[CSP-J 2021 T4] 小熊的果籃
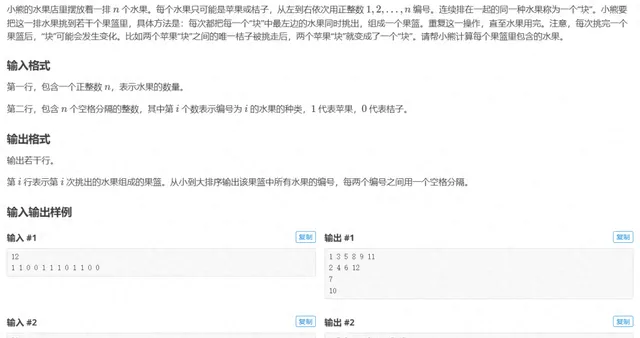
正文開始
本題的題意還是非常容易理解的。把每個「水果塊 」的第一個水果的 編號 輸出,另 外取走水果後如果相鄰水果塊種類相同,還要考慮這兩個水果塊 合並 的問題。
老規矩,做題前先看數據範圍:

「提示」很友好,不多見。國人出題擅長挖坑,主動提示避坑的少之又少.
騙分
顯然,對於 的數據點, 暴力求解 就可以。每次從隊首 開始掃描,只要 與前一個塊的水果 (用 last 記錄,第一次賦值為-2 ,確保跟陣列中的所有值不一 樣)不一樣,就輸出 編號 ,並順便把已輸出的水果標記為-1 (表示該位置水果已 經被取走),下次掃描碰到-1 就跳過。如果一共輸出了 n 次(用 cnt 記錄),說明 把所有水果都輸出了,結束!
程式碼如下:

送出後:
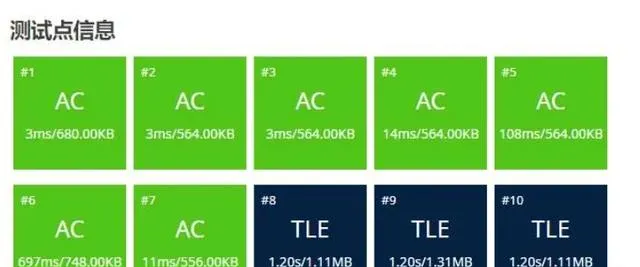
居然有 70 分!成功來得太突然!本來只是隨便玩玩,結果離 AC 只差了 3 毫米!
那麽為什麽 n<=50000 的數據也能過呢?說明每次 for 迴圈中,輸出的 i 次數比 較多,cnt++ 不斷執行,所以外層的 while(cnt <n) 執行次數不多,應該不超過2000 次 。如果有一個數據點,全部都是 1 ,或者全部都是 0 ,上述演算法應該是過 不了的。
對於這道題,除了這麽簡單的做法,很多同學可能會想到用連結串列 list 。每次拿走 一個水果,就把它從連結串列中刪除,那麽下次再繼續從頭掃描的時候,連結串列已經變 短了,從頭到尾掃描的次數會越來越少。但實際上,這種做法,跟我們上面用陣列暴力檢索 沒有太本質的區別 。不信我們來寫一下用連結串列 list 做這道題:
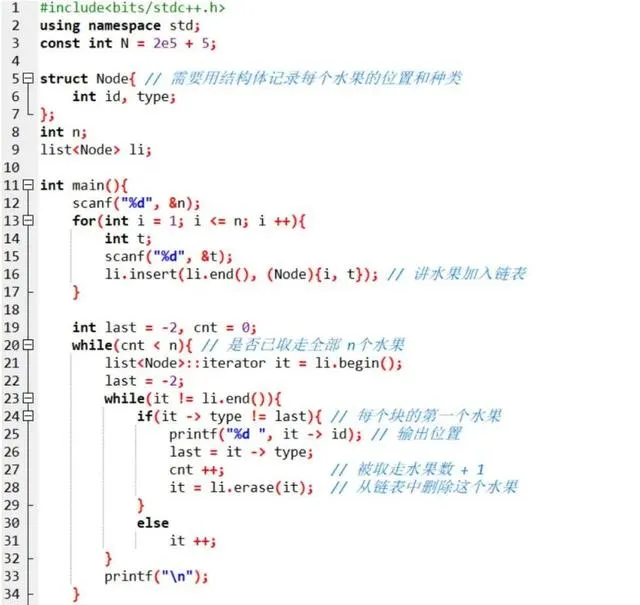
送出後也是 70 分:

