來源:半導體產業縱橫

「算力」相關產業近期持續火爆,智算中心的建設,也正在遍地開花。
進入 2024 年,就有武昌智算中心、中國移動智算中心(青島)、華南數谷智算中心、鄭州人工智能計算中心、博大數據深圳前海智算中心等相繼開工或投產使用。
據不完全統計,目前全國正在建設或提出建設智算中心的城市已經超過 30 個,投資規模超百億元。
到底什麽是智算中心?智算中心主要用來做什麽?智算中心都有哪些特點?
何為智算中心?
根據【算力基礎設施高質素發展行動計劃】定義,智算中心是指透過使用 大規模異構算力資源 ,包括 通用算力(CPU) 和 智能算力(GPU、FPGA、ASIC 等) ,主要為 人工智能套用 (如人工智能深度學習模型開發、模型訓練和模型推理等場景)提供所需 算力、數據和演算法 的設施。
也可以說,智算中心是以人工智能計算任務為主的數據中心。
數據中心通常包括三種類別,除了智算中心以外,另外兩種分別是以通用計算任務為主的通算中心,以及以超級計算任務為主的超算中心。
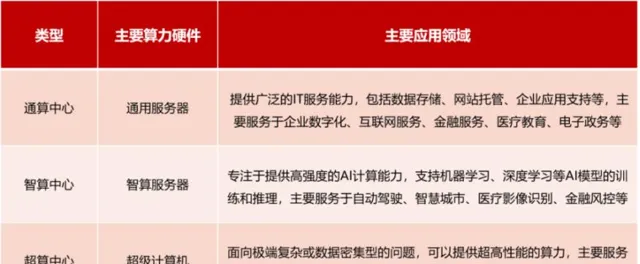
2023 年是人工智能發展的重要轉折年,AIGC 技術取得了突破性進展,大模型訓練、大模型套用等新業務正在快速崛起,作為智能算力的載體,數據中心也已經從數據機房、通算中心,發展到現階段的超算中心和智算中心。
智算中心與通用數據中心有何不同?
智算中心,通常與雲端運算緊密相關,強調資源控制和基礎設施管理的靈活性。 在雲環境中,數據中心提供商負責硬件和某些軟件工具的維護,而客戶則擁有數據。相比之下,傳統的本地數據中心需要由企業自行管理和維護所有的數據資源。
本質的不同導致兩種模式在資本投入、資源部署以及安全性方面都有著極大的區別。
在資本投入上, 智算中心客戶無需大量的硬件和軟件成本即可選擇適合自己的服務模式,如公有雲、私有雲或混合雲;而傳統數據中心的客戶則需要投入大量資金來購買和維護自己所需的伺服器、網絡和儲存器材。
在資源部署和安全性上, 智算中心的客戶可隨時隨地透過互聯網遠端存取和管理自己的數據和套用,與此同時還可以享受數據中心提供商提供的專業的安全保障,如防火墻、加密、備份和恢復等;而傳統數據中心的客戶受到辦公/指定地點的限制,且需自己進行保護和管理數據。
智算中心,簡單來說就是專門服務於人工智能的數據計算中心,能夠為人工智能計算提供所需的專用算力。相比傳統數據中心,智算中心能滿足更具針對性的需求,以及更大的計算體量和更快的計算速度,為大模型訓練推理、自動駕駛、AIGC 等各垂直行業場景提供 AI 算力。
AI 智算,需要什麽樣的芯片?
在硬件的選擇上,智算中心與傳統數據中心的硬件架構也有所不同。
AI 智算,需要什麽樣的算力芯片?
傳統數據中心的硬件架構比較單一,主要包含伺服器、儲存器材和網絡器材。智算中心相比於此硬件架構就會更加的靈活,不同的套用場景也會選擇不同的計算節點。
智算伺服器是智算中心的主要算力硬件,通常采用「CPU+GPU」、「CPU+NPU」或「CPU+TPU」的異構計算架構,以充分發揮不同算力芯片在效能、成本和能耗上的優勢。
GPU、NPU、TPU 的內核數量多,擅長平行計算。AI 演算法涉及到大量的簡單矩陣運算任務,需要強大的平行計算能力。
而傳統通用伺服器則是以 CPU 作為主要芯片,用於支持如雲端運算和邊緣計算等基礎通用計算。
AI 智算,需要什麽樣的儲存芯片?
不止是算力芯片的不同,AI 智算對儲存芯片也有著更高的要求。
首先是用量。智算伺服器的 DRAM 容量通常是普通伺服器的 8 倍,NAND 容量是普通伺服器的 3 倍。甚至它的 PCB 電路板層數也明顯多於傳統伺服器。
這也意味著智算伺服器需要布局更多的儲存芯片,以達到所需效能。
隨著需求的水漲船高,一系列瓶頸問題也浮出水面。
一方面,傳統馮諾依曼架構要求數據必須載入到記憶體中,導致數據處理效率低、延遲大、功耗高;另一方面,記憶體墻問題使得處理器效能的增長速度遠快於記憶體速度,造成大量數據需要在 SSD 和記憶體間傳遞;此外,CPU 掛載的 SSD 容量和頻寬限制也成為效能瓶頸。
面對「儲存墻」、「功耗墻」等問題,傳統計算體系結構中計算儲存架構亟需升級,將儲存與計算有機融合,以其巨大的能效比提升潛力,才能匹配智算時代巨量數據儲存需求。
針對這一系列問題,存算一體芯片或許是一個不錯的答案。
除了芯片不同之外,為了充分發揮效能以及保障穩定執行,AI 伺服器在架構、散熱、拓撲等方面也進行了強化設計。
這些芯片,誰在布局?
