
編輯 | ScienceAI
現代醫療保健系統會產生大量高維臨床數據 (HDCD),例如肺功能圖、光體積變化描記圖法 (PPG)、心電圖 (ECG) 記錄、CT 掃描和 MRI 成像,這些數據無法用單個二進制或連續數位來概括。
了解我們的基因組與 HDCD 之間的聯系不僅可以提高我們對疾病的了解,而且對於疾病治療的發展也至關重要。
近日,Google Research 的基因組學團隊在利用 HDCD 表征疾病和生物學特征方面取得了進展。
研究團隊提出了一種無監督深度學習模型,即低維嵌入基因發現的表示學習 (REGLE),用於發現基因變異與 HDCD 之間的關聯。
REGLE 作為一種新穎的基因發現方法,可以利用高維臨床數據中的隱藏資訊,其計算效率高,不需要疾病標簽,並且可以整合來自專家定義知識的資訊。
總體而言,REGLE 包含的臨床相關資訊超出了現有專家定義的特征所捕獲的資訊,從而可以改善基因發現和疾病預測。
相關研究以「 Unsupervised representation learning on high-dimensional clinical data improves genomic discovery and prediction 」為題,於 7 月 8 日釋出在【 Nature Genetics 】上。

論文連線: https://www.nature.com/articles/s41588-024-01831-6
揭示 HDCD 中的隱藏資訊
研究基因與 HDCD 之間聯系的一種簡單方法是對每個數據座標執行 GWAS,例如,可以研究醫學影像中每個像素值的變化。這種方法計算成本高,並且由於鄰近座標之間的高相關性和大量的多重測試負擔,發現顯著關聯的能力較低。
一種更常用的方法是專註於從 HDCD 中提取的少量專家定義特征 (Expert-defined Features,EDF) 作為 GWAS 的目標特征或表型。EDF 可以包括臨床已知的特征,例如肺量圖的用力肺活量 (FVC) 或 1 秒用力呼氣量 (FEV1)。
雖然這些 EDF 是專家發現的重要特征,但假設它們可能無法全面捕獲 HDCD 中編碼的訊號,因此對這些訊號執行 GWAS 可能無法充分利用 HDCD 的潛力。
REGLE 旨在使用變分自動編碼器 (VAE) 模型克服這些限制。該方法包括三個主要步驟:
(1) 透過 VAE 學習 HDCD 的非線性、低維、解纏結表示(即編碼或嵌入);
(2) 對每個編碼座標獨立進行 GWAS;
(3) 使用來自編碼座標的多基因風險評分 (PRS) 作為一般生物功能的遺傳評分,然後可能將這些評分組合起來為特定疾病或特征建立 PRS(給定少量疾病標簽)。
值得註意的是,REGLE 還允許在修改後的 VAE 架構中將相關 EDF 選擇性地包含在解碼器的輸入中,從而鼓勵編碼器僅學習 EDF 未表示的殘留誤差訊號。
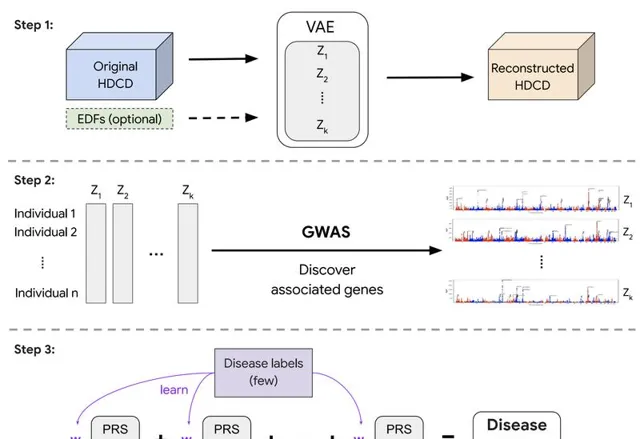
圖示:REGLE 的三個步驟。(來源:論文)
檢測肺和迴圈功能的新基因位點
研究人員使用兩種高維臨床數據模式展示了 REGLE 的功能:測量肺功能的肺量圖和測量心血管功能的 PPG。兩者都可以在診所或消費者可穿戴裝置中以非侵入性、相對便宜的方式收集,並且這兩種模式都有眾所周知的特征)。
與具有相同維度的肺量圖和 PPG 特征的全基因組關聯研究相比,REGLE 對學習編碼的研究恢復了與肺和迴圈功能相關的大多數已知基因位點(loci),同時還檢測到了其他位點(例如,PPG 的重要位點增加了 45%)。如果這些位點在進一步的分析和濕實驗室實驗中得到驗證,它們有可能成為新的藥物靶點。
改進的遺傳風險評分
