除了好多行业,人工智能还会促使能源行业转变,给出优化能源系统运行和可靠性的新法子,保证技术经济方面的优势。
不过呢,把 AI 融入到能源部门会碰到想不到的阻碍,这些阻碍或许能让处理 AI 融入的乐观方式变一变。
【人工智能】
人工智能的计划能往前追溯好几十年呢。人工智能的历史和 1946 年诞生的计算机「电子数字积分器和计算机 (ENIAC)」有关系。
在 20 世纪 50 年代初,因为访问只能执行命令的那种基础计算机既有限又费钱,Alan Turing 就对计算机器和智能的概念展开了探索。
Turning 觉得,既然人类能通过分析现有信息和相关原因来解决问题、做出决策,那给机器提供输入,为啥它就不能干同样的事儿呢?
在 1957 年至 1974 年这段时间,计算机变得更快、更便宜,能执行和存储更多的数据,与此同时,改进机器学习算法的这个趋势,能被叫做 AI 努力的繁荣阶段。
1980 年往后,人工智能那股子雄心壮志推动了像机器学习、深度学习、量子计算之类相关技术的进步,引来大胆的投资,还鼓舞着年轻一代让人工智能成为未来科技的重点。
比如说,日本的第五代计算机计划(FGCP)属于一个行业研究联盟,在 1982 年到 1990 年期间,预算有 4 亿美元,用在革新计算机处理、推行逻辑编程以及改进人工智能上。
在 AI 应用于学生层面成为基本的 AI 逻辑编程之前,它历经了 40 多年才变得智能,这跟 1980 年到 2017 年左右 AI 风格的建构主义所取得的巨大成就关系紧密。图 1 简单概括了从文献获得启发的能源领域智能计算和人工智能应用的历史走向。
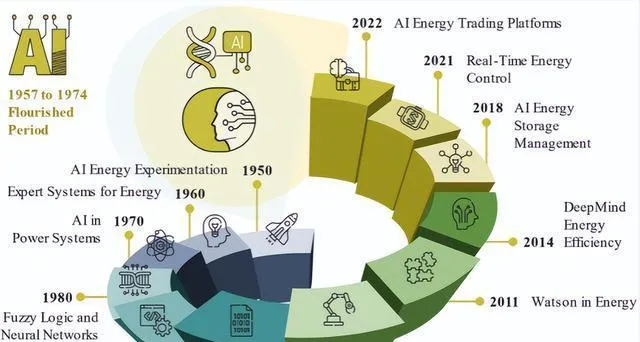
到了第五产业时代,技术会迅速发展,对包括能源行业在内的所有行业都产生影响,还会在政策制定的过程中展现新算法。
在现代能源的格局里,不光要跟工业 4.0 相结合从而达到工业 5.0 的标准,还冒出了「人与机器」这一概念,像协作机器人、瞄准系统,并且依靠智能技术能以灵活有弹性的方式融入社会。
机器人啥优势都有,这让人们害怕它会把工作抢走,还改变劳动力市场。虽说协作机器人没法替代劳动力,不过能补上社会老龄人口的缺口。
比如说,有报道称,到 2060 年,超过三成的欧洲人会超过 65 岁,这就让劳动力的需求变得很高。
有消息说,像工业 4.0+、4.5、6.0、7.0 这类流行词用得越来越多,得留神。虽说这些术语在学术写作和资助申请方面可能挺常见的,可它们不一定能帮着做出实际的商业决定,也不一定能解决真正的技术难题。
【人工智能在能源领域的挑战】
在电力系统里,机器学习和人工智能在大量可再生能源的高级监测、控制、操作与集成方面,在处理不确定性和不稳定性方面,在适应不断变化的状况方面,还有管理智能电网的新情况方面,都特别重要。
不过,这些新办法还得融入遗留下来的那种利用灵活性以及优化的机器学习方法的基础设施和实践里。
在如今这个数据大量生成与交换的综合化世界,得有强大的基础设施,才能从各个领域的多学科信息交流里找出有用的信息。
人工智能(AI)能解决工业革命时代这种复杂又多方面的需求。从图 2 里对挑战做的初步分类,可以帮着找出关键问题,还能按照它们跟每个类别的关联程度,给解决方案排个先后次序,这样就能给能源系统里 AI 的集成制定出更有针对性、更有效的策略。
