
大型语言模型的成功主要归功于Transformer架构的引入,Transformer通过自注意力机制和交叉注意力机制,能够有效地处理长距离依赖关系,使得模型在理解和生成语言方面表现出色。这些技术进步使得LLMs在各种应用中得到了广泛应用,包括自动翻译、文本生成、对话系统等。
尽管LLMs展示了强大的语言处理能力,它们在信息处理方式上与人类存在根本差异。人类的认知不仅依赖于语言,还包括体验、情感和社会互动等多方面的因素。因此,理解这些差异对于进一步发展更智能、更人性化的AI系统至关重要。
为了更好地理解人工智能系统,特别是大型语言模型的认知能力,Giuseppe Riva等专家提出了一个名为「Psychomatics」的多学科框架。该框架结合了认知科学、语言学和计算机科学,旨在深入探讨LLMs的高层次功能,特别是它们如何获取、学习、记忆和使用信息来生成输出。
Psychomatics框架的提出是为了弥补现有研究的不足。传统的AI行为科学(AIBS)主要关注AI系统的可观察行为及其环境决定因素,而忽略了AI系统内部的认知过程。通过比较LLMs和生物系统,Psychomatics框架希望揭示两者在语言发展和使用过程中的异同,从而为开发更健壮和类人化的AI系统提供理论指导。
Psychomatics是一个多学科交叉的研究框架,结合了心理学(Psychology)和信息学(Informatics),旨在理解人工智能系统的认知能力。该框架通过比较LLMs和人类认知过程,探讨语言、认知和智能的本质。Psychomatics不仅关注LLMs的外部行为,还深入研究其内部信息处理机制,试图揭示LLMs如何感知、学习、记忆和使用信息。
Psychomatics框架的重要性在于它为理解和改进AI系统提供了新的视角。通过结合认知科学、语言学和计算机科学,Psychomatics能够提供更全面的理论基础,帮助研究人员开发更智能、更人性化的AI系统。此外该框架还可以为AI系统的伦理和社会影响研究提供重要参考。
Psychomatics框架的研究团队由来自多个领域的专家组成,他们在认知科学、心理学、虚拟现实和传播科学等方面具有丰富的研究经验。Giuseppe Riva隶属于意大利米兰圣心天主教大学的Humane Technology Lab和意大利米兰意大利辅助医学研究所的神经心理学实验室应用技术;Fabrizia Mantovani隶属于意大利米兰比可卡大学「Riccardo Massa」人类科学教育系的「Luigi Anolli」传播科学研究中心(CESCOM);Brenda K. Wiederhold, Ph.D.隶属于美国加利福尼亚州拉霍亚的虚拟现实医疗中心和美国加利福尼亚州圣地亚哥的互动媒体学院;Antonella Marchetti隶属于意大利米兰圣心天主教大学心理学系和意大利米兰圣心天主教大学的Theory of Mind研究单位;Andrea Gaggioli:隶属于意大利米兰圣心天主教大学的人文技术实验室和意大利辅助医学研究所的神经心理学实验室应用技术、意大利米兰圣心天主教大学的传播心理学研究中心(PSICOM)。这个团队结合了认知科学、心理学、虚拟现实和传播科学等多个领域的专家,共同研究和理解人工智能系统的认知能力。他们的多学科背景为Psychomatics框架的提出和发展提供了坚实的理论和实践基础。
Psychomatics的定义与理论基础
1. Psychomatics的定义
