該不該從零開始預訓練一個千億級大模型?
這個問題從 2023 年 ChatGPT 破圈之後就一直成為行業人士的 Top 討論話題之一。不久前,國內也有報道號稱排名前六的「大模型六虎」中至少有兩家已經放棄大模型的預訓練、轉向 AI 套用,零一萬物就是其中之一。
背後原因無他:預訓練的成本高,企業「算不過來賬」。
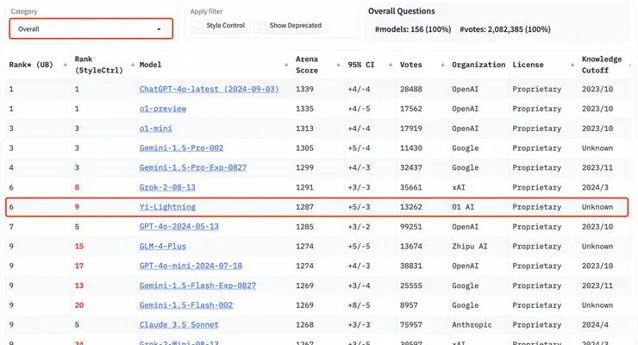
但就在今天,繼千億參數模型 Yi-Large 之後,零一萬物又釋出了新的預訓練旗艦模型 Yi-Lightning(號稱「閃電」),在國際權威盲測榜單 LMSYS 上超越了 OpenAI 今年 5 月釋出的 GPT-4o、Anthropic Claude 3.5 Sonnet,排名世界第六,中國第一。
這是在 LMSYS 這一全球大模型必爭的公開擂台上,中國大模型首度實作超越 OpenAI GPT-4-2024-05-13!
根據榜單排名,零一萬物緊隨 OpenAI、Google 之後,與 xAI 打平,進擊全球前三大模型企業,以優異模型效能穩居世界第一梯隊大模型公司之列。
模型效能升級之余,Yi-Lightning 的推理速度也有大幅提升,首包時間較上半年釋出的 Yi-Large 減少一半。最高生成速度提速近四成,堪稱「極速」。
同時,Yi-Lightning 還在保持高效能的同時,實作了推理成本的進一步下降,每百萬 token 僅需 0.99 元,直逼行業最低價,以極致價效比助力開發者與企業客戶輕松實作 SOTA 大模型自由。
目前 Yi-Lightning 已上線 Yi 大模型開放平台:
https://platform.lingyiwanwu.com/。

在李開復看來,雖然中國在大模型的預訓練上落後於美國,但不代表中國大模型公司會放棄「預訓練」這一戰略級步驟。另外,中國的大模型在預訓練速度上其實沒有比美國落後很多,以 OpenAI 為例:今年 5 月 13 日 OpenAI 釋出GPT-4o-2024-05-13,零一萬物 Yi-Lightning 在今年 10 月就超過了 GPT-4o-2024-05-13,僅五個月的時間差。
縮短時間差,是因為零一萬物在各個維度的人才儲備與知識積累上都足夠紮實。
預訓練的門檻很高,需要團隊具備芯片人才、推理人才、基礎架構人才、演算法人才等。由此來看,並不是所有的大模型公司都具備大模型預訓練的條件。對於這些公司來說,放棄預訓練其實是明智的選擇;但零一萬物從創業的第一天起就堅持「模基共建」、「模型+Infra+套用」三體合一,沒有放棄的理由。
此外,Yi-Lightning 打平了 xAI 的 Grok。xAI 在訓練 Grok 時號稱用了幾萬張 GPU,但零一萬物透露,他們此次釋出的 Yi-Lightning 訓練只用了兩千張 GPU、訓練了一個半月,只花了 300 多萬美金。也就是說,零一萬物用了 xAI 的 2% 左右的成本就打平了 Grok。
零一萬物的特點是「模基共建」。他們不僅追求模型的效能,也追求模型的推理成本,而 AI infra 與上層模型的同步最佳化是實作這一目標的關鍵手段。
LMSYS 評測:效能超越 GPT-4o
LMSYS Org 釋出的 Chatbot Arena 憑借著新穎的「真實使用者盲測投票」機制與 Elo 評分系統,已成為全球業界公認最接近真實使用者使用場景、最具使用者體感的「大模型奧林匹克」。