算力芯片的布局情況
在 GPU 方面, GPU 擅長大規模平行計算。華為、天數智芯、摩爾執行緒、中科曙光、燧原科技、輝達、英特爾、AMD 等都推出有相關的芯片。比如,華為推出了昇騰系列 AI 芯片昇騰 910 和昇騰 310 等,這些芯片專為 AI 訓練和推理設計,具有高效能和低功耗的特點。昇騰系列已廣泛套用於數據中心、雲服務和邊緣計算等領域,為智算中心提供強大的算力支持。
輝達推出了多款針對 AI 訓練和推理的 GPU 產品,如 A100、p00 等。英特爾也推出了多款 AI 芯片產品,如 Habana Labs 的 Gaudi 系列芯片,旨在與輝達競爭。AMD 在 AI 芯片領域也有所布局,推出了 MI 系列 GPU 和 APU 產品。
在 FPGA 方面, CPU+FPGA 則結合了靈活性與高效能,適應演算法快速變化。賽靈思、英特爾是市場主要參與者,相關產品有:賽靈思的 VIRTEX、KINTEX、ARTIX、SPARTAN 產品系列以及英特爾的 Agilex 產品系列;國內主要廠商包括復旦微電、紫光國微和安路科技等。
在 ASIC 方面, CPU+ASIC 提供高效能客製計算,適合特定需求。國外谷歌、英特爾、輝達等巨頭相繼釋出了 ASIC 芯片。國內寒武紀、華為海思、地平線等廠商也都推出了深度神經網絡加速的 ASIC 芯片。
在 NPU 方面, NPU 是專門為人工智能和機器學習場景而設計的處理器。與 CPU 和 GPU 不同,NPU 在硬件結構上進行了針對性的最佳化,專註於執行神經網絡推理等 AI 相關的計算任務。CPU 的通用性和 NPU 的專用性相結合,使得整個系統能夠靈活應對各種 AI 套用場景,快速適應演算法和模型的變化。
目前市場上已有眾多量產的 NPU 或搭載 NPU 模組的芯片,其中知名的包括高通 Hexagon NPU、華為的昇騰系列,值得註意的是,各大廠商在芯片計算核心的設計上都有著獨特的策略。
在 TPU 方面, TPU 是谷歌專門為加速深層神經網絡運算能力而研發的一款芯片,更加專註於處理大規模的深度學習任務,具備更高的計算能力和更低的延遲。TPU 也屬於一種 ASIC 芯片。
在 DPU 方面, DPU 專門設計用於數據處理任務,具有高度最佳化的硬件結構,適用於特定領域的計算需求。不同於 CPU 用於通用計算,GPU 用於加速計算,DPU 是數據中心第三顆主力芯片。國際三大巨頭輝達、博通、英特爾的 DPU 產品占據國內大多數市場,賽靈思、Marvell、Pensando、Fungible、Amazon、Microsoft 等多家廠商在近 2-5 年內也均有 DPU 或相似架構產品生產。國內廠商包括中科馭數、芯啟源、雲豹智能、大禹智芯、阿裏雲等。
國產算力芯片走到哪一步了?