Psychomatics是一个多学科交叉的研究框架,结合了心理学(Psychology)和信息学(Informatics),旨在深入理解人工智能系统,特别是大型语言模型(LLMs)的认知能力。该框架的核心理念是通过比较LLMs和人类认知过程,揭示两者在信息处理、语言习得和使用方面的异同。
心理学研究人类的认知、情感和行为,而信息学则关注信息的处理、存储和传输。将这两个领域结合起来,可以更全面地理解人工智能系统的工作原理。Psychomatics不仅关注LLMs的外部行为,还深入探讨其内部信息处理机制,试图揭示LLMs如何感知、学习、记忆和使用信息。
随着人工智能技术的快速发展,单一学科的研究方法已经无法满足对复杂AI系统的全面理解。多学科交叉研究成为必然趋势。Psychomatics框架通过结合认知科学、语言学和计算机科学,提供了一个更全面的理论基础,帮助研究人员开发更智能、更人性化的AI系统。
多学科交叉的必要性体现在全面性、创新性、实用性。
全面性:单一学科的研究往往局限于某一特定领域,而多学科交叉研究可以从多个角度全面理解AI系统。
创新性:不同学科的结合可以产生新的研究思路和方法,推动科学技术的创新发展。
实用性:多学科交叉研究可以更好地解决实际问题,提高AI系统的应用效果。
通过多学科交叉研究,Psychomatics框架不仅可以揭示LLMs的工作原理,还可以为开发更智能、更人性化的AI系统提供理论指导。
2. 理论驱动的研究问题
Psychomatics框架的一个核心研究问题是:人类和大型语言模型(LLMs)的语言发展和使用过程是否不同?这个问题作为比较研究的起点,帮助确定比较的内容、时间、方式及目的。
人类的语言发展是一个连续的过程,涉及社会、情感和语言互动。儿童通过与周围环境的互动,逐渐掌握语言的使用。而LLMs则是通过预定义的数据集进行训练,这种静态训练方法限制了它们通过个人经验和社会互动「成长」或「进化」的能力。
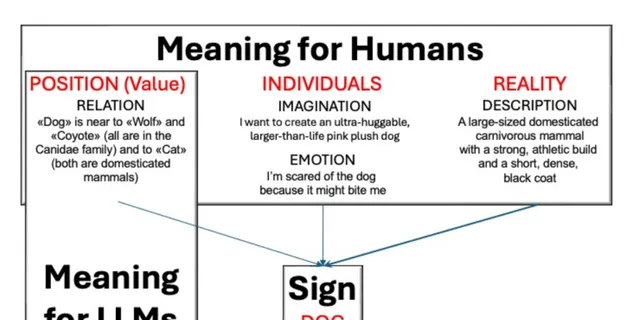
图1:人类和LLM的意义来源
通过比较人类和LLMs的语言发展和使用过程,Psychomatics框架希望揭示两者在信息处理、语言习得和使用方面的异同,从而为开发更智能、更人性化的AI系统提供理论指导。
为了实现上述研究目标,Psychomatics框架采用了一套系统的研究方法和策略:
- 理论驱动的研究问题:从理论出发,提出研究问题,并通过比较研究揭示LLMs和人类认知过程的异同。
- 系统性知识:发展超越简单描述的系统性知识,允许进行广泛的概括和外部验证。
- 理论指导:基于现有理论或合理假设,回答研究问题。
- 可靠的指标:使用可靠且可重复的指标,确保研究结果的内部有效性。
通过这些方法和策略,Psychomatics框架旨在建立一个严格的、理论驱动的比较框架,结合认知科学、语言学和计算机科学的优势,深入理解LLMs和人类认知过程的异同。
信息处理——句法与语义
1. 信息处理的基本概念
在信息处理领域,句法和语义是两个核心概念。句法(Syntax)指的是语言的结构和规则,决定了句子是否符合语法规范。具体来说,句法涉及词语的排列顺序、句子的构造方式以及词语之间的关系。句法规则确保了语言的连贯性和可理解性,使得信息能够被正确地传达和接收。
语义(Semantics)则关注语言的意义。它研究词语、短语和句子的含义,以及这些语言单位如何表示现实世界中的事物和概念。语义不仅涉及词语的字面意义,还包括隐含意义、上下文意义和情感意义。通过语义分析,我们可以理解语言背后的深层含义,进而更好地解读和生成语言。