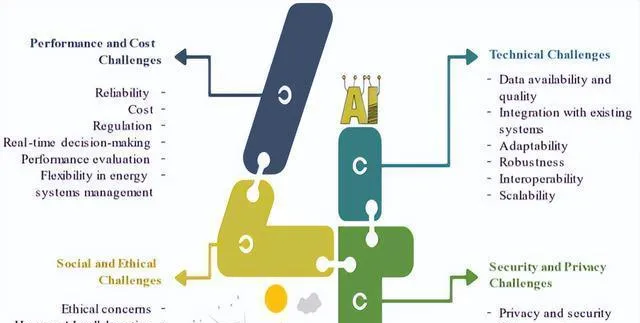
把 AI 融入能源部门这件事,有成功也有失败,宝贵经验表明,这主要看数据准不准、算法选得对不对、项目管理好不好、跟现有系统能不能集成、监控评估到不到位、有没有利益相关者支持、专业知识够不够、预算和资源足不足、期望是不是切合实际,还有对伦理和社会影响有没有考虑周全。
图 3 和图 4 把挑战的类别、因素,还有它们的相互关系以及变量流给可视化呈现出来了,凸显出了主要类别和相应子类别之间的关联。图 4 里的流向给这些变量间复杂的相互依赖关系提供了很有价值的看法。
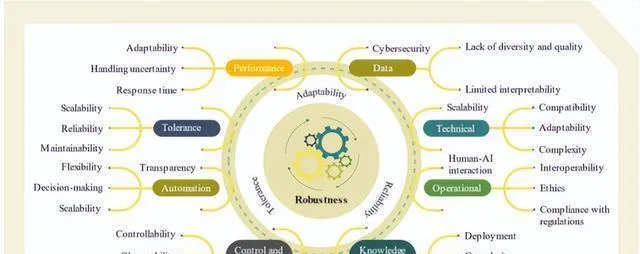

如今这世界越来越依靠智能技术去解决那些复杂的难题,在琢磨于各个行业(特别是能源行业)推行人工智能的时候,有好几个因素是能起作用的。
在这些因素里面,复杂性、环境以及重要性,对人工智能在能源项目里的整体影响还有成功的部署有帮助。
复杂性主要在于把 AI 技术跟现有的基础设施融合起来,往往得有高质量的、大量可用的数据。这会有难题,毕竟实施的人既要保留人类的专业本事,又得把人工智能用好。
中等水平的人机协作以及可解释性,这对保证个人能明白和信赖这些技术的产出很有必要。
另外,适度的灵活性在有效的能源系统管理里特别重要,这或许会关系到适应一直在变的需求或者整合新的能源。
虽说对人在环路和绩效评估重视不够,可这些因素还是跟打造更牢固、更靠谱的人工智能策略有关系。
通常来说,AI 施行的环境会决定各个行业能成功多少、被接受的程度咋样。像数据的高可用性和质量、隐私、安全,还有跟新的以及现有的设置相融合,这些都是得解决的重要方面。高成本和投资方面的要求,有可能给一些公用事业造成阻碍,让可扩展性变成了重要的问题。
关键性能确保人工智能系统得以负责、有效地推行,得把隐私和安全性、可解释性、可靠性、监管以及可扩展性放在高位优先考虑。这些方面能保证人工智能的办法在技术上靠谱,也符合道德和法律的标准。
环路、伦理问题、网络安全以及透明度这些方面也挺重要的,被看成是中等优先的事儿,毕竟它们能帮助建立起对人工智能系统的信任和信心。
人机协作、数据的可用性和质量、跟现有系统的集成、成本与投资,还有绩效评估,这些被看成是低优先级的因素,不过它们还是能通过优化能源系统的运作,推动人工智能对社会产生整体影响。
复杂性、环境以及关键性这三者的关系,给弄明白在各个行业推行人工智能系统时面临的挑战和机遇,提供了很有价值的看法。
把这些因素处理好,能保证成功用上 AI 技术,还能最大程度发挥它的好处,把潜在风险降到最低。
想想这些因素会对人工智能战略的制定和部署产生啥影响,利益相关者就能更好地搞清楚人工智能在自己那块领域的作用,在采用和部署它的时候能做出更明白的决定。
搞明白底层模型,安排好合适的工具和技术,对保证机器学习应用程序有效果特别重要。数据质量在得到准确靠谱的结果上起着关键作用。
凭借高质量的数据集能够最大程度降低错误与偏差,还能提升机器学习算法的整体表现。
要不想有不好的结果,从业者得好好琢磨模型、技术还有数据源咋选,还得紧盯着实施的过程,保证机器学习系统能像预想的那样运转。
