
本文 專註 於 Python 字串總結,試圖一文 全面 講解 Python 常用 字串操作 ,並且能夠一遍就能看懂和學會。
文本目標
零散 的 Python 字串知識是 沒有力量的 。文本的目標你腦子裏面長出一顆 Python 字串的樹的 種子 ,讓它具有成長的基礎內容。當然發芽成長還是自己。
學習方式推薦

推薦使用學習方式使用 jupyter notebook ,為什麽呢?很簡單 jupyter notebook 可以分段執行,也可以分類。當然你可以使用自己的
pip install jupyterlabjupyter lab # 在 web 環境中連結

當然你也可以在 vscode 使用外掛程式支持 jupyter notebook,在你 vscode 等熟悉的編程器中學習和使用。
定義字串的方式
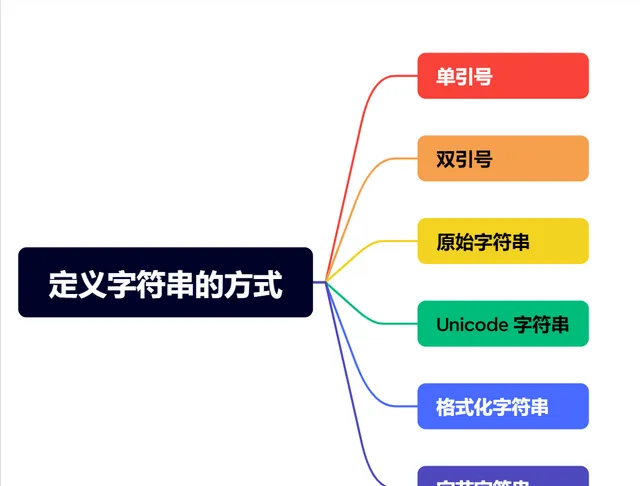
# 1. 單引號字串str1 = '這是一個字串'# 2. 雙引號字串str2 = "這是另一個字串"# 3. 三引號字串(可以跨多行)str3 = '''這是一個多行字串可以換行'''# 4. 原始字串(反斜杠不轉義)str4 = r'這是一個原始字串,包含反斜杠: \n \t'# 5. Unicode 字串(Python 3 中,字串預設是 Unicode)str5 = u'這是一個Unicode字串'# 6. 格式化字串(插入變量或運算式的值)name = 'Alice'age = 30str6 = f'{name}的年齡是{age}歲'# 7. 字節字串(用於儲存字節數據)str7 = b'hello world'
字串的基本操作
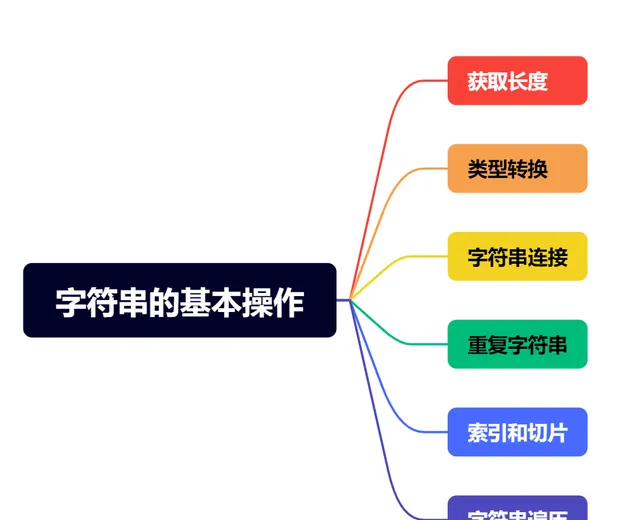
# 原始字串定義str1 = "Hello"str2 = "World"# 1. 獲取長度:len()length = len(str1)# 2. 類別轉換:str()num = 123str_num = str(num)# 3. 字串連線:+str3 = str1 + " " + str2# 4. 重復字串:*str4 = str1 * 3# 5. 索引和切片: str[i] 和 [str[i:j]]first_char = str1[0] # 索引獲取第一個字元slice_str = str1[1:4] # 切片獲取子字串,從索引 1 到 3(不包含 4)# 6. 字串遍歷: for-inprint("遍歷字串結果:")for char in str1: print(char, end=' ')
字串尋找
# 原始字串定義text = "Hello, welcome to the world of Python. Python is great!"# 尋找子字串:find()substring = "Python"index = text.find(substring)# 子串計數:count() 方法返回子字串在字串中出現的次數count = text.count(substring)# 檢查開頭和結尾:startswith() 方法檢查字串是否以指定的子字串開始starts = text.startswith("Hello")# endswith() 方法檢查字串是否以指定的子字串結束ends = text.endswith("great!")# endswith() 方法可以接受一個元組,檢查字串是否以元組中的任意子字串結尾ends_any = text.endswith(("Python", "great!"))
字串修改

