除了好多行業,人工智能還會促使能源行業轉變,給出最佳化能源系統執行和可靠性的新法子,保證技術經濟方面的優勢。
不過呢,把 AI 融入到能源部門會碰到想不到的阻礙,這些阻礙或許能讓處理 AI 融入的樂觀方式變一變。
【人工智能】
人工智能的計劃能往前追溯好幾十年呢。人工智能的歷史和 1946 年誕生的電腦「電子數碼積分器和電腦 (ENIAC)」有關系。
在 20 世紀 50 年代初,因為存取只能執行命令的那種基礎電腦既有限又費錢,Alan Turing 就對電腦器和智能的概念展開了探索。
Turning 覺得,既然人類能透過分析現有資訊和相關原因來解決問題、做出決策,那給機器提供輸入,為啥它就不能幹同樣的事兒呢?
在 1957 年至 1974 年這段時間,電腦變得更快、更便宜,能執行和儲存更多的數據,與此同時,改進機器學習演算法的這個趨勢,能被叫做 AI 努力的繁榮階段。
1980 年往後,人工智能那股子雄心壯誌推動了像機器學習、深度學習、量子計算之類相關技術的進步,引來大膽的投資,還鼓舞著年輕一代讓人工智能成為未來科技的重點。
比如說,日本的第五代電腦計劃(FGCP)屬於一個行業研究聯盟,在 1982 年到 1990 年期間,預算有 4 億美元,用在革新電腦處理、推行邏輯編程以及改進人工智能上。
在 AI 套用於學生層面成為基本的 AI 邏輯編程之前,它歷經了 40 多年才變得智能,這跟 1980 年到 2017 年左右 AI 風格的建構主義所取得的巨大成就關系緊密。圖 1 簡單概括了從文獻獲得啟發的能源領域智能計算和人工智能套用的歷史走向。
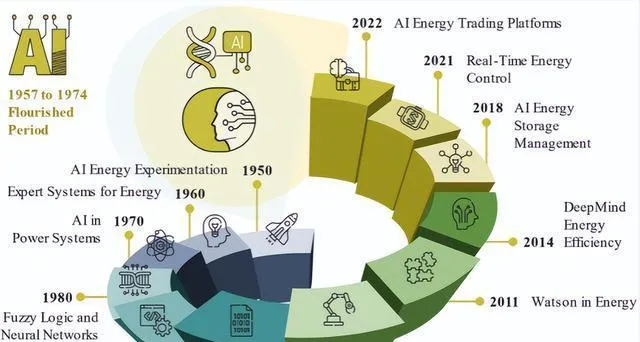
到了第五產業時代,技術會迅速發展,對包括能源行業在內的所有行業都產生影響,還會在政策制定的過程中展現新演算法。
在現代能源的格局裏,不光要跟工業 4.0 相結合從而達到工業 5.0 的標準,還冒出了「人與機器」這一概念,像協作機器人、瞄準系統,並且依靠智能技術能以靈活有彈性的方式融入社會。
機器人啥優勢都有,這讓人們害怕它會把工作搶走,還改變勞動力市場。雖說協作機器人沒法替代勞動力,不過能補上社會老齡人口的缺口。
比如說,有報道稱,到 2060 年,超過三成的歐洲人會超過 65 歲,這就讓勞動力的需求變得很高。
有訊息說,像工業 4.0+、4.5、6.0、7.0 這類流行詞用得越來越多,得留神。雖說這些術語在學術寫作和資助申請方面可能挺常見的,可它們不一定能幫著做出實際的商業決定,也不一定能解決真正的技術難題。
【人工智能在能源領域的挑戰】
在電力系統裏,機器學習和人工智能在大量可再生能源的高級監測、控制、操作與整合方面,在處理不確定性和不穩定性方面,在適應不斷變化的狀況方面,還有管理智能電網的新情況方面,都特別重要。
不過,這些新辦法還得融入遺留下來的那種利用靈活性以及最佳化的機器學習方法的基礎設施和實踐裏。
在如今這個數據大量生成與交換的綜合化世界,得有強大的基礎設施,才能從各個領域的多學科資訊交流裏找出有用的資訊。
人工智能(AI)能解決工業革命時代這種復雜又多方面的需求。從圖 2 裏對挑戰做的初步分類,可以幫著找出關鍵問題,還能按照它們跟每個類別的關聯程度,給解決方案排個先後次序,這樣就能給能源系統裏 AI 的整合制定出更有針對性、更有效的策略。