就算优化凸函数,也会有这些难题,导致很难找到深度模型。假设得出的结果表明了限制算法性能存在困难,不过它们不一定能在使用神经网络的实际运用中管用。目标并非是找出函数的准确最小值,而是把它的值降低到能够得到合理的泛化误差限制就行。
【AI集成要求和难题】
人工智能(AI)属于计算机科学的一个范畴,在 1950 年代就有了,它主要是研究智能方面的情况,通过计算机模拟人类的思考过程,靠计算机的逻辑运算来实现对智能的科学认识,进而能更好地理解和展现人类的大脑思维。
计算智能出现在二十世纪,能让计算机模仿人类的学习以及决策能力,变成了当下生活中改变游戏规则的存在。不考虑模型的准确性、依赖性之类的因素,去做数值建模和分析。
用能源、火用、环境和经济的数值概念对混合废物能源系统进行了分析,目的是减少排放污染,让电力生产成本实现平衡。
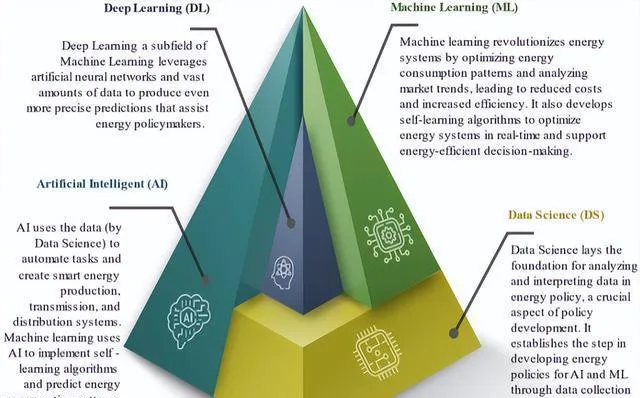
图 5 展现出了一个新的规划,这意味着 DS 给数据的分析及解释打下了基础,AI 和 ML 则利用这些数据去告知和引导不同层级且相互关联、有所重叠的能源政策决策。
数据科学(DS)能做的事儿可多啦,像分类、回归、关联分析、聚类、异常检测、推荐引擎、特征选择、时间序列预测、深度学习、文本挖掘啥的。而 AI 和 ML 只在特定的需求场景里有用。
要概括这三个相互依赖关系紧密的层次,目前还是个难题。
数据科学靠着大计划里的数据收集与分析,给人工智能和机器学习制定能源政策迈出了第一步。
AI 依靠这些数据能自动完成任务,还能构建智能的能源生产、传输及分配系统,ML 则借助 AI 去落实自学习的算法,并且预测能源消耗的模式、市场的走向以及系统的性能。
AI 跟 ML 是基于 DS 的,它们靠数据去识别模式、做预测还有设想蓝图,这样能让决策者在国家和区域的技术以及循环经济的基础上,给系统设置做出明智的决定。
把机器学习放进能源政策里得有准确的数据驱动模型跟合适的数据集才行。把政策流程拆分成能管理的部分,这样能把数据分析跟数据集创建做得更好。
智能电网的数据又多又多变,这给 AI 算法带来了难题,得把鲁棒性、适应性还有在线处理改进一下。数据驱动的模型不用系统动力学的先验知识就能认出历史数据里的模式,可基于参数的模型得依靠数学方程和系统方面的知识。
数据驱动模型能自动学习模式,有高精度的可能,还能随着时间靠新数据来改进。但它也有不足,像对过度拟合很敏感、对数据质量敏感,而且解释起来困难。
数据对于机器学习和分析来说特别重要,要经过好多处理环节来保证质量和能用,不过虽说大数据在学术和工业领域都挺火,可「大数据」这个术语在概念上还是挺模糊的。
数据处理的阶段里有数据收集这一项,这得从好多来源去收集原始数据,像网络抓取、API、调查还有数据库啥的。
数据清理能把不一致、重复的东西消除掉,还能处理缺失值,让数据质量变高。数据标记呢,是用相关的标签给监督学习任务去注释或者标记数据。数据扩充则是创造新的或者修改数据实例,把数据集扩大、变得多样,提升模型的性能。
