編輯:編輯部
【新智元導讀】是時候用CPU通用伺服器跑千億參數大模型了!
馬斯克19天建成由10萬塊p00串聯的世界最大超算,已全力投入Grok 3的訓練中。
與此同時,外媒爆料稱,OpenAI和微軟聯手打造的下一個超算集群,將由10萬塊GB200組成。
在這場AI爭霸賽中,各大科技公司們卯足勁加大對GPU的投資,似乎在暗示著擁有更多、更強大的GPU,就能讓自己立於不敗之地。
然而,這種對高端GPU的狂熱追求,並非在所有情況下,都是完美無缺的解決方案。
Pytorch之父表示,技術報告中暗藏了很多基礎設施的有趣細節,包括如何並列化,如何讓系統更可靠等等
就拿穩定性來說,在Llama 3.1訓練的54天裏,Meta的1.6萬塊p00集群總共遇到了419次意外中斷,相當於平均每3小時發生一次。
而在這之中,有148次(30.1%)是由於各種GPU故障引起的。
相比之下,由CPU故障引發的中斷,只有2次。

另一方面,想要把Llama 3.1 405B跑起來,還得搭配2台8×p00的DGX工作站才行——即1280GB的視訊記憶體。
曾經有位勇士嘗試用一張4090執行,結果等了30分鐘,模型才緩緩吐出一個「The」。
完整的回復,花了整整20個小時
熟悉模型的訓練和推理的朋友都知道,這些事情一點都不奇怪。
集群搭建(GPU配置、網路設計、軌域最佳化等)、集群管理(即時監控、故障排除等)……個個都是「攔路虎」。
對於缺乏相關經驗和資金的公司來說,該怎麽辦?
最近,浪潮資訊的研發工程師,僅靠4顆CPU,就讓千億參數的「源2.0」在通用伺服器上跑起來了!
面對用Java編寫程式的程式碼任務,「源2.0」非常迅速地給出了結果。
再給它上一道推理題——船邊掛著軟梯,離海面2公尺,海水每小時漲半米,幾小時海水能淹沒軟梯?
同樣,AI幾乎0延遲給出了詳細的解題步驟和答案。
用通用伺服器執行千億參數大模型,可謂是前無古人,這一領域的積累完全是空白,沒有任何經驗可借鑒。
浪潮資訊,究竟是怎麽做到的?
用4顆CPU,撬動千億參數大模型
若要在單台伺服器中,實作千億參數大模型的推理,包含了2個主要階段,均對計算能力提出了硬性需求。
首先,是預填充階段,也叫做前向傳播階段。
這一階段涉及到輸入數據的處理、模型參數第一次讀取。
比如,當你輸入「給我寫一篇有關AI的文章」提示,預填充階段便會將問題中所有token、模型參數,一次性輸入計算。
有時,這一輸入可能是幾個字,也可能是幾千個字,或者是一本著作。
第一階段的計算需求有多大,主要取決於我們輸入的長度。
而在計算第一個token過程中,由於模型首次載入,會在記憶體中存放全部的權重參數,以及KV Cache等數據。
這是模型參數本身所占記憶體空間的2-3倍。
對於千億參數模型來說,大量的參數和數據輸入,需要在強大計算單元中處理。對此,它需要支持向量化指令集、矩陣計算指令集,來實作大量的矩陣乘法和張量運算。
其次,是解碼階段,即在問題全部輸入之後,模型開始輸出結果的階段。
