Meta超大規模AI智算基礎設施架構設計

摘要
- 雙重 GPU 集群,每群配備 2.4 萬個 p00 芯片,分別采用 RoCE 和 InfiniBand 網絡連線。
- LLaMA3 就是在這兩個集群上訓練出來的 ;
- Meta AI 將部署龐大算力集群,擁有 35 萬張 p00 GPU,相當於 60 萬張 p00 的總算力,助力突破性人工智能研究。
Meta打造兩個龐大AI集群,每個集群擁有2.4萬張GPU。該設計專註於計算、網絡和儲存的無縫整合,旨在推動人工智能的未來發展。
1 第一代 GPU 集群: 1.6w A100 (RSC)
Meta 自 2022 年起公開其強大的 AI 基礎設施,率先推出 Research SuperCluster (RSC),該集群由 16,000 個 A100 GPU 組成。RSC 為 Meta 的 AI 研究和開發提供了無與倫比的計算能力。
RSC為Meta AI開發提供技術支持,助力其構建將生成式AI融入各類套用,如電腦視覺、NLP、語音辨識、影像生成和編碼。RSC的先進能力顯著提升了Llama/llama2等AI模型的訓練效率。
2 第二代 GPU 集群:2.4w p00
精確數碼是每個集群 24,576 張 p00 GPU。
Meta新一代 AI 集群充分吸收了 RSC 的成功和經驗教訓,這包括,
Meta 自研關鍵技術,搭建先進基礎設施,每天高效執行萬億級 AI 任務。端到端最佳化確保數據中心高效執行,支撐著 Meta 的 AI 創新。
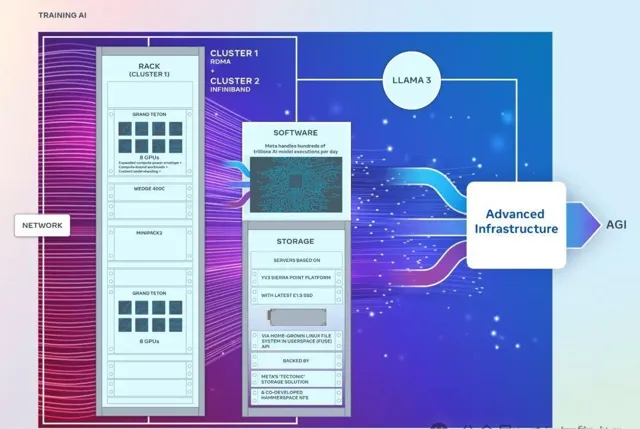
左側:電腦櫃,包括GPU伺服器機框、fabric交換機等等;右側:儲存機櫃。
2.1 計算: Grand Teton GPU 主機
雙新集群采用 Grand Teton,這是 Meta 開發的一種開放的 GPU 硬件平台,已貢獻給開放計算專案 (OCP)。
從2015年的Big Sur平台開始,Meta一直在開放設計GPU硬件平台。
Grand Teton 實物圖如下,

創新的Open Rack電源和機架架構相結合,可迅速構建和客製Meta當前和未來的集群,滿足不斷增長的應用程式需求。
2.2 網絡
兩個集群使用了不同的網絡方案,但都是 400Gbps 接入。
2.2.1 集群一:400Gbps RoCE + 自研交換機
基於 RoCE 網絡,使用的交換機包括
Facebook 的下一代數據中心網絡:「數據中心 Fabric」(2014 年)
2.2.2 集群二:400Gbps InfiniBand
使用NVIDIA Quantum2 InfiniBand fabric。
2.2.3 小結
在評估大規模訓練中的 RoCE/IB 適用性和可延伸性時,對比研究表明:
RoCE 和 IB 組網的集群均可處理大型生成式 AI 任務,例如 Llama 3 的訓練,且未遇網絡限制。
這些發現為構建更大規模集群提供指導,有助於解決大型生成式 AI 訓練模型的網絡挑戰。
2.3 儲存
儲存在 AI 訓練中扮演著重要角色,然而相關的討論確非常少。
人工智能任務的多模態性推動了對高效能儲存的需求。理想的解決方案應提供卓越效能,並在處理影像、影片和文本時保持低能耗。
2.3.1 數據和 checkpoints 儲存:FUSE + Tectonic
AI 集群的數據和 checkpoint 的儲存方案:
這個解決方案使得
2.3.2 互動式偵錯:Parallel NFS
與 Hammerspace 合作開發的並列 NFS 系統,可支持數千個 GPU 的互動式偵錯。程式碼改動能瞬間同步到環境中的所有節點,顯著提升偵錯效率。
Tectonic 分布式儲存與 Hammerspace 相結合,釋放了企業數據快速叠代的潛能,同時打破了規模限制。
2.3.3 大容量 SSD + 客製每個機櫃的伺服器數量
Tectonic 和 Hammerspace 解決方案均采用 YV3 Sierra Point 伺服器平台,整合了市場上最先進的高容量 E1.S SSD,提供卓越的效能和儲存容量。

