LLM在推薦系統的套用前景
關鍵詞:
大語言模型 (Large Language Model, LLM)推薦系統 (Recommendation System)深度學習 (Deep Learning)資訊檢索 (Information Retrieval)使用者個人化 (User Personalization)資料探勘 (Data Mining)互動式推薦 (Interactive Recommendation)
1. 背景介紹
1.1 問題由來
隨著互聯網和數位技術的迅猛發展,推薦系統在電子商務、社群網路、內容平台等領域得到了廣泛套用。推薦系統透過分析使用者的歷史行為、興趣偏好,自動生成個人化推薦,提升使用者體驗和轉化率。然而,傳統的基於協同過濾、矩陣分解等方法的推薦系統存在數據稀疏、冷啟動問題,難以應對大規模數據集和即時數據流的挑戰。
近年來,隨著深度學習和大語言模型(Large Language Model, LLM)技術的成熟,推薦系統進入了新的發展階段。基於LLM的推薦系統不僅能夠處理大規模、高維度的數據,還能透過模型自監督學習,捕捉使用者的語意資訊,實作更加精準、個人化的推薦。
1.2 問題核心關鍵點
LLM在推薦系統中的套用主要基於以下幾個核心關鍵點:
這些關鍵點使得LLM在推薦系統中具備了顯著優勢,推動了推薦技術的發展。
2. 核心概念與聯系
2.1 核心概念概述
為更好地理解LLM在推薦系統中的套用,本節將介紹幾個密切相關的核心概念:
這些核心概念之間的邏輯關系可以透過以下Mermaid流程圖來展示:
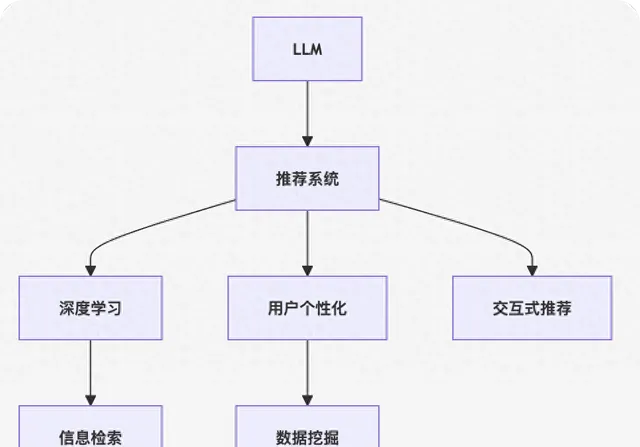
這個流程圖展示了大語言模型在推薦系統中的套用框架:
- 大語言模型透過預訓練獲得通用語言表征。
- 結合推薦系統中的使用者行為數據,進行自監督學習,捕捉使用者語意資訊。
- 透過深度學習進行特征提取和行為建模。
- 利用資訊檢索技術,從海量的產品庫中檢索潛在推薦物件。
- 根據使用者畫像和行為數據,進行個人化推薦。
- 結合資料探勘技術,提升推薦效果。
- 透過互動式推薦,動態調整推薦結果。
3. 核心演算法原理 & 具體操作步驟
3.1 演算法原理概述
基於LLM的推薦系統,本質上是一個結合了自監督學習和深度學習的推薦範式。其核心思想是:將大語言模型作為推薦系統中的特征提取器,透過自監督學習任務學習通用的語言表征,再結合使用者行為數據進行深度學習建模,最終實作個人化推薦。
形式化地,假設大語言模型為 Mθ Mθ ,其中 θ θ 為預訓練得到的模型參數。推薦系統的訓練集為 $D={(x_i,y i)} {i=1}^N,其中,其中x_i為推薦物件,為推薦物件,y_i$ 為使用者的評分或行為數據。推薦系統的最佳化目標是最小化預測誤差,即:
$$
\theta^* = \mathop{\arg\min}
{\theta} \mathcal{L}(M
{\theta},D)
$$
其中 LL 為推薦系統中的損失函式,用於衡量模型預測與真實標簽之間的差異。常見的損失函式包括均方誤差損失、交叉熵損失等。
透過梯度下降等最佳化演算法,推薦系統不斷更新模型參數 θ θ ,最小化損失函式 LL,使得模型預測逼近真實標簽。由於 θ θ 已經透過預訓練獲得了較好的初始化,因此即便在推薦系統的稀疏數據集 D D 上進行微調,也能較快收斂到理想的模型參數 θ^ θ ^。
3.2 演算法步驟詳解
基於LLM的推薦系統一般包括以下幾個關鍵步驟:
Step 1: 準備預訓練模型和數據集
Step 2: 添加任務適配層
Step 3: 設定推薦系統超參數
Step 4: 執行梯度訓練
Step 5: 測試和部署
以上是基於LLM的推薦系統的一般流程。在實際套用中,還需要針對具體任務的特點,對推薦系統進行最佳化設計,如改進訓練目標函式,引入更多的正則化技術,搜尋最優的超參陣列合等,以進一步提升模型效能。
3.3 演算法優缺點
基於LLM的推薦系統具有以下優點:
- 能夠處理大規模、高維度的數據,捕捉使用者的語意資訊,提升推薦的精準度。
- 適用於各種推薦任務,包括評分預測、行為預測、動態推薦等,設計簡單的任務適配層即可實作。
- 利用大模型的語言理解能力,可以透過互動式推薦獲取使用者即時反饋,動態調整推薦結果。
- 可以透過持續微調,適應使用者興趣和行為的變化,實作動態化的推薦。
同時,該方法也存在一定的局限性:
- 依賴高品質的標註數據,推薦數據與預訓練數據的分布差異較大時,推薦效果可能有限。
- 在稀疏數據環境下,推薦效果可能受到影響,使用者行為數據的缺失可能影響模型的泛化能力。
- 模型復雜度高,對計算資源和儲存資源的要求較高,可能面臨資源瓶頸。