在這個階段,對大模型唯一要求便是,輸出盡可能快。同時,挑戰不再是算力挑戰,轉而為「數據搬運」的挑戰。
它包含了兩部份「數據搬運」:
這些搬運對大模型的計算和推理速度,起到了一個決定性的作用。數據搬運很快,LLM吐字的速度也會快。
LLM輸出主要透過KV Catch,逐一生成token,並在每步生成後儲存新詞塊的鍵值向量。
因此,千億大模型的即時推理,伺服器需要具備較高的計算能力,以及較高的儲存單元到計算單元的數據搬運效率。
總而言之,在大模型推理的兩階段中,有著截然不同的計算特征,需要在軟硬體方面去做協同最佳化。
GPU不是萬能的
傳統上,GPU因其具備優越的並列處理能力,一舉成為了AI訓練和推理的首選。
成本
然而,高端GPU伺服器在市場中經常出現供不應求,極難獲取的現象。
僅有資金雄厚的科技巨頭們,諸如微軟、谷歌,才能夠承擔起這筆費用。
另一方面,不僅買不起,更是用不起。
基於GPU的雲服務租用,在推理任務中的代價卻是高昂的。對於科研人員和套用廠商來說,需要實作更高的成本效益,就得另謀他路。
視訊記憶體
此外,GPU最大的劣勢之一在於,視訊記憶體容量受限。
當前業界LLM的網路架構,已從GPT逐漸走向MoE。通向AGI的大模型參數規模,只會呈指數級增長。
這意味著,閉源/開源主流模型的尺寸只會越來越大,千億參數,甚至萬億參數模型將會成為主流。
對於百億參數模型,20-30GB視訊記憶體就夠了。然而,若想跑千億參數,大約需要200-300GB的視訊記憶體空間。
目前主流的AI芯片,視訊記憶體通常只有幾十GB,顯然放不下這麽大的模型。(目前最強的AI芯片也沒還沒達到200GB)

被低估的通用伺服器
GPU不行,那就從CPU入手。
雖然目前還搞不定模型的大規模訓練,但通用伺服器在推理任務上,卻意外有著不小的優勢。
在具體實踐的過程中,浪潮資訊的工程師們分別從硬體資源和演算法層面入手,攻克了一個個「攔路虎」。
超大記憶體+高速頻寬
算力方面, 目前領先的伺服器CPU都已經具備了AI加速功能。
類似於GPU的Tensor core,AMX高級矩陣擴充套件可以將低精度的計算做加速,編成指令集給CPU的核,利用專用的核做加速。
演算法方面, 浪潮資訊的通用伺服器可同時支持PyTorch、TensorFlow等主流AI框架,以及DeepSpeed等流行開發工具,滿足了使用者更成熟、易部署、更便捷的開放生態需求。
通訊方面, 全鏈路UPI(Ultra Path Interconnect)匯流排互連的設計,則實作了CPU之間高效的數據傳輸:
- 允許任意兩個CPU之間直接進行數據傳輸,減少了通訊延遲
- 提供了高傳輸速率,高達16GT/s(Giga Transfers per second)
此外,浪潮資訊的研發工程師還最佳化了CPU之間、CPU和記憶體之間的走路線徑和阻抗連續性。
依據三維仿真結果,他們調整了過孔排列方式,將訊號串擾降低到-60dB以下,較上一代降低了50%。