在信息处理过程中,句法和语义共同作用,确保信息的准确传递和理解。句法提供了语言的结构框架,使得信息能够按照一定的规则进行组织和表达。而语义则赋予这些结构以具体的意义,使得信息不仅仅是符号的排列,而是具有实际意义的内容。

图2:意向性的层次结构
对于人工智能系统,特别是大型语言模型(LLMs)来说,句法和语义的处理尤为重要。LLMs通过学习大量的语言数据,掌握了复杂的句法规则和语义关系,从而能够生成连贯且有意义的文本。通过句法分析,LLMs可以识别句子的结构,确定词语之间的关系;通过语义分析,LLMs可以理解词语和句子的含义,生成符合上下文的响应。
2. 句法与语义的关系
句法和语义虽然密切相关,但它们在信息处理中的作用有所不同。句法主要关注语言的形式和结构,而语义则关注语言的内容和意义。句法规则决定了词语如何组合成句子,而语义则决定了这些句子所表达的具体含义。
例如,在句子「The cat chased the mouse」中,句法规则帮助我们识别「cat」是主语,「chased」是动词,「mouse」是宾语,从而确定句子的结构。而语义则帮助我们理解「cat」指的是一种动物,「chased」表示追逐的动作,「mouse」指的是另一种动物。通过句法和语义的结合,我们可以准确理解句子的含义。
为了更好地理解句法和语义在信息处理中的作用,我们可以通过一些具体的例子来说明。
- 句法分析:在自然语言处理中,句法分析(syntactic parsing)是一个重要的任务。通过句法分析,AI系统可以识别句子的结构,确定词语之间的关系。例如,在句子「John gave Mary a book」中,句法分析可以识别出「John」是主语,「gave」是动词,「Mary」是间接宾语,「a book」是直接宾语。这种结构信息对于理解句子的意义至关重要。
- 语义分析:语义分析(semantic parsing)则关注句子的意义。例如,在处理问答系统时,AI系统需要理解用户问题的语义,从而生成正确的答案。如果用户问「Who wrote ‘Pride and Prejudice’?」,AI系统需要理解「Pride and Prejudice」是一本书,「wrote」表示写作的动作,从而生成正确的答案「Jane Austen」。
- 句法与语义的结合:在实际应用中,句法和语义往往是结合在一起的。例如,在机器翻译中,AI系统需要同时考虑句法和语义,以生成准确且自然的翻译。句法分析帮助系统理解源语言的结构,而语义分析则确保翻译的内容准确传达源语言的意义。
通过这些例子,我们可以看到句法和语义在信息处理中的重要作用。对于大型语言模型(LLMs)来说,掌握复杂的句法规则和语义关系是生成连贯且有意义文本的关键。
Transformer算法与语言结构
1. Transformer算法的介绍
Transformer算法是近年来自然语言处理(NLP)领域的一项重大突破。由Vaswani等人在2017年提出的Transformer模型,通过引入自注意力机制(Self-Attention)和交叉注意力机制(Cross-Attention),解决了传统序列模型在处理长距离依赖关系时的局限性。
自注意力机制:自注意力机制允许模型在处理输入序列时,动态地关注序列中的不同部分。具体来说,自注意力机制通过计算每个词与序列中其他词的相关性(即注意力权重),来确定哪些词对当前词的意义最为重要。这种机制使得模型能够捕捉到长距离依赖关系,从而更好地理解上下文。
交叉注意力机制:交叉注意力机制主要用于序列到序列(Sequence-to-Sequence)模型,如机器翻译任务中。它通过计算输入序列和输出序列之间的相关性,来确定输入序列中哪些部分对生成输出序列最为重要。交叉注意力机制使得模型能够在生成输出时,动态地参考输入序列的不同部分,从而生成更准确和连贯的翻译。