- 模型自適應能力強,但可解釋性不足,難以解釋模型的決策過程。
盡管存在這些局限性,但就目前而言,基於LLM的推薦系統方法仍然是大規模推薦系統的重要範式。未來相關研究的重點在於如何進一步降低對標註數據的依賴,提高模型的少樣本學習和跨領域遷移能力,同時兼顧可解釋性和倫理安全性等因素。
3.4 演算法套用領域
基於LLM的推薦系統在電商、社交、內容等領域已經得到了廣泛的套用,覆蓋了推薦系統的各個環節,例如:
除了上述這些經典任務外,基於LLM的推薦系統還被創新性地套用到更多場景中,如多模態推薦、冷啟動推薦、個人化標簽推薦等,為推薦技術帶來了新的突破。
4. 數學模型和公式 & 詳細講解 & 舉例說明
4.1 數學模型構建
本節將使用數學語言對基於LLM的推薦系統進行更加嚴格的刻畫。
假設推薦系統中的使用者行為數據為 $D={(x_i,y i)} {i=1}^N,其中,其中x_i為推薦物件,為推薦物件,y_i$ 為使用者的評分或行為數據。
定義推薦模型 Mθ Mθ 在輸入 xi xi 上的預測為 $\hat{y} i=M {\theta}(x_i)$,則推薦系統的經驗風險為:
$$
\mathcal{L}(\theta) = \frac{1}{N}\sum_{i=1}^N [(y_i-\hat{y}_i)^2]
$$
其中 yi yi 為真實標簽,y^i y ^ i 為模型預測值。
透過梯度下降等最佳化演算法,推薦系統不斷更新模型參數 θ θ ,最小化經驗風險 L(θ)L( θ ),使得模型預測逼近真實標簽。由於 θ θ 已經透過預訓練獲得了較好的初始化,因此即便在推薦系統的稀疏數據集 D D 上進行微調,也能較快收斂到理想的模型參數 θ^ θ ^。
4.2 公式推導過程
以下我們以評分預測任務為例,推導評分預測模型的損失函式及其梯度的計算公式。
假設推薦系統中的使用者行為數據為 $D={(x_i,y i)} {i=1}^N,其中,其中x_i為推薦物件,為推薦物件,y i為使用者的評分。推薦模型為使用者的評分。推薦模型M {\theta}在輸入在輸入x_i上的預測為上的預測為\hat{y} i=M {\theta}(x_i)$,則評分預測任務的經驗風險為:
$$
\mathcal{L}(\theta) = \frac{1}{N}\sum_{i=1}^N [(y_i-\hat{y}_i)^2]
$$
根據鏈式法則,損失函式對參數 θk θk 的梯度為:
$$
\frac{\partial \mathcal{L}(\theta)}{\partial \theta
k} = -\frac{2}{N}\sum
{i=1}^N \frac{(y_i-\hat{y}_i)}{\partial \hat{y}_i} \frac{\partial \hat{y}_i}{\partial \theta_k}
$$
其中 ∂y^i∂θk∂ θk ∂ y ^ i 為輸出層對參數 θk θk 的梯度,可以進一步遞迴展開,利用自動微分技術完成計算。
在得到損失函式的梯度後,即可帶入參數更新公式,完成模型的叠代最佳化。重復上述過程直至收斂,最終得到適應推薦任務的最優模型參數 θ∗ θ ∗。
5. 計畫實踐:程式碼例項和詳細解釋說明
5.1 開發環境搭建
在進行推薦系統實踐前,我們需要準備好開發環境。以下是使用Python進行PyTorch開發的環境配置流程:
- 安裝Anaconda:從官網下載並安裝Anaconda,用於建立獨立的Python環境。
- 建立並啟用虛擬環境:
- conda create -n pytorch-env python=3.8 conda activate pytorch-env
- 安裝PyTorch:根據CUDA版本,從官網獲取對應的安裝命令。例如:
- conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c conda-forge
- 安裝Transformers庫:
- pip install transformers
- 安裝各類工具包:
- pip install numpy pandas scikit-learn matplotlib tqdm jupyter notebook ipython
完成上述步驟後,即可在 pytorch-env 環境中開始推薦系統實踐。
5.2 原始碼詳細實作
這裏我們以評分預測任務為例,給出使用Transformers庫對BERT模型進行評分預測的PyTorch程式碼實作。
首先,定義評分預測任務的評分數據處理常式:
from transformers import BertTokenizerfrom torch.utils.data import Dataset, DataLoaderimport torch class RatingDataset(Dataset): def __init__(self, ratings, labels, tokenizer, max_len=128): self.ratings = ratings self.labels = labels self.tokenizer = tokenizer self.max_len = max_len def __len__(self): return len(self.ratings) def __getitem__(self, item): rating = self.ratings[item] label = self.labels[item] encoding = self.tokenizer(rating, return_tensors='pt', max_length=self.max_len, padding='max_length', truncation=True) input_ids = encoding['input_ids'][0] attention_mask = encoding['attention_mask'][0] return {'input_ids': input_ids, 'attention_mask': attention_mask, 'labels': label}# 載入BERT預訓練模型from transformers import BertForSequence classificationmodel = BertForSequence classification.from_pretrained('bert-base-cased', num_labels=2)# 定義評分預測任務的數據集tokenizer = BertTokenizer.from_pretrained('bert-base-cased')train_dataset = RatingDataset(train_ratings, train_labels, tokenizer)dev_dataset = RatingDataset(dev_ratings, dev_labels, tokenizer)test_dataset = RatingDataset(test_ratings, test_labels, tokenizer)
然後,定義訓練和評估函式:
from torch.utils.data import DataLoaderfrom tqdm import tqdmfrom sklearn.metrics import mean_squared_errordevice = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')model.to(device)def train_epoch(model, dataset, batch_size, optimizer): dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True) model.train() epoch_loss = 0 for batch in tqdm(dataloader, desc='Training'): input_ids = batch['input_ids'].to(device) attention_mask = batch['attention_mask'].to(device) labels = batch['labels'].to(device) model.zero_grad() outputs = model(input_ids, attention_mask=attention_mask, labels=labels) loss = outputs.loss epoch_loss += loss.item() loss.backward() optimizer.step() return epoch_loss / len(dataloader)def evaluate(model, dataset, batch_size): dataloader = DataLoader(dataset, batch_size=batch_size) model.eval() preds, labels = [], [] with torch.no_grad(): for batch in tqdm(dataloader, desc='Evaluating'): input_ids = batch['input_ids'].to(device) attention_mask = batch['attention_mask'].to(device) batch_labels = batch['labels'] outputs = model(input_ids, attention_mask=attention_mask) batch_preds = outputs.logits.argmax(dim=1).to('cpu').tolist() batch_labels = batch_labels.to('cpu').tolist() for pred, label in zip(batch_preds, batch_labels): preds.append(pred) labels.append(label) print(mean_squared_error(labels, preds))
最後,啟動訓練流程並在測試集上評估:
epochs = 5batch_size = 16for epoch in range(epochs): loss = train_epoch(model, train_dataset, batch_size, optimizer) print(f"Epoch {epoch+1}, train loss: {loss:.3f}") print(f"Epoch {epoch+1}, dev results:") evaluate(model, dev_dataset, batch_size)print("Test results:")evaluate(model, test_dataset, batch_size)
以上就是使用PyTorch對BERT進行評分預測任務的完整程式碼實作。可以看到,得益於Transformers庫的強大封裝,我們可以用相對簡潔的程式碼完成BERT模型的載入和評分預測。
5.3 程式碼解讀與分析
讓我們再詳細解讀一下關鍵程式碼的實作細節:
RatingDataset類 :
評分預測模型的構建 :
訓練和評估函式 :
訓練流程 :
可以看到,PyTorch配合Transformers庫使得BERT評分預測的程式碼實作變得簡潔高效。開發者可以將更多精力放在數據處理、模型改進等高層邏輯上,而不必過多關註底層的實作細節。
當然,工業級的系統實作還需考慮更多因素,如模型的保存和部署、超參數的自動搜尋、更靈活的任務適配層等。但核心的推薦範式基本與此類似。
6. 實際套用場景
6.1 電商平台推薦
基於大語言模型的推薦系統,可以廣泛套用於電商平台推薦商品。傳統電商推薦系統往往依賴使用者歷史行為數據進行推薦,難以捕捉使用者的語意資訊,導致推薦結果不夠精準。而使用大語言模型進行推薦,可以結合使用者輸入的文本描述,進行更加個人化的推薦。
在技術實作上,可以收集使用者搜尋歷史、瀏覽記錄、評價等文本數據,將其作為輸入數據,訓練大語言模型學習使用者的興趣和偏好。微調後的模型能夠自動理解使用者的文本描述,匹配最合適的商品進行推薦。對於使用者提出的新需求,還可以接入檢索系統即時搜尋相關商品,動態生成推薦列表。如此構建的電商平台推薦系統,能夠顯著提升使用者購物體驗和轉化率。
6.2 社交媒體推薦
社交媒體平台推薦使用者內容,往往需要考慮使用者的多樣性需求。傳統的協同過濾推薦系統難以捕捉使用者的多樣性需求,導致推薦結果單一。而基於大語言模型的推薦系統,可以透過與使用者進行多輪互動,獲取使用者的即時反饋,實作動態化的推薦。
在技術實作上,可以收集使用者的內容釋出、點贊、評論等行為數據,將其作為輸入數據,訓練大語言模型學習使用者的興趣和偏好。微調後的模型能夠自動理解使用者的即時需求,動態調整推薦結果,提升推薦效果。同時,可以透過與使用者進行多輪對話,獲取使用者的即時反饋,進一步最佳化推薦結果。如此構建的社交媒體推薦系統,能夠提升使用者滿意度,增強平台黏性。
6.3 內容平台推薦
內容平台推薦使用者感興趣的文章、視訊等,需要考慮使用者的多樣性和個人化需求。傳統的協同過濾推薦系統難以應對大規模數據集和即時數據流的挑戰,導致推薦效果不夠精準。而基於大語言模型的推薦系統,能夠處理大規模、高維度的數據,捕捉使用者的語意資訊,提升推薦的精準度和個人化程度。
在技術實作上,可以收集使用者的歷史閱讀記錄、點贊、評論等行為數據,將其作為輸入數據,訓練大語言模型學習使用者的興趣和偏好。微調後的模型能夠自動理解使用者的語意資訊,匹配最合適的文章、視訊進行推薦。同時,可以透過與使用者進行多輪對話,獲取使用者的即時反饋,動態調整推薦結果。如此構建的內容平台推薦系統,能夠提升使用者滿意度,增強平台黏性。
