編輯:桃子
【新智元導讀】 清華團隊竟把醫院搬進了AI世界!第一個AI醫院小鎮——Agent Hospital,可以完全模擬醫患看病的全流程。更重要的是,AI醫生可以自主前進演化,僅用幾天的時間治療大約1萬名患者。
史丹佛AI小鎮曾火遍了全網,25個智慧體生活交友,堪稱現實版的「西部世界」。
而現在,AI「醫院小鎮」也來了!
最近,來自清華團隊的研究人員開發了一個名為「Agent Hospital」的模擬醫院。

論文地址:https://arxiv.org/pdf/2405.02957
在這個虛擬世界中,所有的醫生、護士、患者都是由LLM驅動的智慧體,可以自主互動。
它們模擬了整個診病看病的過程,包括分診、掛號、咨詢、檢查、診斷、治療、隨訪等環節。
而在這項研究中,作者的核心目標是,讓AI醫生學會在模擬環境中治療疾病,並且能夠實作自主前進演化。
由此,他們開發了一種MedAgent-Zero系統,能夠讓醫生智慧體,不斷從成功和失敗的病例積累經驗。
值得一提的是,AI醫生可以在幾天內完成對1萬名患者的治療。
而人類醫生需要2年的時間,才能達到類似的水平。

另外,前進演化後的醫生智慧體,在涵蓋主要呼吸道疾病的MedQA數據集子集上,實作高達93.06%的最新準確率。
不得不說,AI前進演化在虛擬世界中默默前進演化,真有淘汰人類之勢。
有網友表示,「AI模擬將探索人類根本沒有時間,或能力探索的道路」。

想象一下,數千家全自動化醫院,將會拯救數百萬人的生命。這很快就會到來。

第一個AI醫院小鎮登場
其實,智慧體,早已成為業界看好的一個領域。
不論是在虛擬世界中的模擬,還是能夠解決實際任務(比如Devin)的智慧體,都將給我們世界帶來巨變。
然而,這些多智慧體通常用於「社會模擬」,或者「解決問題」。
那麽,是否有將這兩種能力結合起來的智慧體?
也就是說,社會模擬過程能否,提升LLM智慧體在特定任務的表現?
受此啟發,研究人員開發了一個幾乎涵蓋所有醫學領域的治療流程的模擬。


如同 單機遊戲 【主題醫院】的世界
Agent Hospital中模擬的環境,主要有兩類主體:一是患者,一是醫療專業人員。
它們的角色資訊,都是由GPT-3.5生成,可以無限擴充套件。
比如,下圖中,35歲患者Kenneth Morgan有急性鼻炎,而他的病史是高血壓,目前的癥狀是持續嘔吐,有些腹瀉、反復發燒、腹痛、頭痛,而且頸淋巴結腫大。
再來看32歲內科醫生Elise Martin,具備了出色的溝通能力,以及富有同理心的護理能力。
她主要的職責是,為患有各種急性病和慢性病的成年患者提供診斷、治療和預防保健服務。
ZhaoLei是一位擅長解讀醫學影像的放射科醫生,還有前台接待員Fatoumata Diawara。