Transformer模型中的自注意力机制和交叉注意力机制在一定程度上模拟了语言中的句法关系和联想关系。
句法关系:句法关系指的是词语在句子中的线性组合和语法规则。自注意力机制通过计算序列中每个词与其他词的相关性,捕捉到词语之间的依赖关系,从而模拟了句法关系。例如,在句子「The cat chased the mouse」中,自注意力机制可以识别出「cat」是主语,「chased」是动词,「mouse」是宾语,从而理解句子的结构。
联想关系:联想关系指的是词语之间的概念连接和认知联系。交叉注意力机制通过计算输入序列和输出序列之间的相关性,捕捉到词语之间的联想关系。例如,在机器翻译任务中,交叉注意力机制可以识别出源语言中的词语与目标语言中的词语之间的对应关系,从而生成准确的翻译。
2. Transformer在语言处理中的应用
Transformer模型在语言处理中的应用非常广泛,以下是一些具体的例子:
句法处理:在自然语言处理中,句法分析(syntactic parsing)是一个重要的任务。Transformer模型通过自注意力机制,可以有效地捕捉句子中的句法关系。例如,在句子「John gave Mary a book」中,自注意力机制可以识别出「John」是主语,「gave」是动词,「Mary」是间接宾语,「a book」是直接宾语,从而理解句子的结构。
联想处理:在机器翻译任务中,交叉注意力机制发挥了重要作用。例如,在将英语句子「The cat is on the mat」翻译成法语句子「Le chat est sur le tapis」时,交叉注意力机制可以识别出「cat」对应「chat」,「mat」对应「tapis」,从而生成准确的翻译。
Transformer模型中的自注意力机制和交叉注意力机制,通过捕捉句法关系和联想关系,帮助大型语言模型(LLMs)更好地理解和生成语言。
理解语言:自注意力机制使得LLMs能够在处理输入序列时,动态地关注序列中的不同部分,从而捕捉到长距离依赖关系。这种机制使得LLMs能够更好地理解上下文,从而生成连贯且有意义的响应。
生成语言:交叉注意力机制使得LLMs在生成输出序列时,能够动态地参考输入序列的不同部分,从而生成更准确和连贯的文本。例如,在机器翻译任务中,交叉注意力机制可以帮助LLMs生成符合目标语言语法和语义的翻译。
通过自注意力机制和交叉注意力机制,Transformer模型在语言处理中的表现得到了显著提升,使得LLMs在各种应用中展示了强大的语言生成和理解能力。
人类与LLMs的差异
1. 社会互动与个人经验的影响
自然智能,即人类智能,是通过多层次的社会互动和个人经验逐步涌现的。人类从出生开始,就通过与周围环境和他人的互动,逐渐发展出复杂的认知能力。这些互动不仅包括语言交流,还涉及情感交流、社会关系和文化传承。通过这些多层次的互动,人类能够理解和适应复杂的社会环境,形成丰富的认知和情感体验。
例如,儿童在学习语言的过程中,不仅仅是通过听和模仿成人的语言,还通过观察和参与社会活动,理解语言在不同情境中的使用方式。这种学习过程是动态的、连续的,伴随着个人经验的积累和社会关系的深化。
与人类智能的多层次涌现不同,大型语言模型(LLMs)的训练方法是静态的、预定义的。LLMs通过处理大量的文本数据进行训练,这些数据通常来自互联网、书籍、文章等。虽然这种方法使得LLMs能够掌握复杂的语言模式和语法规则,但它们缺乏人类在社会互动中获得的情感和经验。
