作者:謝帆愷 | 中國科學院大學、中國科學院物理研究所博士生稽核:劉渺 | 中國科學院物理研究所研究員
在人工智能領域,Transformer架構、大模型是當下最激動人心的話題之一。它們不僅推動了技術的極限,還重新定義了我們與機器互動的方式。本文將帶您從科普的視角了解這些開啟智能新篇章的概念。
Transformer模型最初由Google的研究人員在2017年提出,它是一種基於自註意力機制的深度學習模型,用於處理序列數據。在此之前,序列數據處理主要依賴於迴圈神經網絡(RNN)和長短期記憶網絡(LSTM),但這些模型在長距離依賴和平行計算方面存在限制。
圖片來源:網絡
Transformer的自註意力機制允許模型在處理序列的任何元素時,同時考慮序列中的所有其他元素並給出不同元素的重要程度。想象一下,你是一位導演,正在一部舞台劇中指導一群演員。在任何給定的場景中,你都需要決定哪個演員應該成為觀眾註意的焦點。這時,你會用一束聚光燈照亮你想要突出的演員,而其他演員雖然仍在舞台上,但會處在較暗的背景中。註意力機制在人工智能中的作用就像這個「聚光燈」,它幫助模型確定在處理大量數據時應該「照亮」哪些資訊。
在自然語言處理的語境中,比如在閱讀一篇文章時,模型需要理解每個單詞的意義及其在文中的重要性。不是所有的單詞都同等重要,有些單詞對於理解句子的意思至關重要,而有些則不那麽重要。註意力機制允許模型動態地調整它對不同單詞的「聚焦」程度,就像導演控制聚光燈一樣,讓某些單詞在模型的「視野」中更加突出。

圖片來源:網絡
在具體實作上,每個單詞(或數據點)都會被分配一個權重,這個權重代表了它在當前上下文中的重要性。模型透過這些權重來決定在生成輸出時應該「照亮」哪些單詞。比如從英語轉譯到中文,模型會在轉譯每個中文詞時,重新計算這個分數,以確保聚光燈始終對準最相關的英文詞。這種動態調整允許模型即使在面對很長的輸入序列時也不會遺失重要資訊。這就好比一個轉譯員在轉譯一句長句子時,她會時不時回頭檢視原文的某些部份,以確保轉譯的準確性和連貫性。
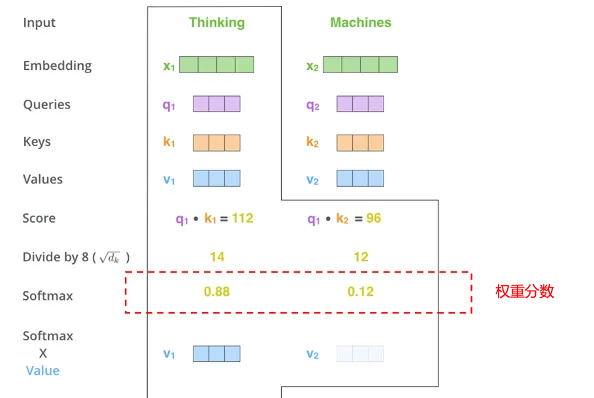
圖片來源:網絡
透過註意力機制,模型能夠更好地處理復雜的模式和長距離的依賴關系,這種能力極大地提高了模型在語言理解、情感分析、語音辨識等復雜任務中的表現,並且不斷推動著人工智能技術的發展和創新。
Transformer又可以分為Encoder(編碼器)和Decoder(解碼器)。其中,Encoder將一段話或者一張圖利用註意力機制轉換成向量的形式,這個向量包含了這段話或圖的所有資訊,AI模型便可用這個向量來進行分類或者回歸的任務。
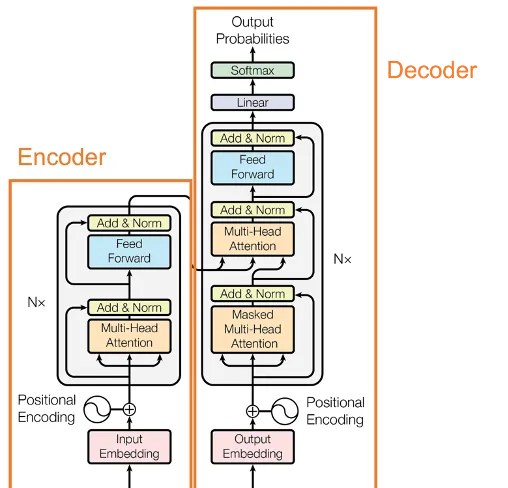
圖片來源:網絡
而Decoder則是根據前面的句子選擇概率最高的詞輸出,直到形成完整的段落。在生成詞的過程中,往往會透過采樣的方式,賦予模型一定的隨機性,因此每次生成的句子都有所不同。
圖片來源:網絡
目前的大模型主要采用Transformer的Decoder形式,這種架構具有模型復雜度低、上下文理解能力強、語言能力強和預訓練效率高等優點。想象你要講一個故事,作為一個好的故事講述者,你不僅需要記住你已經說了什麽(以保持故事的連貫性),還需要根據已有的情節來創造新的內容。這就像一個Decoder,它需要記住之前的所有內容來生成下一個詞。
而Encoder則像是一個傾聽者,它專註於理解你的故事,並將它轉換成他們心中的一個緊湊的概念或感覺。如果你的目標是創作新的故事內容,那麽僅僅做一個好的傾聽者是不夠的,你還需要能夠講述故事的能力,這正是Decoder所擅長的。
圖片來源:網絡
大模型的參數量主要是透過對Transformer的Decoder模組進行堆疊而上升的。比如開源大語言模型LLAMA-2就由32個Transformer Decoder進行堆疊,參數量可達幾十億甚至幾百億。OpenAI的GPT-4作為領先全球的大模型,甚至達到了1.76萬億個參數。巨大的參數量使大模型在具備超強的表達能力的同時也消耗著大量的資源,GPT-4在訓練過程中,總計使用約3125台機器(25000張A100)進行訓練,訓練集用到了13萬億個Token(Token可以是一個單詞、一個標點符號、一個數碼、一個符號等),訓練一次的成本需要6300萬美元。GPT-4的日耗電達50萬度,相當於美國家庭每天用電量的1.7萬多倍,能源消耗預計產生了12456至14994噸的二氧化碳排(妥妥的能源巨獸)。由於AI對電力需求飆升,能源賽道同樣將迎來新一輪機會。