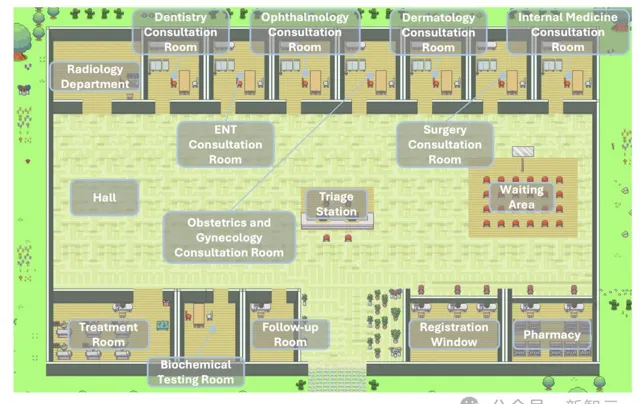
下圖中展示的是,Agent Hospital內有各種問診室和檢查室,因此需要一系列醫療專業智慧體工作。
研究人員設計了,14名醫生和4名護士。
醫生智慧體被設計來診斷疾病並制定詳細的治療計劃,而護理智慧體則專註於分診,支持日常治療幹預。
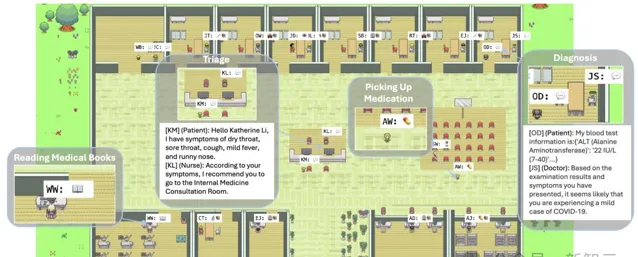
AI患者如何看病?
與真實世界看病的流程一樣,當患者生病後,就會去醫院掛號就診。
在此期間,它們還會經歷一系列階段,包括檢查、分診、會診、診斷、治療。
患者在拿到治療方案後,LLM會幫助預測患者的健康狀況變化。一旦康復,它便會主動向醫院匯報進行隨訪。
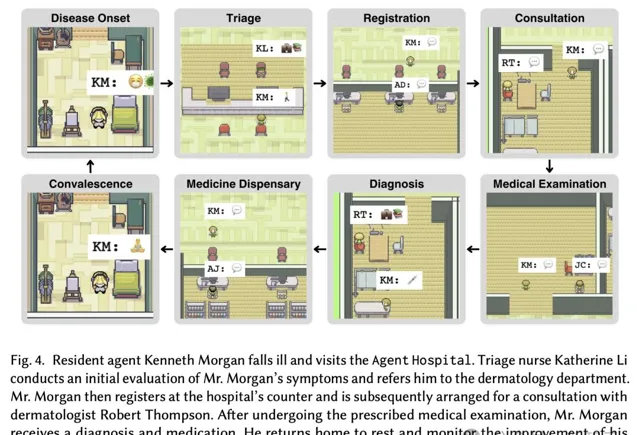
如下是Kenneth Morgan前往醫院就診的示意圖。
首先是,分診護士Katherine Li對Morgan進行了初步的評估,並將他分診到皮膚科就診。
隨後,Morgan在醫院櫃台進行登記,被安排與皮膚科醫生Robert Thompson進行會診。
在完成規定的體檢之後,AI醫生為Morgan開出藥物治療,並敦促回家休息,同時還要監測病情的改善情況。
AI醫生自我超前進演化,無需手動標記數據
在模擬環境中,研究人員希望訓練一個熟練的醫生智慧體,來處理諸如診斷、治療等醫療任務。
傳統的方法是,將巨量的醫學數據餵給LLM/智慧體,經過預訓練、微調、RAG之後,以構建強大的醫學模型。
最新研究中,作者提出了一種新策略——在虛擬環境中模擬醫患互動,來訓練醫生智慧體。
在這個過程中,研究人員沒有使用手動標記數據,因此最新系統被命名為MedAgent-Zero。
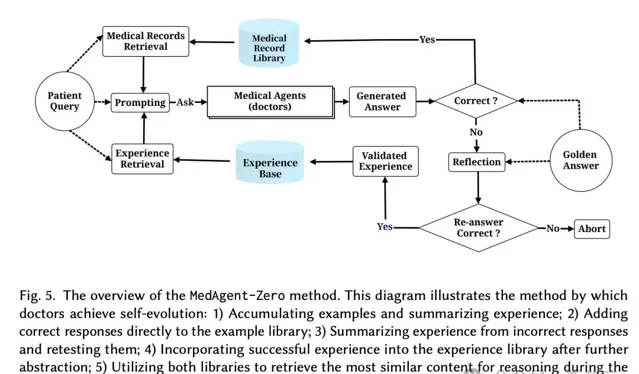
這一策略包含了兩個重要的模組,即「病歷庫」和「經驗庫」。
診療成功的案例被整理,並儲存在病歷庫中,作為今後醫療幹預的參考。
而對於治療失敗的情況,AI醫生有責任反思、分析診斷不正確的原因,總結出指導原則,作為後續治療過程中的警示。
簡言之,MedAgent-Zero可以讓生智慧體透過與患者智慧體互動。
透過積累成功案例的記錄,和從失敗案例中獲得經驗,前進演化成更優秀的「醫生」。
整個自我前進演化流程如下:
1)積累例項,總結經驗;
2)直接向範例庫添加正確的響應;
3)總結錯誤的經驗,並重新測試;
4)將成功經驗進一步抽象後,納入經驗庫;
5)在推理過程中利用兩個庫檢索最相似的內容進行推理。