LLMs的训练数据是固定的,无法通过个人经验和社会互动进行「成长」或「进化」。这种静态训练方法限制了LLMs在处理新情境和生成新意义方面的能力。例如,LLMs在面对未见过的语言模式或需要情感理解的任务时,可能会表现出局限性。
此外,LLMs的训练数据中可能包含偏见和错误信息,这些问题在训练过程中可能被放大,导致模型生成的文本中出现不准确或不适当的内容。因此,尽管LLMs在许多任务中表现出色,但它们在处理复杂的社会和情感任务时,仍然存在显著的局限性。
2. 语言与真理条件
人类语言的意义不仅仅来自于词语的字面含义,还包括情境、文化和个人经验等多种来源。语言的多源性使得人类能够在不同情境中灵活使用语言,传达复杂的思想和情感。例如,同一个词语在不同的文化背景下可能具有不同的含义,而同一句话在不同的情境中可能传达不同的情感。
这种多源性使得人类语言具有高度的灵活性和适应性,能够应对各种复杂的交流需求。然而,这也意味着语言的理解和使用需要考虑多种因素,而不仅仅是词语的字面含义。
LLMs在处理语言时,主要依赖于统计模式和概率计算。它们通过评估训练数据中各种场景的可能性,来预测最可能的答案。然而这种方法在处理真理条件与实际真理的差距时,存在一定的局限性。
例如,当被问及「猫在哪里?」时,LLMs可能会根据训练数据中的统计模式,回答「在地板上」,即使实际情况是「在垫子上」。这是因为LLMs优先选择在训练数据中出现频率最高的答案,而不是根据实际情况进行判断。
这种依赖概率的方法可能导致LLMs生成错误或不准确的信息,特别是在处理需要精确事实的任务时。为了减少这种问题,研究人员正在探索将外部知识源、反事实思维和增强检索技术等方法整合到LLMs中,以提高其处理真理条件的能力。
3. 主观和跨主观经验
人类的情感体验和主观意义是语言理解和使用的重要组成部分。情感体验(qualia)是指个人在经历某种情境时所产生的独特感受,这些感受具有主观性和个体差异。例如,「狗」这个词对于不同的人可能引发不同的情感反应,有些人可能感到害怕,而有些人则感到亲切。
这种情感体验和主观意义使得人类语言具有丰富的情感内涵,能够传达复杂的情感和态度。然而LLMs由于缺乏情感体验,无法直接理解和生成这种主观意义。
尽管LLMs缺乏情感体验,但它们可以通过映射训练数据中的语义关系,模拟人类的主观表达。LLMs通过学习大量的文本数据,掌握了人类在不同情境中使用语言表达情感和态度的方式,从而能够生成类似人类的情感表达。
例如,LLMs可以生成包含情感词汇的文本,模拟人类在表达情感时的语言模式。然而这种模拟是基于统计模式和概率计算的,缺乏真实的情感体验。因此,尽管LLMs在某些任务中能够生成看似情感丰富的文本,但它们无法真正理解和体验这些情感。
人类与LLMs在语言理解和使用方面存在显著差异。人类通过多层次的社会互动和个人经验,发展出复杂的认知和情感能力,而LLMs则依赖于静态的训练数据,缺乏情感体验和社会互动。这些差异揭示了LLMs在处理复杂的社会和情感任务时的局限性,同时也为未来的研究和发展提供了重要的方向。
意图处理与意义导航
1. 意图处理的挑战
Transformer算法在自然语言处理领域取得了显著的成功,特别是在处理长距离依赖关系和生成连贯文本方面。当涉及到意图处理时,Transformer算法仍然面临一些挑战。当前的Transformer算法将意图视为普通词汇,难以在没有额外训练的情况下准确地链接远程意图(D-intentions)和近程意图(P-intentions)。
