定距数据 是沿着相邻值之间距离相等的数值刻度测量的。这些距离称为「间距」。
定距刻度上没有真正的零点,这就是它与比率数据的区别。在定距尺度上,零是任意点,而不是变量的完全不存在。
区间量表的常见示例包括标准化考试(如 SAT)和心理量表。
3.5.1. 测量水平
间隔是四个分层测量级别之一。测量水平表明数据记录的精确程度。级别越高,测量越复杂。
名义变量和有序变量是分类变量,而定距变量和比率变量是定量变量。与分类数据相比,可以对定量数据进行更多的统计检验。
3.5.2. 定距与比率刻度
定距和比率刻度在值之间具有相等的间隔。但是,只有比率刻度具有表示完全不存在变量的真零。
摄氏度和华氏度是 定距尺度 的例子。这些刻度上的每个点与相邻点的间隔正好相差一度。20 度和 21 度之间的差异与 225 度和 226 度之间的差异相同。
然而,这些刻度具有任意的零点——零度并不是可能的最低温度。
由于没有真正的零,因此无法在区间刻度上乘以或除以分数。30°C 的温度不是 15°C 的两倍。 同样,-5°F 的温度也不低于 -10°F 的一半。
相比之下,开尔文温标是一个 比率刻度 。在开尔文标度中,没有什么比 0 K 更冷的了。因此,以开尔文为单位的温度比很有意义:20 K 的温度是 10 K 的两倍。
3.5.3. 定距数据示例
智力等心理概念通常通过测试或清单中的操作化来量化。这些测试的分数间隔相等,但它们没有真正的零,因为它们无法衡量「零智力」或「零人格」。

要确定刻度是定距的还是有序的,请考虑它是否使用具有固定测量单位的值,其中任意两点之间的距离是已知大小的。例如:
将数据视为定距数据可以执行更强大的统计检验。
3.5.4. 定距数据分析
要大致了解研究过程中所收集的数据,研究人员可以首先收集以下描述性统计信息:
区间数据示例:
收集来自 A 市的 59 名应届毕业生的 SAT 分数,考生的 SAT 分数可以在 400-1600 之间。
频率分布:
表格和图形可用于显示并可视化其分布。

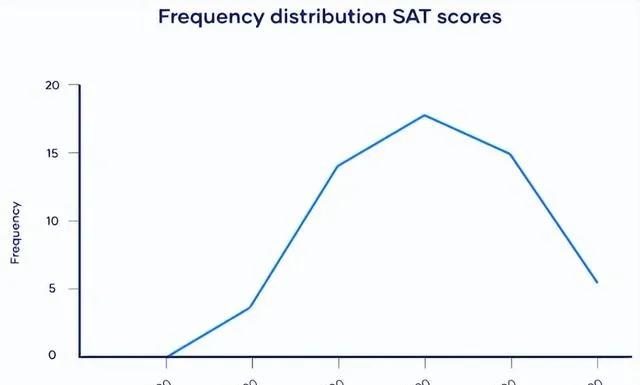
集中趋势
从图表中,可以看到数据是相当正态分布的。由于没有偏度,要找到大多数值的位置,研究人员可以使用所有 3 种常见的集中趋势度量:众数、中位数和平均值。
(1) 众数:众数是数据集中最常重复的值。在这种情况下,没有模式,因为每个值只出现一次。
(2) 中位数:中位数是正好位于数据集中间的值。要找到中间位置,请取 (n+1)/2 处的值,其中 n 是值的总数。
(n+1)/2 = (59+1)/2 = 30
中位数位于第 30 位,其值为 1120。
(3) 平均数:均值使用所有值为您提供一个数字,以表示数据的集中趋势。要找到平均值,请使用公式 ∑x/n。将所有值 (∑x) 相加,然后将总和除以 n。
∑x = 65850 n = 59 ∑x/n = 65850/59= 1116.1
当所收集到的定量数据呈正态分布时,平均值通常被认为是集中趋势的最佳度量。这是因为它使用数据集中的每个值进行计算,这与众数或中位数不同。
离散趋势
全距、标准差和方差描述了数据的分布程度。全距是最容易计算的,而标准差和方差更复杂,但信息量也更大。
(1)全距:要查找全距,请从数据集中的最高值中减去最小值。我们的最大值是 1500,最小值是 620。
范围 = 1500 – 620 = 880
(2)标准差:标准差是数据集中的平均变异量。平均而言,它告诉您每个分数与平均值相差多远。大多数计算机程序都可以计算标准偏差。
s = 210.42
(3)方差: 标准差是数据集中的平均变异量。平均而言,它告诉您每个分数与平均值相差多远。大多数计算机程序都可以轻松为您计算标准偏差。
S2 = 210.42
统计检验
经过上面的数据简要分析,研究人员已经对数据有了大致的了解,可以选择适当的检验来进行统计推断。在区间数据呈正态分布的情况下,参数检验和非参数检验都是可能的。
参数检验在统计上比非参数检验更强大,可让研究人员对数据做出更有力的结论。但是,数据必须满足若干要求才能应用参数检验。
以下参数检验是一些最常见的参数检验,用于检验有关定距数据的假设。