難得的是,由於訓練成本低,效率高,醫生智慧體可以輕松應對數十種情況。
比如,智慧體可以在短短幾天內處理數萬個病例,而現實世界的醫生需要幾年的時間才能完成。
診斷呼吸疾病,準確率高達93.06%
接下來,研究人員進行了兩類實驗,來驗證MedAgent-Zero策略改進的醫生智慧體,在醫院中的有效性。
一方面,在虛擬醫院內,作者們進行了從100-10000個智慧體的互動實驗(人類醫生一周可能會治療約100名病人),涵蓋了8種不同的呼吸疾病、十幾種醫療檢查,以及每種疾病的三種不同治療方案。
透過MedAgent-Zero策略訓練的醫生智慧體,在處理模擬病人的過程中不斷自我前進演化,最終在檢查、診斷和治療任務中的準確率分別達到了88%、95.6%和77.6%。
隨著樣本的不斷擴增,MedAgent-Zero的訓練效能,在達到一定量時趨於平穩。
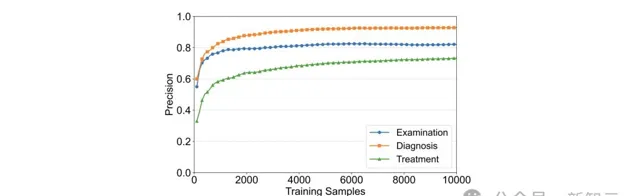
在檢查、診斷、治療三個任務方面上的效能,MedAgent-Zero也隨著樣本增加,不斷波動,但整體準確性呈現出上升趨勢。
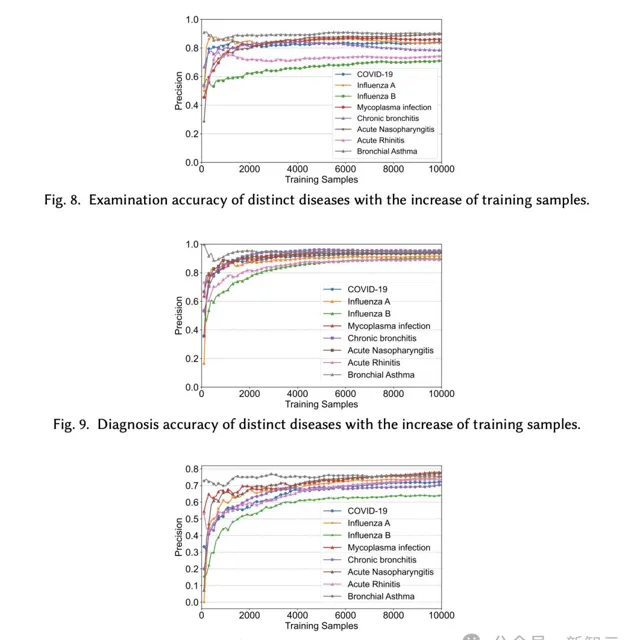
診斷呼吸疾病,準確率高達93.06%
再看如下三張圖,分別展示了不同疾病的檢查精度、診斷精確度、以及治療精度,隨著樣本的增加,也在平穩攀升。
另一方面,研究者讓前進演化後的醫生智慧體,參加了對MedQA數據集子集的評估。
令人驚訝的是,即使沒有任何手動標註的數據,醫生智慧體在Agent Hospital中前進演化後,也實作了最先進的效能。
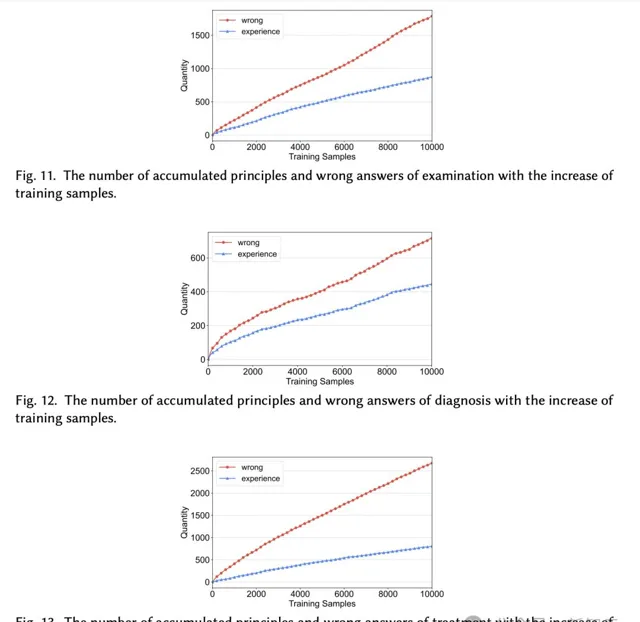
在經驗積累上,圖11、圖12和圖13分別顯示了,檢查、診斷和治療任務中,經過驗證經驗和錯誤答案的積累。
當訓練樣本增延長,經驗數和錯誤答案數都緩慢增加。
如圖所示,經驗曲線低於錯誤答案曲線,原因是智慧體無法反映所有失敗的經驗。此外,診斷經驗比其他任務更容易積累。
一起來看個案例研究。
下表中說明了,經驗庫、病理庫和MedAgent-Zero,在患者診療中的三個任務上的效能。
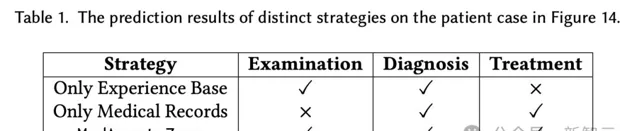
在得知病人癥狀之後,AI醫生不僅需要使用病歷庫,同時還需要經驗庫,也就是相輔相成。
若是少了其中的一方,便會導致診斷準確性的下降。
如下,透過添加經驗和記錄,MedAgent-Zero針對所有3個任務都給出了正確的回答。