並且,透過DOE矩陣式有源仿真,找到了通道所有corner的組合最優解,讓算力效能可以得到充分發揮。
記憶體方面, 可以說是通用伺服器的最大優勢了。
對於4路伺服器來說,只需給每顆CPU插上8根32GB記憶體,就能輕松達到1TB。插滿之後甚至可以擴充套件到16TB,最大可支持萬億參數的模型。
搭配DDR5的記憶體,則可以實作4800MHz × 8bit × 8通道 × 4顆 ÷ 1024 = 1200GB/s的理論上頻寬。
實測結果顯示,讀頻寬為995GB/s、寫頻寬為423GB/s,以及讀寫頻寬為437GB/s。
這個數據,對於一些搭載GDDR視訊記憶體的GPU或加速卡,可以說是毫不遜色。
但僅靠硬體遠遠不夠
僅僅依靠硬體創新,是遠遠不夠的,CPU很難進行大模型演算法的大規模平行計算。
正如開篇所述,大模型對通訊頻寬的要求是非常高的,無論是數據計算、計算單元之間,還是計算單元與記憶體之間。
如果按照BF16精度計算,想要讓千億大模型的執行時延小於100ms,記憶體和計算單元之間的通訊頻寬,就至少要達到2TB/s以上。
不僅如此,對於基於擅長大規模平行計算的加速卡設計的AI大模型,通用伺服器的處理器與之並不適配。
原因很明顯:後者雖然擁有高通用性和高效能的計算核心,但並沒有並列工作的環境。
通常來說,通用伺服器會將先將模型的權重傳給一個CPU,然後再由它去串聯其他CPU,實作權重數據的傳輸。
然而,由於大模型在執行時需要頻繁地在記憶體和CPU之間搬運演算法權重,這樣造成的後果就是,CPU與記憶體之間的頻寬利用率不高,通訊開銷極大。

如何解題?用演算法創新
針對以上難題,浪潮資訊提出了「張量並列」(Tensor Parallel)和「NF4量化」兩項技術創新,成功實作了千億大模型Yuan2.0-102B的即時推理。
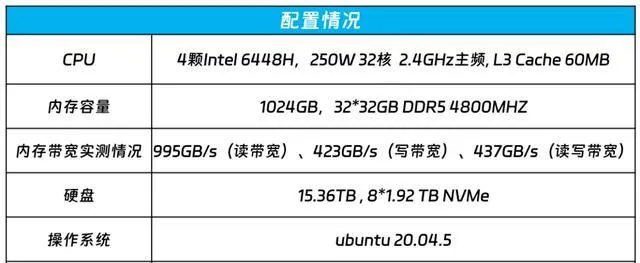
根據效能分析結果,可以清晰地看到模型中不同部份的計算時間分布——
線性層執行時間占比50%,摺積執行時間占比20%,聚合通訊時間占比20%,其它計算占比10%。
註意,在整個推理過程中,計算時間占比達到了80%!
跟使用多個PCIe的AI加速卡相比,這就形成了鮮明的對比——後者的通訊開銷可能高達50%,從而導致嚴重的算力浪費。
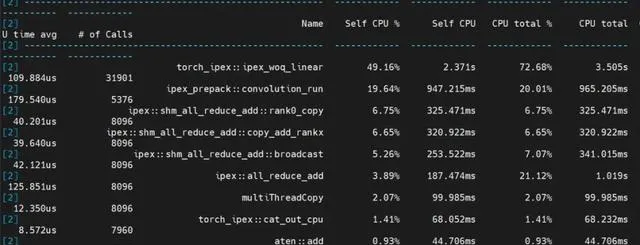
Yuan2.0-102B模型推理效能分析結果圖
張量並列
所謂張量並列,就先將摺積算子進行張量切分,然後把大模型中的註意力層和前饋層的矩陣計算權重,分別輸入到多個處理器的記憶體中。
如此一來,通用伺服器中的4顆CPU便可同時獲取演算法權重,進行計算加速。
不過,張量並列對模型參數的切分粒度較細,要求CPU在每次張量計算後都要進行數據同步。
對於這個需求,前文提到的全鏈路UPI匯流排互連技術,完全可以滿足(通訊頻寬高達16GT/s)。
最終,這種協同並列工作,直接讓計算效率提升了4倍!