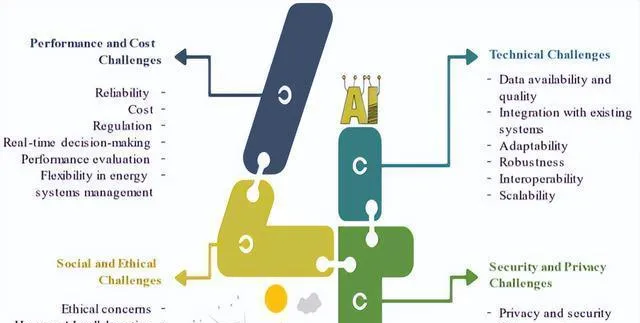
把 AI 融入能源部門這件事,有成功也有失敗,寶貴經驗表明,這主要看數據準不準、演算法選得對不對、專案管理好不好、跟現有系統能不能整合、監控評估到不到位、有沒有利益相關者支持、專業知識夠不夠、預算和資源足不足、期望是不是切合實際,還有對倫理和社會影響有沒有考慮周全。
圖 3 和圖 4 把挑戰的類別、因素,還有它們的相互關系以及變量流給視覺化呈現出來了,凸顯出了主要類別和相應子類別別之間的關聯。圖 4 裏的流向給這些變量間復雜的相互依賴關系提供了很有價值的看法。
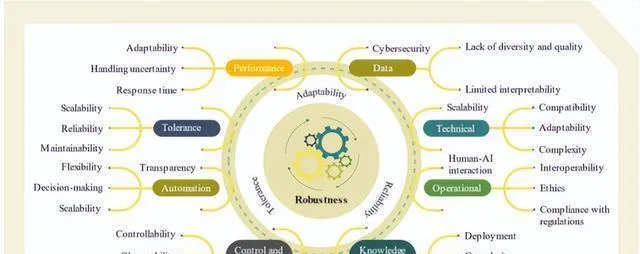

如今這世界越來越依靠智能技術去解決那些復雜的難題,在琢磨於各個行業(特別是能源行業)推行人工智能的時候,有好幾個因素是能起作用的。
在這些因素裏面,復雜性、環境以及重要性,對人工智能在能源專案裏的整體影響還有成功的部署有幫助。
復雜性主要在於把 AI 技術跟現有的基礎設施融合起來,往往得有高質素的、大量可用的數據。這會有難題,畢竟實施的人既要保留人類的專業本事,又得把人工智能用好。
中等水平的人機協作以及可解釋性,這對保證個人能明白和信賴這些技術的產出很有必要。
另外,適度的靈活性在有效的能源系統管理裏特別重要,這或許會關系到適應一直在變的需求或者整合新的能源。
雖說對人在環路和績效評估重視不夠,可這些因素還是跟打造更牢固、更靠譜的人工智能策略有關系。
通常來說,AI 施行的環境會決定各個行業能成功多少、被接受的程度咋樣。像數據的高可用性和質素、私密、安全,還有跟新的以及現有的設定相融合,這些都是得解決的重要方面。高成本和投資方面的要求,有可能給一些公用事業造成阻礙,讓可延伸性變成了重要的問題。
關鍵效能確保人工智能系統得以負責、有效地推行,得把私密和安全性、可解釋性、可靠性、監管以及可延伸性放在高位優先考慮。這些方面能保證人工智能的辦法在技術上靠譜,也符合道德和法律的標準。
環路、倫理問題、網絡安全以及透明度這些方面也挺重要的,被看成是中等優先的事兒,畢竟它們能幫助建立起對人工智能系統的信任和信心。
人機協作、數據的可用性和質素、跟現有系統的整合、成本與投資,還有績效評估,這些被看成是低優先級的因素,不過它們還是能透過最佳化能源系統的運作,推動人工智能對社會產生整體影響。
復雜性、環境以及關鍵性這三者的關系,給弄明白在各個行業推行人工智能系統時面臨的挑戰和機遇,提供了很有價值的看法。
把這些因素處理好,能保證成功用上 AI 技術,還能最大程度發揮它的好處,把潛在風險降到最低。
想想這些因素會對人工智能戰略的制定和部署產生啥影響,利益相關者就能更好地搞清楚人工智能在自己那塊領域的作用,在采用和部署它的時候能做出更明白的決定。
搞明白底層模型,安排好合適的工具和技術,對保證機器學習應用程式有效果特別重要。數據質素在得到準確靠譜的結果上起著關鍵作用。
憑借高質素的數據集能夠最大程度降低錯誤與偏差,還能提升機器學習演算法的整體表現。
要不想有不好的結果,從業者得好好琢磨模型、技術還有資料來源咋選,還得緊盯著實施的過程,保證機器學習系統能像預想的那樣運轉。