大模型的強大不僅僅得益於它的巨大參數量,更得益於它的訓練策略。為了使大模型具有人類決策的傾向性,在初始訓練的基礎上,加入了基於人類反饋的強化學習(RLHF)。這個過程就像你正在教一個孩子如何玩一個新的電子遊戲。你不僅會給他規則上的指導,還會坐在旁邊,觀察他玩遊戲的方式,並在關鍵時刻給予建議或者示範如何透過難關。基於人類反饋的強化學習在大模型中的套用,就有點像這樣一個過程。
在這個比喻中,孩子就像一個強化學習的智能體,而電子遊戲就像是它需要學習的任務環境。在傳統的強化學習中,智能體透過不斷嘗試(即「試錯」)來學習怎樣完成任務,就像孩子自己摸索遊戲規則一樣。它會根據遊戲的得分(獎勵)來判斷自己的表現。但這個過程可能既低效又費時,因為智能體可能會陷入不必要的錯誤之中。
RLHF的方法就好比是在孩子旁邊加了一個指導者——也就是人類。這個指導者不直接控制遊戲,而是透過各種方式給予反饋:
1. 示範:就像大人親自玩遊戲給孩子看一樣,人類可以透過執行任務來給智能體示範正確的行為方式。
2. 評價:當孩子完成一次嘗試後,大人可以告訴他這樣做是好是壞,這就像是人類對智能體嘗試的結果給出正面或負面的評價。
3. 指導:在孩子做出選擇時,大人可以給出提示或建議,類似地,人類也可以在智能體做決策時給出指導性的建議。
4. 修改獎勵:如果孩子完成了一個特別困難的動作或關卡,大人可能會額外獎勵他,這就像是人類根據智能體的表現調整獎勵函數,以強化某些行為。
透過這些人類的反饋,智能體可以更快地學習到復雜的行為策略,尤其是在那些難以直接編寫精確獎勵函數的任務中。這種方法特別適用於大模型,因為它們通常需要大量的數據和復雜的行為策略來處理高級任務。
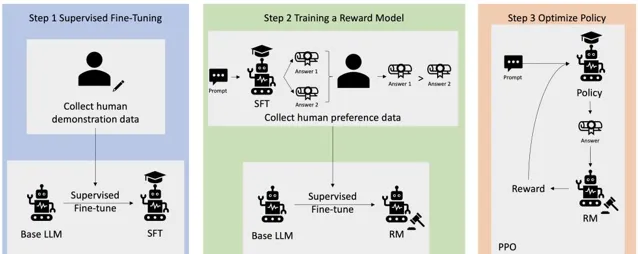
與此同時,大模型仍在不斷發展中,然而目前的大模型都是在Transformer的基礎上進行開發,AI行業仿佛被困在了六七年前的原型上。不過,AI的發展日新月異,說不定馬上就有更好的模型問世於世間。

最後,介紹一個同時讓多個大模型為我們「打工」的工具OpenRouter,可以讓八十多種大模型同時對同一問題進行回答(賽博養蠱)。
參考文獻
[1] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 「Attention Is All You Need.」 arXiv, August 1, 2023. http://arxiv.org/abs/1706.03762.
[2] OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al. 「GPT-4 Technical Report.」 arXiv, March 4, 2024. http://arxiv.org/abs/2303.08774.
[3] Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, et al. 「Llama 2: Open Foundation and Fine-Tuned Chat Models.」 arXiv, July 19, 2023. http://arxiv.org/abs/2307.09288.

編輯:wnkwef
近期熱門文章Top10
↓ 點選標題即可檢視 ↓
1.老虎加速朝我跑來的情況下我也對著它沖刺,它會不會楞一下?| No.395
2.龍年吃太飽 | 憑什麽大學生和年貨不能呆在一個屋子?年貨就一點錯沒有嗎?
3.【繁花】中火燒絲光棉真的不怕火燒?
4.人類建築高度的極限是多少?
5.做餃子餡時要朝同一個方向攪拌嗎?為什麽?| No.396
6.煙花真的能綻放出愛心形嗎?怎麽感覺從來沒見過(文末領取物理所專屬新年紅包封面!)
7.尖叫土撥鼠是假的,吃它摸它你就倒黴是真的
8.滑鼠裏的小球,是什麽時候消失的?
9.啄木鳥每天這樣duangduang瘋狂用頭撞樹,為啥不會腦震蕩?
10.魚睡覺時會被水沖走嗎?沙雕的知識增加了!!
點此檢視以往全部熱門文章