超時的最主要原因,是每一個「 塊 」中間大量不用輸出的節點,也遍歷了一遍,花 了很多時間。能不能想一個辦法,對於每個塊,只存取「 塊 」頭的元素。輸出「 塊 」 頭的元素的編號後,就接著存取下一個「 塊 「。
思考
我們可以這樣處理,把每個「 塊 「作為數據處理點,把」 塊 「的第一個元素的編號 (標 記為:L )和最後一個元素的編號 (標記為:R ),以及」 塊 「的水果類別(標記為:type )記住,然後這些水果就按」 塊 「進行排列了。
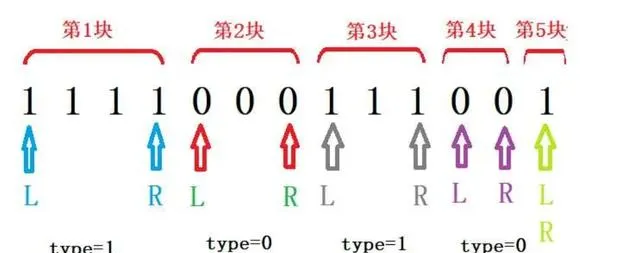
」 塊 「的數量,可能就比水果的數量少很多,這會使得迴圈時需要遍歷的次數少一 些。
由於每迴圈操作一次後,要輸出換行,所以我們特意加了一個所謂的 末尾塊 。在 每一輪結束後,如果檢索到了 末尾塊 ,那麽輸出回車。 末尾塊 每次都要 push 進 佇列,所以當水果都取完的時候,佇列的 size 應該是1 。
程式碼如下:
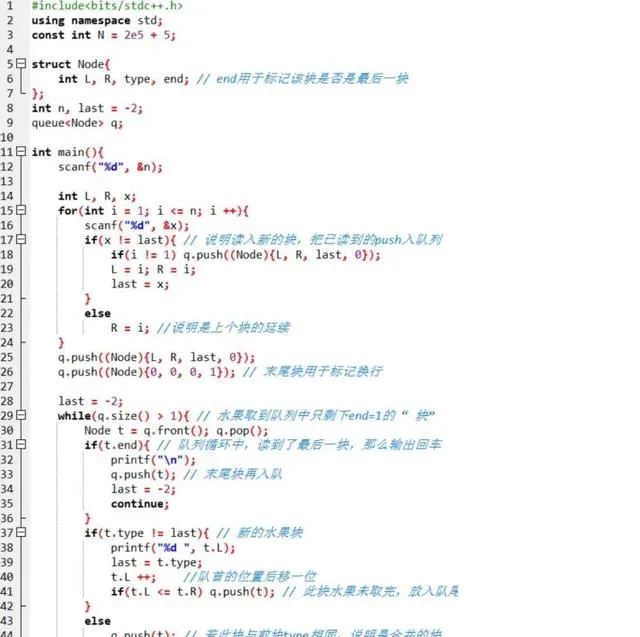
送出後:

多了寶貴的 10 分!不容易啊!
思考一下,為什麽會超時?假設有很多 塊 ,其中只含有一個水果,那麽它被取走 後,它 後面的水果塊 應該與 前面的水果塊 合並,但是按照我們上述程式碼,實際上 並沒有合並,而是直接 push 進入 queue 後面,而且每一輪都如此。那麽如果碰 到與前一塊 type 相同的塊,數量非常多時,是非常耗時的。整個復雜度為 O (), 過不了關。
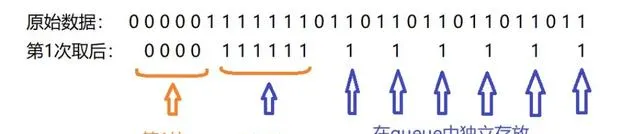
如上所示,第一次取後,後面那些 1 ,是獨立的塊 ,但它們應該和第 2 塊合並。這些 1 很晚才會被取走,因為沒合並,所以每次需要不斷地取出並重新 push 入queue ,非常耗時。
AC
那麽,我們能否想個辦法,當發現前後的塊 ,type 相同時進行合並成一塊?這個 想法的難點在於,合並後的主要資訊( 編號 )是離散的,不是連續的,如果要用陣列 或 vector 保存,需要把每個編號 都保存下來,這增加了記憶體開銷。我們需要另外想一個辦法。
我們的解決辦法是另外設一個 臨時的佇列 tmp 。每輪取走水果後,如果塊 中還有 水果,則把該塊放入臨時佇列 tmp 。然後,對 tmp 進行集中處理,合並其中水果相同的塊 (我們只需要 把前面塊的右端點延長到後面塊的右端點即可實作合並 ), 再 push 進佇列 q 中。這時候,q 中原本很大的 size 會大大下降,因此能大幅 降低演算法復雜度 。另外,合並後的塊,未取走的水果編號不連續的問題,可以透過t.L 單向移動來解決。
最終這個演算法復雜度是多少?由於 t.L 總是是從左往右單向移動,而且每輪必定 會從這些塊中各取走 1 個水果,因此復雜度大約是 O(n) 。
程式碼如下:
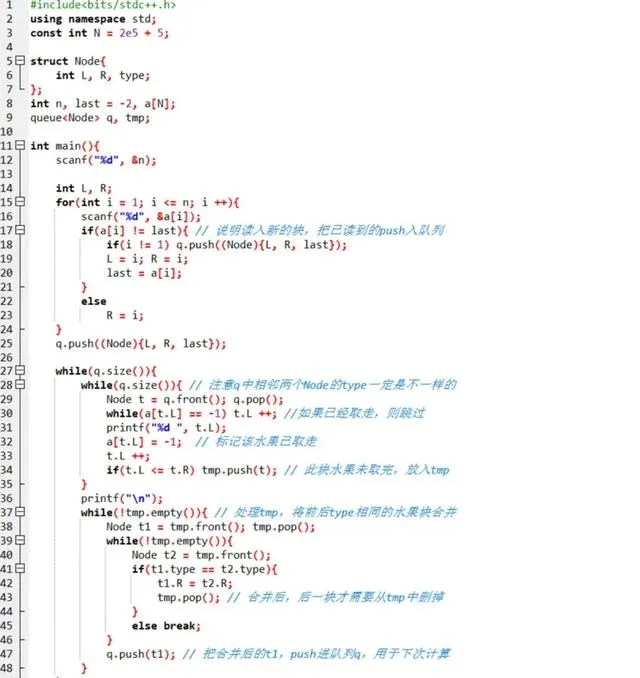
送出後,果然 AC!

總結:
這道題我們開始的時候用最簡單的陣列保存,並且暴力列舉 ,居然就得了 70 分。這種方式每次都從頭到尾掃描 n 次 ,顯然太復雜,所以我們按「塊」對數據進行 處理,不需要每次掃描 n 次,只需要掃描塊數(一般情況下比 n 小) ,但本質上也沒有大幅降低復雜度,因為「零碎」的塊可能很多。因此我們又單獨引入另外一個佇列 ,專門處理「塊」的合並 ,這樣就快多了.