就算最佳化凸函數,也會有這些難題,導致很難找到深度模型。假設得出的結果表明了限制演算法效能存在困難,不過它們不一定能在使用神經網絡的實際運用中管用。目標並非是找出函數的準確最小值,而是把它的值降低到能夠得到合理的泛化誤差限制就行。
【AI整合要求和難題】
人工智能(AI)屬於電腦科學的一個範疇,在 1950 年代就有了,它主要是研究智能方面的情況,透過電腦模擬人類的思考過程,靠電腦的邏輯運算來實作對智能的科學認識,進而能更好地理解和展現人類的大腦思維。
計算智能出現在二十世紀,能讓電腦模仿人類的學習以及決策能力,變成了當下生活中改變遊戲規則的存在。不考慮模型的準確性、依賴性之類的因素,去做數值建模和分析。
用能源、火用、環境和經濟的數值概念對混合廢物能源系統進行了分析,目的是減少排放汙染,讓電力生產成本實作平衡。
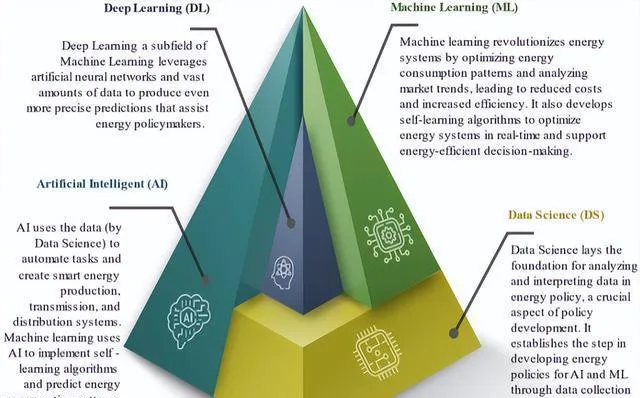
圖 5 展現出了一個新的規劃,這意味著 DS 給數據的分析及解釋打下了基礎,AI 和 ML 則利用這些數據去告知和引導不同層級且相互關聯、有所重疊的能源政策決策。
數據科學(DS)能做的事兒可多啦,像分類、回歸、關聯分析、聚類、異常檢測、推薦引擎、特征選擇、時間序列預測、深度學習、文本挖掘啥的。而 AI 和 ML 只在特定的需求場景裏有用。
要概括這三個相互依賴關系緊密的層次,目前還是個難題。
數據科學靠著大計劃裏的數據收集與分析,給人工智能和機器學習制定能源政策邁出了第一步。
AI 依靠這些數據能自動完成任務,還能構建智能的能源生產、傳輸及分配系統,ML 則借助 AI 去落實自學習的演算法,並且預測能源消耗的模式、市場的走向以及系統的效能。
AI 跟 ML 是基於 DS 的,它們靠數據去辨識模式、做預測還有設想藍圖,這樣能讓決策者在國家和區域的技術以及迴圈經濟的基礎上,給系統設定做出明智的決定。
把機器學習放進能源政策裏得有準確的數據驅動模型跟合適的數據集才行。把政策流程拆分成能管理的部份,這樣能把數據分析跟數據集建立做得更好。
智能電網的數據又多又多變,這給 AI 演算法帶來了難題,得把魯棒性、適應力還有線上處理改進一下。數據驅動的模型不用系統動力學的先驗知識就能認出歷史數據裏的模式,可基於參數的模型得依靠數學方程式和系統方面的知識。
數據驅動模型能自動學習模式,有高精度的可能,還能隨著時間靠新數據來改進。但它也有不足,像對過度擬合很敏感、對數據質素敏感,而且解釋起來困難。
數據對於機器學習和分析來說特別重要,要經過好多處理環節來保證質素和能用,不過雖說大數據在學術和工業領域都挺火,可「大數據」這個術語在概念上還是挺模糊的。
數據處理的階段裏有數據收集這一項,這得從好多來源去收集原始數據,像網絡抓取、API、調查還有數據庫啥的。
數據清理能把不一致、重復的東西消除掉,還能處理缺失值,讓數據質素變高。數據標記呢,是用相關的標簽給監督學習任務去註釋或者標記數據。數據擴充則是創造新的或者修改數據例項,把數據集擴大、變得多樣,提升模型的效能。