6.4 未來套用展望
隨著大語言模型和推薦系統的不斷發展,基於大語言模型的推薦技術將在更多領域得到套用,為內容創作者、商家等帶來新的機遇。
在智慧城市治理中,推薦系統可以推薦與市民息息相關的政策、服務、事件等,提升城市治理的透明度和效率。
在公共健康領域,推薦系統可以推薦相關的科普知識、醫療資訊、健康提示等,幫助市民提升健康素養。
在教育培訓領域,推薦系統可以推薦相關的學習資源、課程、習題等,幫助學生個人化學習,提升學習效果。
此外,在新聞媒體、娛樂、旅遊等領域,基於大語言模型的推薦系統也將不斷湧現,為各行業帶來新的發展機遇。相信隨著技術的日益成熟,大語言模型推薦系統必將在更多領域大放異彩,提升人類的生產生活方式。
7. 工具和資源推薦
7.1 學習資源推薦
為了幫助開發者系統掌握大語言模型在推薦系統中的套用理論基礎和實踐技巧,這裏推薦一些優質的學習資源:
- 【Transformers從原理到實踐】系列博文:由大模型技術專家撰寫,深入淺出地介紹了Transformer原理、BERT模型、推薦系統範式等前沿話題。
- CS224N【深度學習自然語言處理】課程:史丹佛大學開設的NLP明星課程,有Lecture視訊和配套作業,帶你入門NLP領域的基本概念和經典模型。
- 【Natural Language Processing with Transformers】書籍:Transformers庫的作者所著,全面介紹了如何使用Transformers庫進行NLP任務開發,包括推薦系統在內的諸多範式。
- HuggingFace官方文件:Transformers庫的官方文件,提供了海量預訓練模型和完整的推薦系統樣例程式碼,是上手實踐的必備資料。
- RECOMEND開源計畫:推薦系統開源計畫,涵蓋大量不同型別的推薦系統數據集,並提供了基於微調的baseline模型,助力推薦系統技術發展。
透過對這些資源的學習實踐,相信你一定能夠快速掌握大語言模型在推薦系統中的套用精髓,並用於解決實際的推薦問題。
7.2 開發工具推薦
高效的開發離不開優秀的工具支持。以下是幾款用於大語言模型推薦系統開發的常用工具:
- PyTorch:基於Python的開源深度學習框架,靈活動態的計算圖,適合快速叠代研究。大部份預訓練語言模型都有PyTorch版本的實作。
- TensorFlow:由Google主導開發的開源深度學習框架,生產部署方便,適合大規模工程套用。同樣有豐富的預訓練語言模型資源。
- Transformers庫:HuggingFace開發的NLP工具庫,整合了眾多SOTA語言模型,支持PyTorch和TensorFlow,是進行推薦系統開發的利器。
- Weights & Biases:模型訓練的實驗跟蹤工具,可以記錄和視覺化模型訓練過程中的各項指標,方便對比和調優。與主流深度學習框架無縫整合。
- TensorBoard:TensorFlow配套的視覺化工具,可即時監測模型訓練狀態,並提供豐富的圖表呈現方式,是偵錯模型的得力助手。
- Google Colab:谷歌推出的線上Jupyter Notebook環境,免費提供GPU/TPU算力,方便開發者快速上手實驗最新模型,分享學習筆記。
合理利用這些工具,可以顯著提升大語言模型推薦系統的開發效率,加快創新叠代的步伐。
7.3 相關論文推薦
大語言模型和推薦系統的發展源於學界的持續研究。以下是幾篇奠基性的相關論文,推薦閱讀:
- Attention is All You Need(即Transformer原論文):提出了Transformer結構,開啟了NLP領域的預訓練大模型時代。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding:提出BERT模型,引入基於掩碼的自監督預訓練任務,重新整理了多項NLP任務SOTA。
- Language Models are Unsupervised Multitask Learners(GPT-2論文):展示了大規模語言模型的強大zero-shot學習能力,引發了對於通用人工智慧的新一輪思考。
- Parameter-Efficient Transfer Learning for NLP:提出Adapter等參數高效微調方法,在不增加模型參數量的情況下,也能取得不錯的微調效果。
- AdaLoRA: Adaptive Low-Rank Adaptation for Parameter-Efficient Fine-Tuning:使用自適應低秩適應的微調方法,在參數效率和精度之間取得了新的平衡。