数据编码能把数据弄成机器能读的那种格式,像 one-hot encoding 和 label encoding 啥的。特征提取就是从原始数据里找出本质特征来展现和概括它。特征缩放是把数据特征给标准化、规范化,好保证对模型训练有一样的作用。特征工程是创造新特征或者进行转换,让数据集的预测能力变强。
数据插补就是拿基于现有的数据得出的估计值去把缺失值填上,数据集成是把来自多个来源的数据集整合到一块儿,弄出一个统一的数据集。
降维能让特征的数量变少,不过会把最有关联的信息留住。数据匿名化借助数据屏蔽、泛化这类技术来护住数据集中的敏感信息。数据拆分把数据集分成训练、验证和测试这几个子集,用来估量模型的性能。数据洗牌就是重新把数据样本的顺序打乱,免得模型训练时有偏差。
数据版本控制能追踪变化,还能维护数据集的过往记录,为的是达到可重复性和审计的目标。
数据存储负责管理各种形式的存储,像云存储、本地存储以及数据库。数据验证通过统计测试、可视化还有异常值检测来保证数据的正确和一致。最后,数据监控留意性能指标、进行实时监控以及通知相关的数据管道,从而维持数据的质量与完整性。
由于收集、探索和分析大数据的需求持续上升,AI 被用来优先处理这些大数据集和实现自动化操作,在各种平台的众多应用里都能用。充足的能源供应和需求规划跟分析大量过往数据有关,这样才能有效满足当下需求,并最好地预测未来的增长模式。
把领域专业知识(像技术、经济、制度、社会之类的)结合起来,靠着被叫做数据科学的技术创新(比如编码、处理、操作等)来支持优化效率、把损失降到最小,从而平衡供需以及科学方法论(像数学、统计、算法等),这是人工智能平台的核心所在。
人工智能在能源领域的应用能协调系统优化、自动化系统以及能源政策目标,因为从应用角度来看,它们的目标紧密交叉,这是个共同点。凭借这个,政策制定者就能依据单一目的的新兴双重优化因素来制定综合路线图,从而把人工智能用得最好。
要解决人工智能在能源系统应用里的那些局限性,得用一种协调的办法,依照行动方案把政策制定中的能源管理实施给优化好。

其次是搞人力资源能力建设,让人能跟协作机器人还有类人机器人合作,达成组织的目标。
现在能实时访问不同层级利益相关者的信息,隐私和伦理方面变得比过去更重要了,可这在之前的能源政策里没被好好处理。
所以,它提醒政策制定者,在政策从制定到更新的整个过程中,得严格把这个问题考虑进去。比如说,用无人机给输电线路或者风力涡轮机做预防性或者纠正性的维护。
人工智能有希望凭借给出创新的解决办法,把系统运行给优化了,让可靠性提升,还能保证技术经济方面的优势,进而把能源行业彻底改变。
这些优势能让效率变高,把需求平衡和预测给优化好,凭借优化后的预防性、纠正性维护让系统更稳定、更可靠,实现经济的高收益运行,做好适当的机组承诺,还能对供需进行控制从而达到市场优化。
简化决策流程,减少运营以及资本方面的支出,能帮助打造出成本效益更高的能源部门。最后,凭借数据驱动的解决办法保证网络安全得到增强,让能源系统在经济上能行得通、能被使用并且可持续。
不过呢,人工智能跟能源领域成功结合的过程中,有一些想不到的阻碍,这或许会让人对采用人工智能不再那么乐观。
参考文章:Danish, M.S.S. 【人工智能在能源领域:克服意外的阻碍】。AI 2023 年,第 4 期,406 - 425 页。