这种局限性主要源于Transformer算法依赖于统计模式和概率计算,而不是基于实际的意图理解。Transformer模型通过处理大量的文本数据,学习到词汇和句子之间的关联,但它们缺乏人类在处理意图时所具备的灵活性和推理能力。人类可以通过上下文和经验,灵活地链接不同层次的意图,而LLMs则需要大量的训练数据来学习这些关联。
人类在处理意图时,能够通过推理和经验,灵活地链接不同层次的意图。例如,当一个人说「我想做晚饭」,我们可以推断出他可能需要准备食材、烹饪和清理等一系列动作。这种推理能力使得人类能够在复杂的情境中准确理解和执行意图。
相比之下,LLMs在处理意图时,主要依赖于训练数据中的统计模式。虽然LLMs可以通过学习大量的文本数据,掌握一些常见的意图关联,但它们缺乏人类的推理能力和经验积累。这使得LLMs在处理复杂的意图时,可能会出现理解错误或生成不连贯的响应。
2. LLMs的意义导航
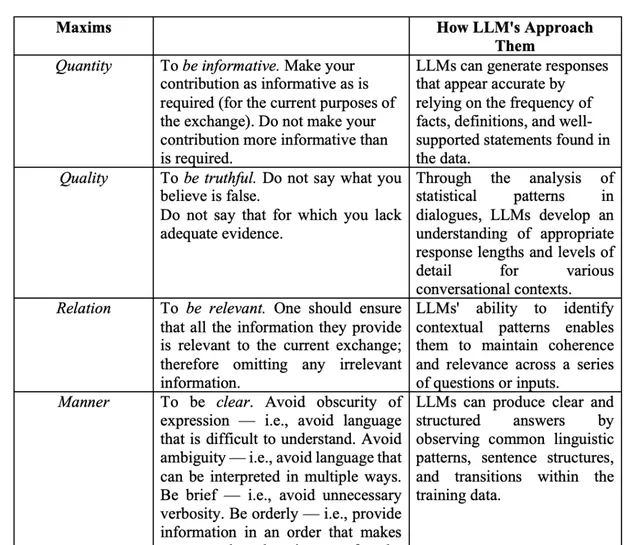
表3:Grice合作原则
为了更好地理解和生成语言,LLMs需要遵循Grice的合作原则。Grice在1975年提出的合作原则,旨在解释人类在对话中如何通过合作来实现有效的交流。合作原则包括四个准则:数量(Quantity)、质量(Quality)、关系(Relation)和方式(Manner)。
- 数量准则:提供足够的信息,但不过多。
- 质量准则:提供真实的信息,不提供虚假或不准确的信息。
- 关系准则:提供相关的信息。
- 方式准则:以清晰、简洁和有条理的方式提供信息。
LLMs通过依赖大量训练数据中的统计模式,展示了遵循Grice合作原则的能力。在生成响应时,LLMs会根据上下文和用户的提问,提供相关且信息丰富的回答。例如,当用户问「今天的天气如何?」时,LLMs会根据训练数据中的模式,生成一个关于天气的相关回答。
然而LLMs在处理隐含和上下文意义时,仍然面临挑战。人类在对话中,常常通过违反合作原则来传达隐含意义,如讽刺、反讽等。这种隐含意义通常依赖于上下文和情境,而LLMs由于缺乏情感体验和社会互动,难以准确理解和生成这种隐含意义。
LLMs在处理隐含和上下文意义时,主要依赖于训练数据中的统计模式。然而,这种方法在面对复杂的情境和隐含意义时,可能会出现局限性。例如,当用户使用讽刺或反讽时,LLMs可能无法准确理解其真正意图,从而生成不恰当的响应。
为了解决这样的问题,研究人员正在探索多种方法来提高LLMs的理解和生成能力。例如,通过引入外部知识源和反事实思维,LLMs可以更好地理解和处理复杂的情境和隐含意义。此外,增强检索技术和提示工程(prompt engineering)也可以帮助LLMs更准确地链接高层次意图和低层次意图,从而生成更连贯和有意义的响应。
LLMs在意图处理和意义导航方面仍然面临许多挑战。尽管它们在遵循合作原则和生成连贯文本方面表现出色,但在处理隐含意义和复杂情境时,仍然存在显著的局限性。
结论
1. Psychomatics框架的贡献
Psychomatics框架通过结合认知科学、语言学和计算机科学,为理解人工智能系统,特别是大型语言模型(LLMs)的认知能力提供了新的视角。该框架不仅关注LLMs的外部行为,还深入探讨其内部信息处理机制,揭示了LLMs如何感知、学习、记忆和使用信息。
通过比较LLMs和人类认知过程,Psychomatics框架揭示了两者在语言发展和使用过程中的异同。人类的语言发展是一个动态的、连续的过程,涉及社会、情感和语言互动,而LLMs则通过静态的、预定义的数据集进行训练。这种比较研究不仅有助于理解LLMs的工作原理,还为开发更智能、更人性化的AI系统提供了理论指导。