以上結果表明,模擬環境可以有效地幫助LLM智慧體在處理特定任務時完成前進演化。
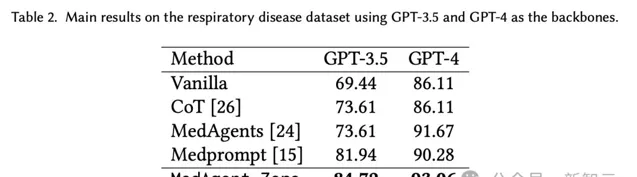
MedAgent-Zero在使用GPT-3.5時,比SOTA方法Medprompt高出 2.78%,在使用GPT-4時比SOTA方法MedAgents高出1.39%。
這一結果驗證了新模型有助於,在沒有任何MedQA訓練樣本的情況下,僅使用模擬文件和醫療文件進行智慧體前進演化,從而有效提高醫生智慧體的醫療能力。
其次,基於GPT-4的MedAgent-Zero的最佳效能為93.06%,優於MedQA數據集中的人類專家(約87%)。
第三,基於GPT-4的醫生智慧體比基於GPT-3.5的任何其他方法都表現得更出色,這表明GPT-4在醫療領域更強大。
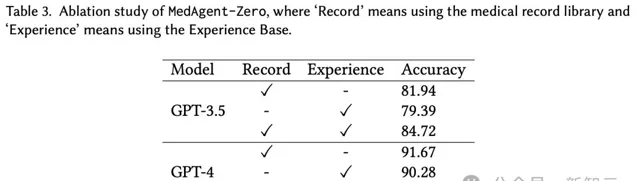
另外,在對MedAgent-Zero進行的消融研究中,
同時利用「病歷庫」和「經驗庫」的MedAgent-Zero取得了最佳效能,表明這兩個模組對診斷的幫助。
隨著病例的積累和經驗庫的擴大,醫生智慧體準確率總體上越來越高。
無論是使用GPT-3.5還是 GPT-4,使用8000個病例積累的經驗庫,其效能都高於使用2000/4000/6000個病例的效能。
不過,經驗庫越大並不總是越好,因為研究者還發現在2,000-4,000個案例之間有明顯的下降。

局限性
最後,研究人員還提到了這項研究的局限性。
- 只采用GPT-3.5作為Agent Hospital和評估的模擬器
- 由於智慧體之間的互動及其演化涉及API呼叫,AI醫院的運作效率受到LLM生成的限制
- 每個患者的健康記錄和檢查結果,是在沒有領域知識的情況下,模擬真實的電子健康記錄生成的,但仍與現實世界的記錄仍存在一些差異。
在未來,研究者們對Agent Hospital的計劃將會包括:
第一,擴大規模覆蓋的疾病範圍,延伸到更多的醫療科室,旨在反映真實醫院提供的全面服務,以供進一步研究。
第二,在加強智慧體社會模擬方面,比如納入醫療專業人員的全面晉升制度、隨時間改變疾病的分布、納入病人的歷史病歷等。
第三,最佳化基礎LLM的選擇和實施,旨在透過利用功能強大的開源模型,更高效地執行整個模擬過程。