隨著 Yi-Lightning 的加入,LMSYS ChatBot Arena 總榜排名再次發生震蕩。在 LMSYS 總榜上,Yi-Lightning 的最新排名勝過矽谷頭部企業 OpenAI、Anthropic 釋出的 GPT-4o-2024-05-13、 Claude 3.5 sonnet,在一眾國內大模型中拔得頭籌,超越 Qwen2.5-72b-Instruct、DeepSeek-V2.5、GLM-4-Plus 等。
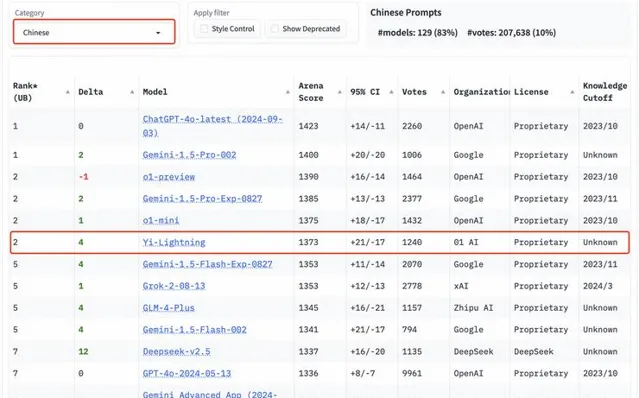
在眾多分榜上,Yi-Lightning 的成績同樣出眾。在中文分榜上,Yi-Lightning 超越了 xAI 釋出的 Grok-2-08-13、智譜釋出的 GLM-4-Plus 等國內外優質模型,與 o1-mini 等模型並列排名世界第二。
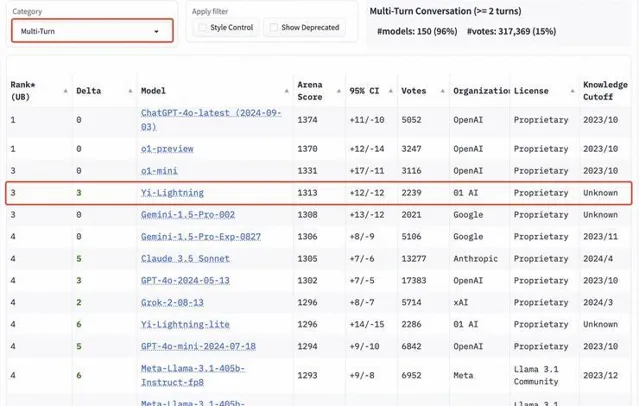
在多輪對話分榜上,Yi-Lightning 則是超越了 Google 所釋出的 Gemini-1.5-Pro 、Anthropic 釋出的 Claude 3.5 Sonnet 等知名旗艦模型,排名第三。
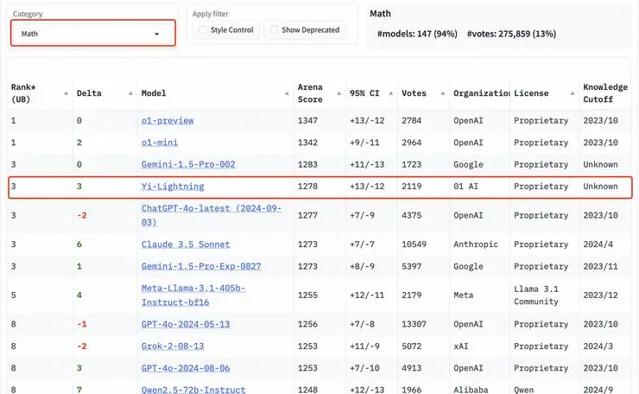
數學能力,程式碼能力方面,Yi-Lightning 同樣處於全球第一梯隊。在數學、代分碼榜上,Yi-Lightning分別取得第三、第四名。
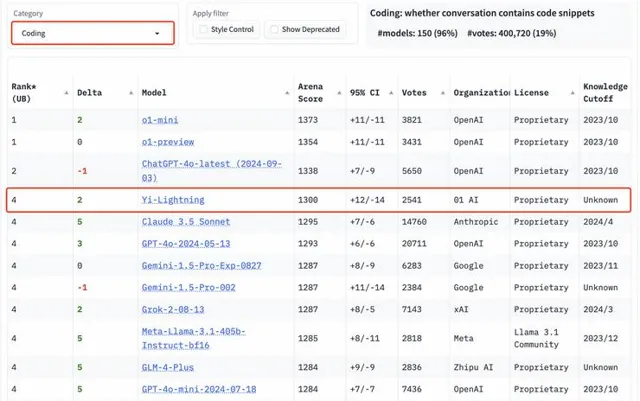
以專業性與高難度著稱的艱難提問、長提問榜單上,Yi-Lightning 的表現依舊出眾,均取得世界第四的優異成績。
LMSYS Chatbot Arena 的使用者體驗評估體現了 Yi-Lightning 的出色效能,也更為直觀地驗證了大模型解決真實世界問題的能力。
換言之,Yi-Lightning 能夠絲滑地由實驗室場景過渡到模擬真實使用者場景,能夠更快、更高品質地實作模型能力落地。
作為模型落地的典型場景之一,轉譯場景十分全面地考驗了模型語言理解和生成、跨語言能力、上下文感知能力,透過 Yi-Lightning 與 Qwen2.5-72b-Instruct、DeepSeek-V2.5、Doubao-pro 的對比,Yi-Lightning 優異的模型效能也得到了最直觀的展現:

推理速度飛升生成速度較 Yi-Large 最高提升近四成
從命名可以看出,與 Yi-Large 相比,Yi-Lightning 在模型效能更進一步的前提下,推理速度方面有著極大提升。
這一方面得益於零一萬物自身世界一流的 AI Infra 能力,另一方面則是由於,與此前稠密模型架構不同,Yi-Lightning 選擇采用 Mixture of Experts(MoE)混合專家模型架構,並在模型訓練過程中做了新的嘗試。
內部評測數據顯示,在 8xp00 算力基礎下,以同樣的任務規模進行測試,Yi-Lightning 的首包時間(從接收到任務請求到系統開始輸出響應結果之間的時間)僅為 Yi-Large 的一半,最高生成速度也提升了近四成,大幅實作了旗艦模型的效能升級。
外部模型中,零一萬物選擇與 GPT-4o 支持下的 ChatGPT 做對比。僅憑肉眼就可以看出,Yi-Lightning 的生成速度,堪稱「極速」。
如何在保持模型效能接近最優的同時,盡可能減少啟用參數的數量以降低訓推成本、提升推理速度,是 MoE 模型訓練的重點目標。具體到 Yi-Lightning 模型的訓練,零一萬物的模型團隊進行了如下嘗試,並取得了正向反饋:
1.獨特的混合註意力機制(Hybrid Attention)
此前關註 MoE 架構的大模型公司,如 Mistral AI ,大多采用了 Sliding Window Attention(滑動視窗註意力機制)。這種機制透過在輸入序列上滑動一個固定大小的視窗來限制每個位置的關註範圍,從而減少計算量並提高模型的效率和可延伸性。但是同樣受限於固定視窗,模型可能無法充分考慮序列中較遠位置的資訊,導致資訊理解不完整。
在 Yi-Lightning 的訓練過程中,零一萬物采用了混合註意力機制(Hybrid Attention)。這種機制只在模型的部份層次中將傳統的全註意力(Full Attention)替換為滑動視窗註意力(Sliding Window Attention),旨在平衡模型在處理長序列數據時的效能和計算資源消耗。透過這種方式,Yi-Lightning 能夠在保持模型對長序列數據的高效處理能力的同時,降低計算成本。
結合這兩項技術,零一萬物成功地將 Yi-Lightning 模型在面對長序列數據時的表現保持在較高水平,同時顯著降低了 KV 緩存的大小,實作了 2 倍至 4 倍的減少;某些層次的計算復雜度也由序列長度的平方級降低到線性級,進一步提高了模型的計算效率。這些改進使得 Yi-Lightning 模型本身在處理長序列數據時更加高效。
基於模基共建戰略,零一萬物在 AI Infra 方面也做出了進一步最佳化,結合 Yi-Lightning 的自身特性,共同確保了模型即便在資源受限的環境下也能夠保持穩定、出色的表現。
2. 動態 Top-P 路由
面對簡單的任務,MoE 模型可選擇啟用較少的專家網路以加快推理速度,同時保持良好的效能;面對更復雜的任務,MoE 模型則可以啟用更多的專家網路可以提高模型的準確性。
動態 Top-P 路由就像是 MoE 模型中做出選擇的「把關人」。它可以根據任務的難度動態自動選擇最合適的專家網路組合,而無需人工幹預。與傳統的 Top-K 路由機制相比,動態 Top-P 路由能夠更靈活地根據任務的難度調整啟用的專家網路數量,從而更好地平衡推理成本和模型效能。
在 Yi-Lightning 訓練過程中,零一萬物選擇引入動態 Top-P 路由機制,這使得 Yi-Lightning 能夠更加智慧地適應各種任務需求,這也是它能夠實作「極速推理」的一大原因。
3. 多階段訓練(Multi-stage Training)
在 Yi-Lightning 的訓練規劃中,零一萬物還改進了單階段訓練,使用了多階段的訓練模式。據介紹,在訓練前期,零一萬物模型團隊更加註重數據的多樣性,希望 Yi-Lightning 在這個階段盡可能廣泛地吸收不同的知識;而在訓練後期則會更加側重內容更豐富、知識性更強的數據。
透過這種各有側重的方式, Yi-Lightning 得以在不同階段吸收不同的知識,既便於模型團隊進行數據配比的偵錯工作,同時在不同階段采用不同的 batch size 和 LR schedule 來保證訓練速度和穩定性。
結合多階段的訓練策略,輔之以自創高品質數據生產管線,零一萬物不僅可以保證 Yi-Lightning 的訓練效率,還可以讓 Yi-Lightning 在具備豐富知識的同時,基於復雜且重要的數據做進一步的強化。此外,在有較多新增數據、或者想要對模型進行專有化時,零一萬物也可以基於 Yi-Lightning 進行快速、低成本的重新訓練。相較於傳統的單階段訓練,這樣的訓練方法既可以保證模型整體的訓練效果,同時也能更高效地利用訓練數據。