多基因風險評分 (PRS) 是許多遺傳變異對特定特征的估計影響的總結,以單個數位表示。透過對 REGLE 嵌入進行全基因組關聯研究建立的 PRS 可以僅使用少量疾病標簽進行組合,以生成針對該特定疾病的 PRS。
研究人員觀察到,與現有方法(例如由專家定義的特征、PCA 和 PRS)相比,由肺量圖編碼建立的肺功能 PRS 改善了 COPD 和哮喘預測,並且比風險譜兩端的特征 PRS 更有效地對風險組進行分層。哮喘和 COPD 的多個獨立數據集(COPDGene、eMERGE III、Indiana Biobank 和 EPIC-Norfolk)中的多個指標(AUC-ROC、AUC-PR 和 Pearson 相關性)在統計學上顯著改善,如下所示。
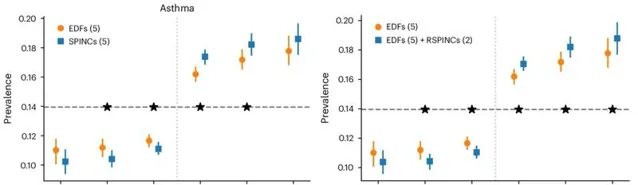
圖示:肺量圖編碼 (SPINC) 和殘留誤差肺量圖編碼 (RSPINC) PRS 與專家定義的特征 PRS 對哮喘患病率的比較。(來源:論文)
類似地,從 PPG 的 REGLE 嵌入中得到的 PRS 可以改善高血壓和收縮壓 (SBP) 預測。在三個獨立數據集(COPDGene、eMERGE III 和 EPIC-Norfolk)以及英國生物庫的保留測試集中評估了由 PPG 編碼和 PPG 特征生成的高血壓和 SBP PRS。
觀察到,在多個數據集中,使用來自 PPG 編碼的 PRS 比使用來自專家定義特征的 PRS 具有一致的改進趨勢,無論是高血壓還是 SBP。
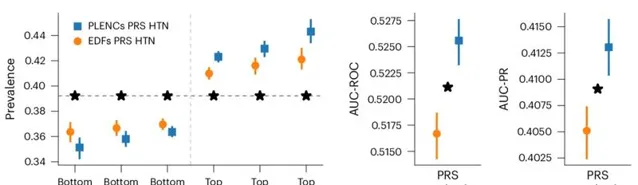
圖示:高血壓 (HTN) 的 PPG 編碼 (PLENC) PRS 比較。(來源:論文)
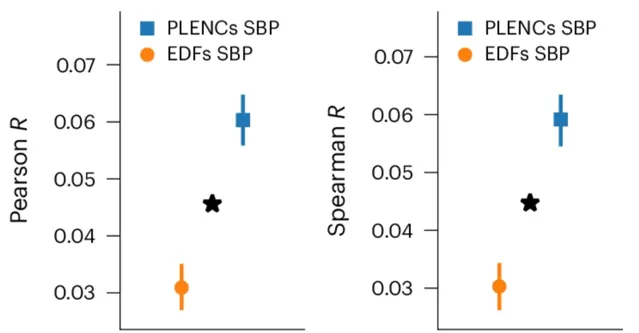
圖示:收縮壓 (SBP) 的 PPG 編碼 (PLENC) PRS 比較。(來源:論文)
部份可解釋的嵌入
利用 REGLE 的生成特性,透過固定專家定義特征的值並改變一個編碼座標而將其他編碼座標保持為零來研究編碼座標對肺量圖形狀的影響。然後,僅使用訓練模型的解碼器部份生成相應的肺量圖。
典型的流量-體積肺量圖由兩個不同的部份組成:(1)相對較短的部份以達到峰值流量,其中流量隨著體積的增加而單調增加;(2)肺量圖的主要部份,其中流量單調減少。
下圖顯示,改變第一個座標相當於擴大或縮小第二部份(負斜率),同時保持第一部份相對固定。事實上,曲線第二部份的凹度被肺病學家稱為凹陷,這是氣道阻塞的指標,標準 EDF 無法很好地表示出來。
圖示:改變一個呼吸圖編碼座標的效果。(來源:Google Research)
闡明人類特征和疾病的遺傳基礎
REGLE 是一種無監督學習方法,可執行遺傳分析、改進的新基因位點發現和風險預測。由於難以大規模手動發現 EDF,因此無監督學習 HDCD 表示對基因組發現很有吸重力。
REGLE 框架還透過修改傳統的 VAE 架構來支持在建模中原則性地使用這些特征。在兩種臨床數據模式(肺量圖和 PPG)中展示了 REGLE,它們可以在臨床環境中進行常規測量,也可以透過智慧型手機或可穿戴裝置被動和非侵入性地測量。
REGLE 提供了一種在沒有標記數據的情況下辨識遺傳對器官功能影響的機制,並允許將專家特征納入模型。它還提供了一種使用很少的標簽建立疾病和特征特異性 PRS 的方法。未來,這種類似的方法將越來越多地用於進一步闡明人類特征和疾病的遺傳基礎。
參考內容: https://research.google/blog/harnessing-hidden-genetic-information-in-clinical-data-with-regle/