- RAKER: Towards BERT-based Recommendation with Adaptive Low-rank Key Encoder-Decoder Architectures:提出了基於BERT的推薦系統,實作了與使用者多輪對話互動,提升了推薦效果。
這些論文代表了大語言模型推薦系統的發展脈絡。透過學習這些前沿成果,可以幫助研究者把握學科前進方向,激發更多的創新靈感。
8. 總結:未來發展趨勢與挑戰
8.1 總結
本文對基於大語言模型的推薦系統進行了全面系統的介紹。首先闡述了大語言模型和推薦系統的發展背景和意義,明確了大語言模型在推薦系統中的套用價值。其次,從原理到實踐,詳細講解了大語言模型在推薦系統中的數學模型和關鍵步驟,給出了推薦系統開發的完整程式碼例項。同時,本文還廣泛探討了大語言模型在電商、社交、內容等多個領域的推薦套用前景,展示了其廣泛的套用潛力。此外,本文精選了推薦系統的各類學習資源,力求為讀者提供全方位的技術指引。
透過本文的系統梳理,可以看到,基於大語言模型的推薦系統正在成為推薦系統的重要範式,極大地拓展了推薦系統的套用邊界,推動了推薦技術的產業化行程。未來,伴隨預訓練語言模型和推薦系統的持續演進,相信推薦系統將在更多領域得到套用,為各行業帶來新的發展機遇。
8.2 未來發展趨勢
展望未來,大語言模型在推薦系統中的套用將呈現以下幾個發展趨勢:
- 多模態融合 :推薦系統中的資料來源從單一的文本數據擴充套件到影像、視訊、音訊等多種模態,多模態資訊的融合將顯著提升推薦效果。
- 動態推薦 :結合使用者的即時反饋,實作動態化的推薦,提升推薦的時效性和精準度。
- 個人化推薦 :基於使用者的個人化需求,提供更加精準、個人化的推薦,提升使用者滿意度。
- 跨領域推薦 :利用大語言模型在多個領域預訓練得到的語言表征,實作跨領域的推薦,拓展推薦系統的套用場景。
- 即時推薦 :結合與使用者的即時互動,實作即時推薦,提升推薦效果。
- 安全性和私密保護 :采用差分私密、聯邦學習等技術,保護使用者私密和數據安全。
- 大模型微調 :透過微調大模型,適應使用者興趣和行為的變化,實作動態化的推薦。
以上趨勢凸顯了大語言模型在推薦系統中的套用前景。這些方向的探索發展,必將進一步提升推薦系統的效能和套用範圍,為推薦技術的產業化行程提供新的動力。
8.3 面臨的挑戰
盡管大語言模型在推薦系統中的套用取得了顯著成果,但在邁向更加智慧化、普適化套用的過程中,仍面臨諸多挑戰:
- 數據稀疏 :推薦數據與預訓練數據的分布差異較大時,推薦效果可能有限,使用者行為數據的缺失可能影響模型的泛化能力。
- 模型復雜度 :大語言模型參數量龐大,對計算資源和儲存資源的要求較高,可能面臨資源瓶頸。
- 可解釋性不足 :大語言模型推薦結果的可解釋性不足,難以解釋模型的決策過程,對高風險套用尤其重要。
- 偏見和歧視 :大語言模型可能學習到有偏見、有害的資訊,透過推薦系統傳遞到使用者,產生誤導性、歧視性的輸出,給實際套用帶來安全隱患。
- 冷啟動問題 :對於新使用者或新物品,推薦系統可能面臨冷啟動問題,難以給出合適的推薦。
- 動態變化 :使用者的興趣和行為隨時間變化,推薦系統需要即時更新模型參數,以保持推薦結果的精準度。
盡管存在這些挑戰,但就目前而言,基於大語言模型的推薦系統方法仍然是大規模推薦系統的重要範式。未來相關研究的重點在於如何進一步降低對標註數據的依賴,提高模型的少樣本學習和跨領域遷移能力,同時兼顧可解釋性和倫理安全性等因素。
8.4 研究展望
面對大語言模型推薦系統所面臨的種種挑戰,未來的研究需要在以下幾個方面尋求新的突破:
- 無監督和半監督學習 :探索無監督和半監督推薦方法,擺脫對大規模標註數據的依賴,利用非結構化數據,實作更加靈活高效的推薦。
- 參數高效微調 :開發更加參數高效的微調方法,在固定大部份預訓練參數的同時,只更新極少量的任務相關參數。
- 多模態融合 :利用多模態融合技術,整合影像、視訊、音訊等多種資料來源,實作更為全面的使用者畫像,提升推薦效果。
- 互動式推薦 :結合與使用者的即時互動,實作動態化的推薦,提升推薦的時效性和精準度。
- 因果推理 :引入因果推理方法,增強推薦系統的穩定性和魯棒性。
- 安全性和私密保護 :采用差分私密、聯邦學習等技術,保護使用者私密和數據安全。
- 知識表示和推理 :結合知識表示和推理技術,提升推薦系統的智慧化水平。
這些研究方向的探索,必將引領大語言模型推薦系統技術邁向更高的台階,為推薦技術的產業化行程提供新的動力。相信隨著學界和產業界的共同努力,這些挑戰終將一一被克服,大語言模型推薦系統必將在更多領域大放異彩,推動推薦技術的全面發展。
9. 附錄:常見問題與解答
Q1:大語言模型推薦系統是否適用於所有推薦任務?