閃電秘訣:「模型+AI Infra+套用」三體布局
國內大模型賽道狂奔進入第二年,商業化造血能力已經成為多方關註的焦點。而無論是 ToC 還是 ToB,如何提前預判 TC-PMF 是繞不開的核心命題。模型效能與推理成本,兩項關鍵因素直接影響著大模型落地的成敗。
Yi-Lightning 已在 LMSYS 等多項國際權威評測中取得 SOTA 成績,同時支持極速推理,模型效能已得到驗證。而基於 MoE 模型架構與零一萬物的 AI Infra 優勢,Yi-Lightning 的推理成本也降至行業新低。
目前, Yi-Lightning 已經上線 Yi 大模型開放平台(https://platform.lingyiwanwu.com/),每百萬 token 僅需 0.99 元,直逼行業最低價,支持開發者與企業客戶輕松實作 SOTA 大模型自由。
基於模型效能顯著升級、推理成本大幅下降、同時可實作極速推理的 Yi-Lightning,零一萬物可探索的落地場景將會進一步擴充套件。
10月16日,零一萬物也首度對媒體公布了全新 ToB 戰略下的先發行業套用產品 AI 2.0 數位人,聚焦零售和電商等場景,將最新版旗艦模型實踐到行業解決方案,在彈幕互動、商品資訊提取、即時話術生成等環節,AI 2.0 數位人已接入 Yi-Lightning。接入 Yi-Lightning 後,數位人的即時互動效果更好,話術更絲滑,回復也更準確;業務數據方面,在接入 Yi-Lightning 全新加持的數位人直播後,某酒旅企業的 GMV 較此前上升 170%。
,時長00:46Yi-Lightning數位人對比視訊同時, Yi-Lightning 的「極速」不僅體現在模型推理速度,客製模型的交付速度也會得到極大提升。受益於 MoE 模型的自身特性、在多階段訓練方面的技術積累,零一萬物能夠基於客戶的特殊需求,進行高效地針對性訓練,快速交付貼合特定服務場景、極速推理、成本極低的私有化客製模型。
打造新質生產力
進入2024年以來,中國大模型行業從狂奔進入到了「長跑階段」,從技術側和產業側都引發了行業的進一步思考。
從技術發展上看,在算力受限的情況下,中國基座模型的研發能力處在世界什麽身位,如何追趕國外頂尖大模型等問題引發外界關註。甚至一度傳出「中國可以不用再研發預訓練基座模型」的說法。
零一萬物此次推出的Yi-Lightning模型一經亮相,就在世界權威的盲測榜單LMSYS中擊敗了OpenAI今年五月釋出的GPT-4-2024-05-13。中國大模型首度超越效能極佳的 GPT-4-2024-05-13 對於中國人工智慧發展是個裏程碑事件,彰顯了中國所孕育的強大技術實力。
根據線上成果展示,零一萬物的 Yi-Lightning 轉譯莎士比亞的作品,只要 5 秒鐘;其他模型是 Yi-Lightning 的 2 到 3 倍。
這些都彰顯了中國大模型公司「模型+基礎設施+套用」「三位一體」全棧式布局的必要性和重要性。
GPT-4o 之後,o1 的釋出是一種新技術範式的開始,代表著大模型的重點從預訓練到推理。接下來零一萬物也會朝著這個方向去發展。
AGI 仍在遠方,現階段更需要讓大模型能力落地套用層, 推動整個大模型行業形成健康的生態。
在這一階段,零一萬物會堅持「模型+AI Infra+套用」三位一體的全棧式布局,以國際 SOTA 的基座模型為基礎,積極在 ToB 企業級解決方案上探索 TC-PMF,以更從容的姿態迎接即將到來的 AI 普惠時代。
雷峰網