NF4量化
至於記憶體頻寬不足的問題,則需要在不影響精度的情況下對模型進行「瘦身,也就是量化。
其優勢在於,一方面可以將LLM參數量化成低位元數據,權重會變小。另一方面,權重縮小之後,在計算時傳輸的數據量也會變小。
這裏,浪潮資訊采用了一種並不多見的分位數量化方法——NF4(4位元NormalFloat)。
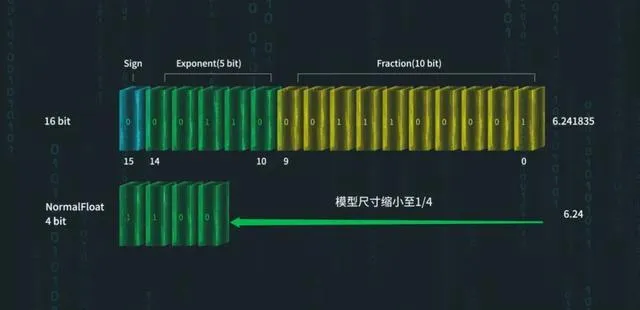
NF4量化方法可將Yuan2.0-102B的尺寸壓縮到原來的1/4
具體來說,NF4的核心思想是,確保量化區間內輸入張量的值數量相等。
這個特點,恰恰非常適合呈現近似正態分布的LLM權重。
由於可以透過調整標準差來適配量化數據型別的範圍,NF4相較於傳統的4位元整數或4位元浮點數量化,可以獲得更高的精度。
如此一來,量化之後的模型既能滿足精度需求,又能大幅降低大規模平行計算的訪存數據量,從而達到了即時推理的解碼需求。

整數或浮點數量化方法的數據間隔通常是平均分布或指數分布的
為了進一步壓縮模型的權重參數,團隊還采用了巢狀量化(Double Quant)技術。
這是在NF4量化基礎上,進行了二次量化。
因為NF4量化後會產生大量的scale參數,如果使用32位元浮點數(FP32)儲存,會占用大量記憶體。
對於一個千億參數的LLM,若以每64個參數作為一個量化塊(block size=64)來計算,僅儲存scale參數就需要額外的6GB記憶體:(100B ÷ 64) × 4 = 6GB。
團隊透過將這些scale參數量化到8位元浮點數(FP8),顯著減少了所需的儲存空間。
在采用256為量化塊大小(block size=256)的情況下,儲存所有scale參數所需的額外空間僅為1.57GB:(100B ÷ 64 ÷ 256) × 4 + (100B ÷ 64) × 1 = 1.57GB.
透過巢狀量化,模型的每個權重參數最終僅占用4字節的記憶體空間,比原始FP32節省了大量的記憶體占用空間。
與此同時,它將從記憶體到CPU的數據搬運效率,提高了4倍。
這樣的最佳化顯著減輕了記憶體頻寬對Yuan2.0-102B模型推理解碼效率的限制,從而進一步提升了模型的推理效能。
所謂通用,就是讓大家都用上
到這裏,浪潮資訊就成功交卷了!
透過系統最佳化,浪潮資訊的NF8260G7,在業界首次實作了僅基於通用處理器,支持千億參數大模型的執行。
至此,通用算力可支持的AI大模型,參數規模突破了千億,徹底填補了行業空白,成為了企業擁有AI的新起點。
千億參數AI的模型的部署,從此有了效能更強、成本更經濟的選擇;AI大模型套用,可以和雲、大數據、資料庫,實作更緊密的融合。

科技進步的最終目的,一定是落入凡間。
放眼當下,AIGC已經滲透進千行百業。AI已經以驚人的速度,滲透進了每一個計算裝置。
2024年1-4月,國內大模型的中標數量,已經超越了2023全年總數,中標披露金額已經達到了2023年全年的77%。
在金融行業、醫院門診部,企業的IT部門,從業者都發現了這一點:傳統行業的算力基礎設施,已經不夠用了!
如今,千億參數大模型,是千行百業智慧湧現的關鍵。而通用算力能否執行千億參數大模型,正是衡量其能否支撐千行百業智慧湧現的關鍵。
浪潮資訊的創舉,讓互聯網、金融、醫療等行業客戶可實作高效部署,首次投入就可節約80%以上的建設成本。
無論是金融防欺詐、財務數據分析、企業CRM行銷洞察、醫療智慧診斷、個人化診療方案、教育培訓等等,都將見證AI的廣泛套用。
從此,一切計算皆AI。
參考資料:
https://mp.weixin.qq.com/s/1wYt7dfoVy2J1FFkOJjRTg