# 原始字串定義text = " Hello, welcome to the world of Python. Python is great! "# 1. 大小寫轉換:lower() 和 upper()lower_text = text.lower() # 將字串轉換為小寫upper_text = text.upper() # 將字串轉換為大寫# 2. 替換:replace()replaced_text = text.replace("Python", "Java")# 3. 去空格:strip(), lstrip(), rstrip()stripped_text = text.strip() # 去除兩端空格lstripped_text = text.lstrip() # 去除左側空格rstripped_text = text.rstrip() # 去除右側空格# 4. 字串拆分:split()words = text.split() # 預設按空白字元拆分# 5. 字串連線:join()separator = ", "joined_text = separator.join(words) # 用 ', ' 連線列表中的字串
格式化字串:

name = "Alice"age = 30# 使用 % 占位符進行格式化formatted_string = "名字: %s, 年齡: %d" % (name, age)formatted_string = "名字: {}, 年齡: {}".format(name, age)formatted_string_index = "名字: {0}, 年齡: {1}".format(name, age)formatted_string_keywords = "名字: {name}, 年齡: {age}".format(name=name, age=age)# 使用 f-string 進行格式化formatted_string = f"名字: {name}, 年齡: {age}"# 支持運算式formatted_string_expr = f"名字: {name.upper()}, 年齡: {age + 5}"# 支持格式化規範formatted_string_float = f"圓周率: {3.14159:.2f}"
字串檢查
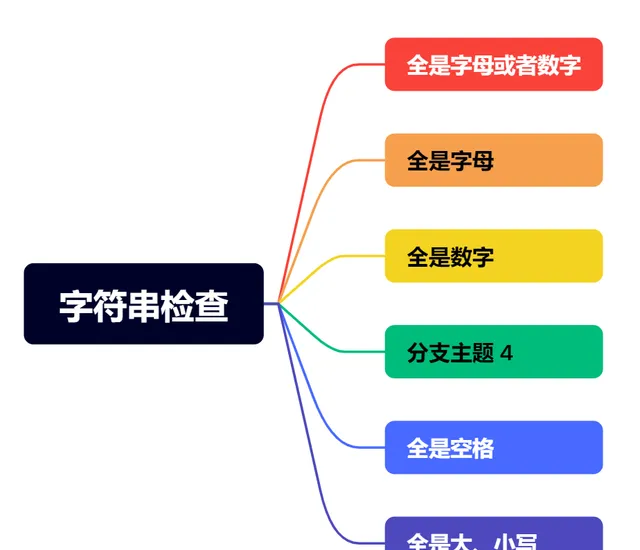
text = " Hello123 "print(f"'{text}' 是否全是字母或數碼: {text.isalnum()}") # 輸出: Falseprint(f"'{text}' 是否全是字母: {text.isalpha()}") # 輸出: Falseprint(f"'{text}' 是否全是數碼: {text.isdigit()}") # 輸出: Falseprint(f"'{text}' 是否全是空格: {text.isspace()}") # 輸出: Falseprint(f"'{text}' 是否全是小寫字母: {text.islower()}") # 輸出: Falseprint(f"'{text}' 是否全是大寫字母: {text.isupper()}") # 輸出: False
正則 re 模組

