
編譯 | Vendii
編輯 | 漠影
智東西8月28日訊息,AI芯片獨角獸Cerebras Systems於8月27日宣布推出AI推理服務Cerebras Inference,號稱「全球最快」。該服務已經在雲端上線。
據官網介紹,該推理服務在保證精度的同時,速度比輝達的服務快20倍;其處理器記憶體頻寬是輝達的7000倍,而價格僅為GPU的1/5,價效比提高了100倍。Cerebras Inference還提供多個服務層次,包括免費、開發者和企業級,滿足從小規模開發到大規模企業部署的不同需求。
使用者可直接在官網上的互動界面進行體驗,也可呼叫API。
體驗地址:https://inference.cerebras.ai/
Cerebras Systems成立於2016年,團隊由電腦架構師、電腦科學家、深度學習研究人員和各種工程師組成。該公司以其創新的晶圓級芯片(Wafer Scale Engine, WSE)而聞名,這些芯片專為AI計算而設計,具有巨大的尺寸和效能。
這家芯片獨角獸曾經得到多個知名投資者的支持,其中包括OpenAI聯合創始人Sam Altman、AMD前CTO Fred Weber等。截至2021年11月,該公司完成了2.5億美元的F輪融資,估值達到40億美元。
AI推理指的是在訓練好一個AI模型之後,使用這個模型對新的數據進行預測或決策的過程。AI推理的效能和效率對於即時套用至關重要,例如自動駕駛汽車、即時轉譯或線上客服聊天機器人等。Cerebras Inference(以下稱作「Cerebras推理服務」)便是一個專註於AI推理的服務,以支持這些對即時性要求極高的套用場景。
Cerebras推理服務由Cerebras CS-3系統及其第三代晶圓級芯片(WSE-3)提供支持。WSE-3於3月釋出,基於2021年推出的WSE-2芯片進行了改進。WSE-3記憶體頻寬高達21PB/s,是輝達H100 GPU的7000倍。這種超高的記憶體頻寬可以大幅減少數據傳輸時間,提高模型推理的速度和效率。
據官網介紹,Cerebras推理服務針對Llama 3.1 8B模型每秒提供1800個tokens,每百萬tokens的價格為10美分;針對Llama 3.1 70B模型每秒提供450個tokens,每百萬tokens的價格為60美分。速度比基於輝達GPU的超大規模雲解決方案快20倍。

▲Cerebras推理服務與其他服務在Llama 3.1 8B上的速度比較。單位:tokens/秒/使用者。(圖源:Cerebras官網)
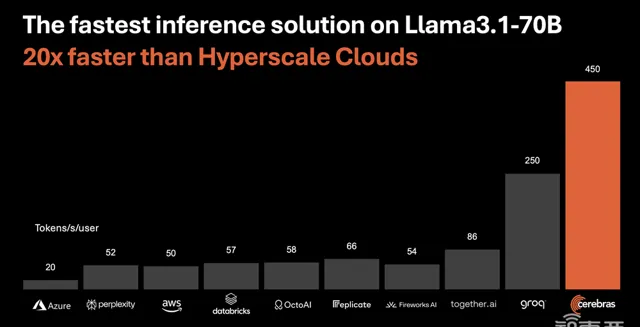
▲Cerebras推理服務與其他服務在Llama 3.1 70B上的速度比較。單位:tokens/秒/使用者。(圖源:Cerebras官網)
此外,Cerebras推理服務在整個推理過程中始終保持在16位元精度域內,確保在提升速度的同時不會犧牲模型的精度。大語言模型品質評估公司Artificial Analysis的聯合創始人兼CEO Micah Hill-Smith談道,他的團隊已經驗證了Llama 3.1 8B和Llama 3.1 70B模型在Cerebras推理服務上執行的品質評估結果:與Meta官方版本的原生16位元精度一致。
跟據官網,該服務執行Llama3.1的速度比基於輝達GPU的解決方案快20倍,而提供服務的芯片WSE-3價格僅為GPU的1/5,相當於AI推理工作負載的價效比提高了100倍。
「在Artificial Analysis的AI推理基準測試中,Cerebras推理服務已經領先。Cerebras推理服務的速度比基於GPU的解決方案快一個數量級,打破了測試的紀錄。」Micah Hill-Smith說,「憑借推動超高的效能速度和具有競爭力的定價,Cerebras推理服務對具有即時或高容量需求的AI套用開發者特別具有吸重力。」
Cerebras推理服務根據使用者需求和使用情況,提供了分級制度,分為三個層級:
1、免費層級:這一層級為所有登入使用者提供免費的API存取許可權以及相對寬松的使用限制。使用者可以在這個層級中體驗,無需支付費用。
2、開發者層級:這一層級專為靈活的無伺服器部署設計,為使用者提供一個API端點。相比於市場上的大多數方案,其成本要低得多。對於Llama 3.1 8B和Llama 3.1 70B模型,每百萬tokens的價格分別是10美分和60美分。未來,Cerebras計劃持續推出對更多模型的支持。
3、企業層級:這一層級提供經過微調的模型、客製的服務級別協定和專門的支持。它適合需要持續的工作負載。企業可以透過Cerebras管理的私有雲或在企業的本地部署存取Cerebras推理服務。可按需求定價。
Cerebras推理服務的這種分級制度旨在滿足從小規模開發到大規模企業部署的不同需求。
在推動AI開發的戰略合作夥伴關系中,Cerebras Systems正與一系列行業領導者合作,共同構建AI套用的未來生態。這些公司在各自的領域內提供關鍵技術和服務,比如,Docker旨在利用容器化技術使AI套用部署更加便捷和一致,LangChain為語言模型套用提供快速開發框架,Weights&Biases打造了供AI開發者訓練和微調模型的MLOps平台……
「LiveKit很高興能與Cerebras合作,幫助開發者構建下一代多模態AI套用。結合Cerebras的計算能力和模型以及LiveKit的全球邊緣網路,所開發的語音和視訊AI套用將實作超低延遲並更接近人類特征。」LiveKit公司的CEO兼聯合創始人Russell D’sa說道,該公司專註於構建和擴充套件語音和視訊應用程式。
AI搜尋引擎創企Perplexity的CTO兼聯合創始人Denis Yarats認為,Cerebras推理服務可以幫助AI搜尋引擎在使用者互動方面實作突破,從而提高使用者參與度。
根據國際數據公司(IDC)的研究,AI推理芯片在2020年已經占據了中國數據中心市場的50%以上份額,並預計到2025年,這一比例將增長至60.8%。據輝達2024財年數據中心的業績會紀要,其公司該年度有超過40%的收入來自AI推理業務。可見,AI推理不僅在當前市場中占有相當比例,而且預計在未來幾年將繼續保持增長勢頭。
Cerebras憑借其超快的推理速度、優異的價效比和獨特的硬體設計,將賦予開發者構建下一代AI套用的能力,這些套用將涉及復雜、多步驟的即時處理任務。
然而,在生態系的成熟度、模型支持的廣泛性以及市場認知度方面,輝達仍然占據優勢。相比於Cerebra,輝達擁有更大的使用者群體和更豐富的開發者工具和支持。此外,雖然Cerebras支持主流模型(如Llama 3.1),但輝達的GPU支持的深度學習框架和模型範圍更廣。對於已經深度整合在輝達生態系中的使用者,Cerebras可能在模型支持的廣度和靈活性方面略顯不足。