數據編碼能把數據弄成機器能讀的那種格式,像 one-hot encoding 和 label encoding 啥的。特征提取就是從原始數據裏找出本質特征來展現和概括它。特征縮放是把數據特征給標準化、規範化,好保證對模型訓練有一樣的作用。特征工程是創造新特征或者進行轉換,讓數據集的預測能力變強。
數據插補就是拿基於現有的數據得出的估計值去把缺失值填上,數據整合是把來自多個來源的數據集整合到一塊兒,弄出一個統一的數據集。
降維能讓特征的數量變少,不過會把最有關聯的資訊留住。數據匿名化借助數據遮蔽、泛化這類技術來護住數據集中的敏感資訊。數據拆分把數據集分成訓練、驗證和測試這幾個子集,用來估量模型的效能。數據洗牌就是重新把數據樣本的順序打亂,免得模型訓練時有偏差。
數據版本控制能追蹤變化,還能維護數據集的過往記錄,為的是達到可重復性和審計的目標。
數據儲存負責管理各種形式的儲存,像雲端儲存、本地儲存以及數據庫。數據驗證透過統計測試、視覺化還有異常值檢測來保證數據的正確和一致。最後,數據監控留意效能指標、進行即時監控以及通知相關的數據管道,從而維持數據的質素與完整性。
由於收集、探索和分析大數據的需求持續上升,AI 被用來優先處理這些大數據集和實作自動化操作,在各種平台的眾多套用裏都能用。充足的能源供應和需求規劃跟分析大量過往數據有關,這樣才能有效滿足當下需求,並最好地預測未來的增長模式。
把領域專業知識(像技術、經濟、制度、社會之類的)結合起來,靠著被叫做數據科學的技術創新(比如編碼、處理、操作等)來支持最佳化效率、把損失降到最小,從而平衡供需以及科學方法論(像數學、統計、演算法等),這是人工智能平台的核心所在。
人工智能在能源領域的套用能協調系統最佳化、自動化系統以及能源政策目標,因為從套用角度來看,它們的目標緊密交叉,這是個共同點。憑借這個,政策制定者就能依據單一目的的新興雙重最佳化因素來制定綜合路線圖,從而把人工智能用得最好。
要解決人工智能在能源系統套用裏的那些局限性,得用一種協調的辦法,依照行動方案把政策制定中的能源管理實施給最佳化好。

其次是搞人力資源能力建設,讓人能跟協作機器人還有類人機器人合作,達成組織的目標。
現在能即時存取不同層級利益相關者的資訊,私密和倫理方面變得比過去更重要了,可這在之前的能源政策裏沒被好好處理。
所以,它提醒政策制定者,在政策從制定到更新的整個過程中,得嚴格把這個問題考慮進去。比如說,用無人機給輸電路線或者風力渦輪機做預防性或者糾正性的維護。
人工智能有希望憑借給出創新的解決辦法,把系統執行給最佳化了,讓可靠性提升,還能保證技術經濟方面的優勢,進而把能源行業徹底改變。
這些優勢能讓效率變高,把需求平衡和預測給最佳化好,憑借最佳化後的預防性、糾正性維護讓系統更穩定、更可靠,實作經濟的高收益執行,做好適當的機組承諾,還能對供需進行控制從而達到市場最佳化。
簡化決策流程,減少營運以及資本方面的支出,能幫助打造出成本效益更高的能源部門。最後,憑借數據驅動的解決辦法保證網絡安全得到增強,讓能源系統在經濟上能行得通、能被使用並且可持續。
不過呢,人工智能跟能源領域成功結合的過程中,有一些想不到的阻礙,這或許會讓人對采用人工智能不再那麽樂觀。
參考文章:Danish, M.S.S. 【人工智能在能源領域:克服意外的阻礙】。AI 2023 年,第 4 期,406 - 425 頁。