import re# 正規表式模式pattern = r'\d+' # 匹配一個或多個數碼# 1. 編譯正規表式:compile()compiled_pattern = re.compile(pattern)# 2. 尋找:search()text = "The number is 12345."match_search = compiled_pattern.search(text)# 3. 匹配:match()text2 = "12345 is the number."match_match = compiled_pattern.match(text2)# 4. 匹配成列表:findall()text3 = "The numbers are 123 and 456."matches_findall = compiled_pattern.findall(text3)# 5. 尋找叠代:finditer()matches_finditer = compiled_pattern.finditer(text3)for match in matches_finditer: print(f"位置: {match.start()}, 內容: {match.group()}")# 6. 替換:sub()text4 = "Replace 123 and 456."replaced_text = compiled_pattern.sub('NUMBER', text4)# 7. 拆分:split()text5 = "Split 123 and 456."split_text = compiled_pattern.split(text5)
常用的類別庫

import stringimport textwrapimport difflibimport unicodedatafrom fuzzywuzzy import fuzzimport regeximport stringcasefrom strsimpy.jaccard import Jaccardfrom pyparsing import Word, alphas, nums, OneOrMore# 1. string 內建模組的內容和方法:print("所有字母: ", string.ascii_letters)print("所有小寫字母: ", string.ascii_lowercase)print("所有大寫字母: ", string.ascii_uppercase)print("所有數碼: ", string.digits)print("所有標點符號: ", string.punctuation)print("所有空白字元: ", string.whitespace)template = string.Template('Hello, $name!')print(template.substitute(name='Alice')) # 輸出: Hello, Alice!# 2. textwrap 模組text = "This is a long line of text that we want to wrap to a specified width for better readability."wrapped_text = textwrap.fill(text, width=40)print("textwrap.fill() 結果:")print(wrapped_text)# 3. difflib 模組text1 = "Hello World!"text2 = "Hello Python World!"diff = difflib.ndiff(text1, text2)print("difflib.ndiff() 結果:")print(''.join(diff))# 4. unicodedata 模組char = 'ñ'print(f"字元: {char}")print(f"名稱: {unicodedata.name(char)}") # 輸出: LATIN SMALL LETTER N WITH TILDEprint(f"類別: {unicodedata.category(char)}") # 輸出: Ll (Letter, lowercase)# 5. pyparsing 模組word = Word(alphas)number = Word(nums)sentence = OneOrMore(word | number)result = sentence.parseString("Hello 123 world")print("pyparsing 結果:")print(result) # 輸出: ['Hello', '123', 'world']# 6. fuzzywuzzy 模組str1 = "hello world"str2 = "hello"ratio = fuzz.ratio(str1, str2)print(f"fuzzywuzzy.ratio() 相似度: {ratio}") # 輸出: 相似度: 60# 7. regex 模組text = "The quick brown fox jumps over the lazy dog."pattern = r'\b\w{5}\b'matches = regex.findall(pattern, text)print(f"regex.findall() 匹配的單詞: {matches}") # 輸出: ['quick', 'brown', 'jumps']# 8. stringcase 模組import stringcasetext = "Hello World"print(f"stringcase.snakecase() 底線風格: {stringcase.snakecase(text)}") # 輸出: hello_worldprint(f"stringcase.uppercase() 大寫風格: {stringcase.uppercase(text)}") # 輸出: HELLO WORLDprint(f"stringcase.camelcase() 駝峰風格: {stringcase.camelcase(text)}") # 輸出: HelloWorld# 9. strsimpy 模組jaccard = Jaccard(2) # 2 表示使用2個字元組成的元組進行比較similarity = jaccard.similarity("night", "nacht")print(similarity) # 輸出: 0.14285714285714285
小結
本文系統以 圖文 的方式介紹的了 Python 字串相關內容和實際範例。熟悉一門語言我們快速的建立起知識結構,尤其是當你有多門程式語言的經驗。