此外,Psychomatics框架还强调了语言的多源性和复杂性。人类语言的意义不仅来自词语的字面含义,还包括情境、文化和个人经验等多种来源。通过深入研究这些多源性,Psychomatics框架为理解语言、认知和智能的本质提供了新的见解。
Psychomatics框架的研究成果对AI系统的发展具有重要启示。首先通过揭示LLMs在处理复杂意义和意图方面的局限性,Psychomatics框架为改进AI系统提供了具体的方向。例如,LLMs在处理隐含意义和复杂情境时,往往依赖于统计模式和概率计算,缺乏人类的推理能力和情感体验。未来的研究可以通过引入外部知识源、反事实思维和增强检索技术等方法,提高LLMs在这些方面的能力。
其次,Psychomatics框架强调了多学科交叉研究的重要性。单一学科的研究方法已经无法满足对复杂AI系统的全面理解。通过结合认知科学、语言学和计算机科学,Psychomatics框架为开发更智能、更人性化的AI系统提供了全面的理论基础。
最后Psychomatics框架还为AI系统的伦理和社会影响研究提供了重要参考,随着AI技术的快速发展,AI系统在社会中的应用越来越广泛,其伦理和社会影响也日益受到关注。通过深入研究LLMs的认知能力和局限性,Psychomatics框架为制定AI系统的伦理规范和社会政策提供了科学依据。
2. 未来研究方向
未来的研究可以进一步探索LLMs与人类认知的比较,特别是在语言发展和使用过程中的异同。通过更详细的比较研究,可以揭示LLMs在处理语言和认知任务时的优势和局限性,从而为改进AI系统提供具体的方向。
例如可以通过实验研究,比较LLMs和人类在处理复杂语言任务时的表现,分析两者在信息处理、推理和情感理解方面的差异。此外,还可以通过引入新的数据集和训练方法,探索如何提高LLMs在处理复杂意义和意图方面的能力。
为了提高LLMs在处理复杂意义和意图方面的能力,未来的研究可以探索多种方法。例如,通过引入外部知识源,LLMs可以获得更多的背景信息,从而更好地理解和生成复杂的文本。此外,反事实思维和增强检索技术也可以帮助LLMs更准确地处理隐含意义和复杂情境。
提示工程(prompt engineering)也是一个重要的研究方向。通过设计更有效的提示,可以帮助LLMs更准确地链接高层次意图和低层次意图,从而生成更连贯和有意义的响应。例如可以通过设计多层次的提示,帮助LLMs理解用户的复杂意图,从而生成更符合用户需求的响应。
总的来说,Psychomatics框架为理解和改进AI系统提供了新的视角和方法。通过多学科交叉研究,未来的研究可以进一步探索LLMs与人类认知的比较,提高LLMs在处理复杂意义和意图方面的能力,从而开发出更智能、更人性化的AI系统。(END)
参考资料:https://arxiv.org/pdf/2407.16444

波动世界(PoppleWorld)是噬元兽数字容器的一款AI应用,是由AI技术驱动的帮助用户进行情绪管理的工具和传递情绪价值的社交产品,基于意识科学和情绪价值的理论基础。波动世界将人的意识和情绪作为研究和应用的对象,探索人的意识机制和特征,培养人的意识技能和习惯,满足人的意识体验和意义,提高人的自我意识、自我管理、自我调节、自我表达和自我实现的能力,让人获得真正的自由快乐和内在的力量。波动世界将建立一个指导我们的情绪和反应的价值体系。这是一款针对普通人的基于人类认知和行为模式的情感管理Dapp应用程序。