A: 大語言模型推薦系統在大多數推薦任務上都能取得不錯的效果,特別是對於數據量較小的任務。但對於一些特定領域的任務,如醫學、法律等,僅僅依靠通用語料預訓練的模型可能難以很好地適應。此時需要在特定領域語料上進一步預訓練,再進行微調,才能獲得理想效果。此外,對於一些需要時效性、個人化很強的任務,如對話、推薦等,微調方法也需要針對性的改進最佳化。
Q2:如何選擇合適的學習率?
A: 大語言模型推薦系統的學習率一般要比預訓練時小1-2個數量級,如果使用過大的學習率,容易破壞預訓練權重,導致過擬合。一般建議從1e-5開始調參,逐步減小學習率,直至收斂。也可以使用warmup策略,在開始階段使用較小的學習率,再逐漸過渡到預設值。需要註意的是,不同的最佳化器(如Adam、Adagrad等)以及不同的學習率排程策略,可能需要設定不同的學習率閾值。
Q3:在稀疏數據環境下,推薦效果可能受到影響,如何解決?
A: 在稀疏數據環境下,推薦效果可能受到影響,使用者行為數據的缺失可能影響模型的泛化能力。可以透過以下方法緩解:
- 數據增強:透過回譯、近義替換等方式擴充訓練集。
- 模型結構最佳化:采用稀疏矩陣表示使用者行為數據,減小模型復雜度。
- 特征工程:引入更多的特征,如時間戳、位置資訊等,提升模型泛化能力。
- 模型融合:結合多個推薦模型,提升推薦效果。
這些方法往往需要根據具體任務和數據特點進行靈活組合。只有在數據、模型、訓練、推理等各環節進行全面最佳化,才能最大限度地發揮大語言模型推薦系統的潛力。
Q4:如何提高大語言模型推薦系統的可解釋性?
A: 大語言模型推薦系統的可解釋性不足,難以解釋模型的決策過程。可以透過以下方法提高可解釋性:
- 模型壓縮:采用模型壓縮技術,減小模型復雜度,提高可解釋性。
- 視覺化分析:利用視覺化工具,展示模型的關鍵特征和決策路徑。
- 特征重要性分析:分析模型的特征重要性,解釋推薦結果的依據。
- 使用者反饋:收集使用者的反饋意見,指導模型的最佳化和改進。
這些方法可以幫助開發者更好地理解大語言模型推薦系統的決策過程,提升系統的可信度和可用性。
Q5:如何保護使用者私密和數據安全?
A: 大語言模型推薦系統中的使用者私密和數據安全至關重要。可以透過以下方法保護使用者私密和數據安全:
- 差分私密:采用差分私密技術,保護使用者數據的私密性。
- 聯邦學習:在分布式環境中,透過聯邦學習技術,保護使用者數據不被集中儲存。
- 數據加密:采用數據加密技術,保護使用者數據的傳輸安全。
- 存取控制:對推薦系統進行存取控制,限制使用者數據的存取許可權。
這些方法可以有效地保護使用者私密和數據安全,確保推薦系統在實際套用中的可信度。
作者:禪與電腦程式設計藝術 / Zen and the Art of Computer Programming











