 等雲廠商也在嘗試開發提供非結構化數據處理能力的工具,但由於這個領域技術比較新,巨頭行動慢,所以至今還沒有釋出可匹敵 Unstructrued 的產品。
雲廠商的優勢很明顯。產品組合上, 雲廠商可以透過與現有的產品(如儲存解決方案、compute 和數據分析工具)整合,為客戶提供一站式服務。 銷售網絡上, 大型雲廠商擁有龐大的客戶基礎和資源,交叉銷售給客戶,銷售路徑也更順暢。雲廠商還能透過規模效應降低成本,提供更具競爭力的定價策略。
但 data ingestion 這個環節可能並不是雲廠商的 priority,雲廠商不會拿出足夠的預算和最好的團隊去開發、最佳化這個產品。Unstructured.io 具有更強的產品專註性和深度,能夠提供更最佳化的解決方案。 目前 Unstructured.io 在數據提取的準確性面上有優勢。作為創業公司,在客戶服務、客製化需求響應速度上也更為靈活和即時。
上下遊公司,如 Vector Database
客戶訪談表示許多向量數據庫公司也在嘗試開發自己的處理非結構化數據的 API,比如 Milvus、Chroma,Pinecone。如果向量數據庫釋出類似產品,使用者將能夠在同一平台內完成從數據預處理到儲存、檢索的全過程。不過這些公司尚未完全釋出產品,具體能力未可知。
提供非結構化數據處理工具的初創公司:
這些初創公司專註在不同的領域,如 Llamaindex、Hammerspace 提供相對綜合性的數據處理工具,Clarifai 專註影像和影片處理。
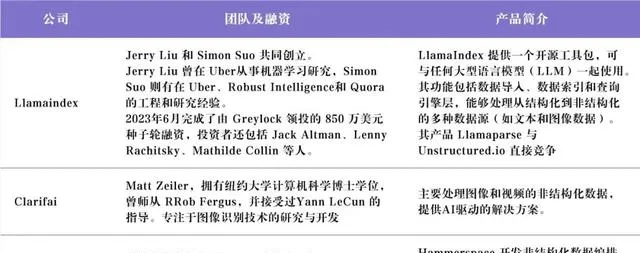
其中 llamaindex 的非結構化數據提取工具 llamaparse 與 Unstructured.io 直接競爭。llamaindex 的 end-to-end 的開源生態對 Unstructured.io 存在一定的挑戰。我們在 Unstructured.io 的 Slack 中觀察到,很多使用者有整合Llamaindex 的需求,llamaparse 也做到了類似 Unstructured.io 的產品準確性。這也進一步證實了非結構化數據 injestion 可能並不具備明顯的技術壁壘,更多的是工程上最佳化的問題。
我們認為兩家公司未來可能會獲取不同的客戶群,與其他初創公司相比, Unstructured.io 的市場定位更專註於大型企業和政府部門,這些領域對數據安全性、準確性和專業化需求更高。 而 LlamaIndex 可能更多面向需要快速整合和靈活性的中小型企業和開發者社區。
04.
結論與猜想
Unstructured.io 目前的核心優勢有兩點。
其一是先發優勢和團隊的工程能力,使得 Unstructured.io 的 data ingestion 的產品效果領先絕大部份競爭對手一個身位。 但這個優勢很容易被資源更充足的大廠,或技術實力更強的創業公司追平,如 llamaprase 已經達到了類似的效果。
其二是團隊對大企業和政府需求的理解足夠深,擁有豐富的政府資源,這使其在商業化上保持領先。 Unstructured.io 的核心團隊由政府官員、大企業高管、AI Researcher 組成,資源硬核且懂大企業的需求。CEO Brian 的政府資源以及政府在非結構化數據處理上的旺盛需求也使得 Unstructured.io 能獲得大量政府的訂單。
單點的產品功能優勢難以建立起長期的競爭壁壘, Unstructured.io 面臨著大型雲廠商、上下遊公司,以及已經搭建了完整 RAG 開源工具的初創公司如 llamaindex 等公司的競爭。目前RAG處於發展早期,還難以預判未來的格局。 不過我們對 Unstructured.io 的發展有較強的信心,llamaindex 的開源框架容易被「露天開采」,Unstructrued.io 也在搭建 end-to-end 的 RAG 產品。如何不斷提升產品效果,服務好企業的需求才是商業化的關鍵。
非結構化數據處理未來也有很多潛在的變化可能,我們會對該領域的發展保持持續關註:
其一是 Multi-step Agents 的發展有可能改變目前的非結構化數據處理方式。 Raymond 在訪談中提到,Agents 能夠自動化數據檢索和處理,還能透過多步推理顯著提高準確性和效率。這種轉變將減少對數據預處理的依賴,賦予 LLM 更強的處理復雜任務的能力。 目前使用 LLM 來執行非生成性任務(如數據轉換)的技術還沒實作,但隨著模型 reasoning 能力的提升有一定的發展潛力。
另外,多模態 LLMs 會擴充套件數據處理的範疇,可能會改變 RAG 和 ETL 的工作流程。 隨著模型能夠處理和解析影像、影片等多種媒體,企業可能需要重新設計數據轉換和檢索 pipeline,更好地利用這些新能力,這也為創業公司帶來了機會。


排版:Doro
LLM的範式轉移:RL帶來新的 Scaling Law
AGI 市場展望 | AGIX 投什麽
RL 是 LLM 的新範式
Twelve Labs: 多模態重塑影片內容檢索
答 AI 的 6000 億美元問題:LLM 套用會如何崛起?|AGIX 投什麽