OCP 伺服器如同樂高積木,賦予儲存層靈活擴充套件性,滿足未來 AI 集群的增長需求,且不影響日常維護和操作,為數據中心提供敏捷高效的基礎架構。
3 效能
3.1 原則:效能和易用性缺一不可
構建 AI 集群的關鍵是兼顧效能與易用性,避免顧此失彼。這種均衡至關重要,因為它確保了訓練出卓越的 AI 模型。
最佳化大型系統設計的最佳方法是透過叠代構建和測試。小集群和大型集群的效能比較可以幫助辨識瓶頸。下圖以訊息大小為橫軸,歸一化頻寬(0-100)為縱軸,展示了當大量 GPU 互動時 AllGather 效能隨集群規模的變化。
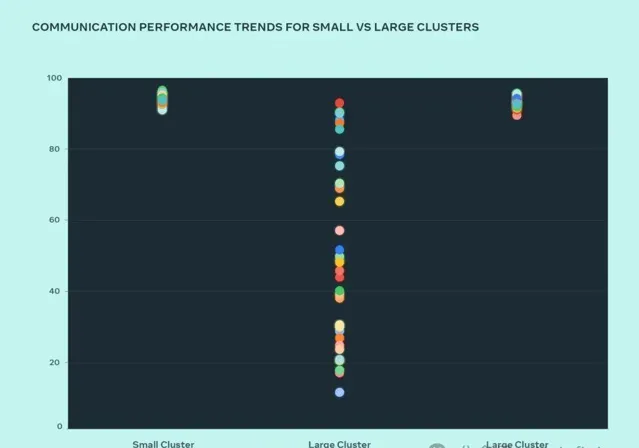
最佳化前:小型集群效能優異(90%+),大型集群效能低下(10%-90%)。
最佳化後:透過系統化最佳化,大型集群效能飆升至理想的90%+,與小型集群齊頭並進。
3.2 大集群最佳化
最佳化大型集群效能:
* 透過減少wait time提升效能85%。
* 最佳化hash slot分配方式提升效能15%。
-
改進
job scheduler
,使其具備
網絡拓撲感知能力
,這帶來的好處:
- 延遲降低
- 轉發到更上層網絡(交換機)的流量減少。
- 結合 NVIDIA NCCL ,最佳化了 網絡路由策略 ,以實作最優的網絡利用率。
以上兩項最佳化使大集群的效能已經接近小集群。
-
與
訓練框架和模型團隊
密切合作,不斷改進基礎設施。例如,
- 並列技術最佳化,
- 儲存最佳化,
-
可偵錯性是大型訓練的主要障礙,在大規模情況下難以追蹤拖慢訓練行程的卡頓原因。
為此,正在開發 desync 偵錯和分布式飛行記錄等工具,用於跟蹤分布式訓練流程,快速辨識問題。 -
PyTorch 最佳化顯著提升訓練速度:
透過最佳化行程組初始化,PyTorch 可支持數萬至數十萬 GPU 並列訓練。最佳化前,啟動時間可長達數小時,最佳化後縮減為幾分鐘。
4 對Open AI innovation的承諾
Meta 堅信開源技術的力量,旨在透過開放創新來解決行業難題:
- Meta 堅定地致力於開源硬件和軟件。
- 相信開源社區可加速 AI 領域的進步。
AI 工作建立在開放科學和協力合作的哲學之上。
5 未來展望
Meta為其未來 AI 願景打造了兩個強大的 AI 訓練集群。到 2024 年底,Meta 將擁有 35 萬張 p00 GPU,總算力相當於 60 萬張 p00,為其 AI 創新奠定了基礎。
持續最佳化基礎設施,從硬件到業務層面,確保靈活可靠。評估和改進流程以滿足不斷演變的需求,支持創新模型和研究,打造未來準備就緒的系統。
-對此,您有什麽看法見解?-
-歡迎在評論區留言探討和分享。-