在 2024 北京移動算力網絡大會上,中國移動算力中心北京節點正式投入使用,標誌著中國智算中心建設進入新階段。作為北京首個大規模訓推一體智算中心,該專案占地約 57000 平方米,部署近 4000 張 AI 加速卡,AI 芯片國產化率達 33%,智能算力規模超 1000P。
北京超級雲端運算中心營運實體北京北龍超級雲端運算有限責任公司 CTO 甄亞楠近日表示,目前幫國產大模型「嫁接」國產芯片,只需 15 天左右就可以跑通。他認為算力共享會是行業大趨勢,高端 GPU 算力資源需要各方努力。
近年來,中國人工智能算力芯片的市場格局主要由輝達主導,其占據了 80% 以上的市場份額。
甄亞楠表示,「我們也非常關註國產芯片的發展,據了解,國內自研的大模型,甚至一些開源的大模型都在不斷往國產芯片上去做移植。現在從芯片使用角度來講,有些模型已經可以跑通執行了,需要追趕的方面主要在類似 GPU 這種高效能。」
「整個的國產化是分層級的,芯片屬於硬件這一層,除此之外還有軟件的生態。對於國產的芯片來講,不管是框架還是生態,都需要有一定的培育周期。」甄亞楠呼籲,最終的套用方要給到國產芯片足夠的信心。
儲存芯片的布局情況
智算中心在儲存方面需要具備高容量、高可靠性、高可用性等特點。儲存器材通常采用高效能的硬碟或固態硬碟,並配備冗余的儲存架構,以確保數據的安全性和可存取性。三星、美光、SK 海力士等都有相關芯片都廣泛套用於數據中心、雲端運算等領域,為智算中心提供高效能的儲存解決方案。
國內廠商近年來在 DRAM 與 NAND 技術追趕上也實作了快速發展。
除了傳統的儲存芯片外,智算中心還需要上文提到的新型儲存—存算一體芯片發揮更大的作用。
從存算一體發展歷程來看,自 2017 年起,輝達、微軟、三星等大廠提出了存算一體原型,同年國記憶體算一體芯片企業開始湧現。
大廠們對存算一體架構的需求是實用且落地快,而作為最接近工程落地的技術,近存計算成為大廠們的首選。諸如特斯拉、三星等擁有豐富生態的大廠以及英特爾、IBM 等傳統芯片大廠都在布局近存計算。
國內初創企業則聚焦於無需考慮先進制程技術的存內計算。其中,知存科技、億鑄科技、九天睿芯等初創公司都在押註 PIM、CIM 等「存」與「算」更親密的存算一體技術路線。億鑄科技、千芯科技等專註於大模型計算、自動駕駛等 AI 大算力場景;閃易、新憶科技、蘋芯科技、知存科技等則專註於物聯網、可穿戴器材、智能家居等邊緣小算力場景。
億鑄科技致力於用存算一體架構設計 AI 大算力芯片,首次將憶阻器 ReRAM 和存算一體架構相結合,透過全數碼化的芯片設計思路,在當前產業格局的基礎上,提供一條更具性價比、更高能效比、更大算力發展空間的 AI 大算力芯片換道發展新路徑。
千芯科技專註於面向人工智能和科學計算領域的大算力存算一體算力芯片與計算解決方案研發,在 2019 年率先提出可重構存算一體技術產品架構,在計算吞吐量方面相比傳統 AI 芯片能夠提升 10-40 倍。目前千芯科技可重構存算一體芯片(原型)已在雲端運算、自動駕駛感知、影像分類、車牌辨識等領域試用或落地;其大算力存算一體芯片產品原型也已在國內率先透過互聯網大廠內測。
知存科技的方案是重新設計記憶體,利用 Flash 快閃記憶體儲存單元的物理特性,對儲存陣列改造和重新設計外圍電路使其能夠容納更多的數據,同時將算子也儲存到記憶體當中,使得每個單元都能進行模擬運算並且能直接輸出運算結果,以達到存算一體的目的。
智算規模占比超 30%,算力建設如火如荼
7 月初,天府智算西南算力中心正式在四川成都投運。據介紹,該中心將以算力支撐成都打造千億級人工智能核心產業,賦能工業制造、自然科學、生物醫學、科研模擬實驗等領域的人工智能創新。
這不是個例。近一個月來,銀川綠色智算中心專案集中開工;北京移動在京建成首個大規模訓推一體智算中心,支撐高復雜度、高計算需求的百億、千億級大模型訓練推理;鄭州人工智能計算中心開工建設,總投資超 16 億元……以智算中心為代表的數碼新基建正加快建設落地。
國家統計局 7 月 15 日釋出的數據顯示,截至 5 月底,全國新建 5G 基站 46 萬個;規劃具有高效能電腦集群的智算中心達 10 余個,智能算力占算力總規模比重超過 30%。
據中國 IDC 圈不完全統計,截止 2024 年 5 月 23 日,中國大陸共有智算中心 283 座,已覆蓋中國大陸所有省、自治區和直轄市。其中有投資額統計的智算中心專案 140 座,總投資額達到 4364.34 億元。有規劃算力規模統計的智算中心專案 177 座,總算力規模達到 36.93 萬 PFlops。
這些「智算中心」標準不一、規模不同,算力規模一般在 50P、100P、500P、1000P,有的甚至達到 12000P 以上,雖然 AI 浪潮給智算中心帶來了廣闊的發展前景,但供需錯配、價格昂貴、重復建設等仍然是中國算力建設面臨的難題。
與此同時,多地也紛紛出台專項規劃,明確未來幾年建設目標,並在技術、套用、資金等方面完善支持舉措。例如,江蘇釋出省級算力基礎設施發展專項規劃,提出到 2030 年全省在用總算力超過 50EFLOPS(EFLOPS 是指每秒百億億次浮點運算次數),智能算力占比超過 45%;甘肅提出對算力網絡新型基礎設施在用地、市政配套設施建設、人才引進、資金等方面給予政策支持。
「人工智能大模型等套用爆發式發展帶動了智能算力需求激增。」國家資訊中心資訊化和產業發展部主任單誌廣表示,智能計算發展迅速,已經成為中國算力結構中增速最快的類別,其中大模型是智能算力的最大需求方,需求占比近六成。預計到 2027 年,中國智能算力規模年度復合增長率達 33.9%。











