機器人是出色的人類模仿者,但大多離不開人類的幫助,比如一些預設的編程。
尤其是家用機器人,在面對復雜的家務勞動時,如果「大腦」中沒有足夠多的常識,就很難滿足人類家庭的日常需求。
如今,在大型語言模型(LLMs)的驅動下,家用機器人已經可以掌握「常識性知識」,能夠在沒有人類的幫助下進行自我糾正,出色地完成復雜的家務勞動。
相關研究論文以「 Grounding Language Plans in Demonstrations Through Counterfactual Perturbations 」為題,以會議論文的形式已發表在人工智能(AI)頂會 ICLR 2024 上。

麻省理工學院(MIT)電氣工程和電腦科學系博士 Yanwei Wang 為該研究論文的通訊作者。

他表示,模仿學習是實作家用機器人的主流方法。但是,如果機器人盲目地模仿人類的運動軌跡,微小的錯誤就會不斷累積,最終導致執行過程中的其他錯誤。「有了我們的方法,機器人就能自我糾正執行錯誤,提高整體任務的成功率。」
讓機器人掌握一點家務常識
從擦拭溢位物到端上食物,機器人正在學習如何完成越來越復雜的家務勞動。
實際上,許多家庭機器人都是透過模仿人類行為來學習的,它們被編程為復制人類指導它們完成的動作。
然而,由於以往的機器人不具備常識,除非人類工程師透過編程讓它們適應每一個可能的碰撞和輕推,否則它們並不一定知道如何處理這些情況,就會從頭開始執行任務。
或許,透過加入一些「常識性知識」,機器人可以在面對將它們推離訓練軌域的情況時有所準備。
據論文描述,Yanwei 等人透過一個簡單的日常任務驗證了他們提出的方法的有效性。該任務看似非常簡單,即從一個碗中舀出彈珠,然後倒入另一個碗中。

然而,在先前的方法中,為了讓機器人完成這項任務,工程師往往會讓機器人在一個流體軌跡上完成「舀」和「倒」的動作,並可能多次重復,讓機器人模仿人類的一些示範動作。
問題是,雖然人類可能會一次性演示一項任務,但這項任務取決於一系列子任務或軌跡。例如,機器人必須先將手伸進碗裏,然後才能舀水,在移動到空碗之前,它必須先舀起彈珠。如果機器人在這些子任務中的任何一個過程中受到推擠或犯錯,那麽它唯一的辦法就是停下來,從頭開始。
除非人類工程師明確標出每一個子任務,並為機器人編程或收集新的演示,從而讓機器人從上述失敗中恢復過來,在瞬間進行自我糾正。
「這種程度的規劃非常繁瑣,」 Yanwei 說。
於是,在這項研究中,Yanwei 及其團隊將機器人的運動數據與大型語言模型的「常識性知識」聯系了起來。
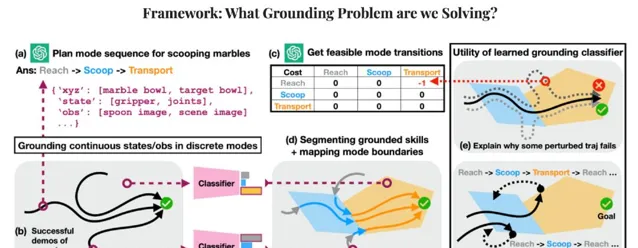
他們使機器人能夠從邏輯上將許多給定的家務任務解析為子任務,並對子任務中的幹擾進行調整。基於此,機器人就能繼續前進,而不必返回並從頭開始執行任務。而且重要的是,人類工程師也不必為每一個可能出現的故障編寫詳細的修復程式。
據介紹,這些深度學習模型可以處理大量的文本庫,並以此建立單詞、句子和段落之間的聯系。透過這些聯系,大型語言模型可以根據它所學到的上一個詞後面可能出現的詞的類別生成新的句子。
另外,除了句子和段落之外,大型語言模型還能根據提示生成特定任務所涉及的子任務的邏輯列表。例如,如果被要求列出將彈珠從一個碗中舀到另一個碗中的動作,模型就可能會產生一系列動詞,如「夠」、「舀」、「運」和「倒」。
「大型語言模型可以使用自然語言告訴機器人如何完成任務的每一步。人類的連續演示就是這些步驟在物理空間中的體現,」 Yanwei 說,「我們希望將兩者聯系起來,這樣機器人就能自動知道自己處於任務的哪個階段,並能自行重新規劃和恢復。」
Yanwei 表示,他們的演算法現在可以將遠端作業系統收集的數據轉化為強大的機器人行為,盡管有外部幹擾,機器人仍能完成復雜的任務。
不足與展望
盡管這一方法能夠使得機器人在沒有人類的幫助下進行自我糾正,從而完成復雜的家務勞動,但也存在一定的局限性。
例如,雖然他們的方法不需要大量的人類演示,但它需要大量的試錯和具有重設能力的環境,以便收集軌跡的任務成功標簽。不過,研究團隊表示,這種數據效率低下的問題可以透過主動學習來解決。











