克雷西 發自 凹非寺
量子位 | 公眾號 QbitAI
高斯潑濺模型訓練的記憶體瓶頸,終於被謝賽寧團隊和NYU系統實驗室打破!
透過設計並列策略,團隊推出了高斯潑濺模型的多卡訓練方案
,不必再受限於單張卡的記憶體了。
用這種方法在4張卡上訓練,可以加速3.5倍以上
;如果增加到32卡,又能有額外6.8倍的加速。

該團隊提出的是一種名為Grendel
的分布式訓練系統,第一作者是清華姚班校友趙和旭。
透過多卡訓練,不僅速度更快了,研究團隊還突破了大場景、高分辨率環境下的記憶體局限,生成了更多高斯,3D結果質素也更高了。
為了體現這個成果是多麽的鵝妹子嚶,謝賽寧本人發了這樣一個表情包:
(大哭):不!你不能擴大3D高斯潑濺的規模,不管是場景、分辨率還是批大小,這消耗的算力和記憶體實在太高了
GPU:我就笑笑不說話

還有網友調侃說,看來老黃的股票又要漲了。

又快又好的3D生成
多卡並列的方式,突破了單卡的算力和記憶體的限制
,讓Grendel可以處理極具挑戰性的大場景(更多高斯粒子數量)渲染任務。

如在Rubble(4K分辨率)和MatrixCity(1080p分辨率)這兩個大型復雜場景中,Grendel使用多達4000萬和2400萬個高斯粒子,生成了高保真的渲染結果。

在鏡頭不斷拉近的動態過程當中,也能看出Grendel生成結果的細致性和連貫性。
從數據上看,在Mip360和TT&DB數據集上,4卡批次訓練後的渲染質素(PSNR)與單卡相比也幾乎沒失真失,進一步驗證了Grendel的多卡並列在不同場景上的有效性。
在保證質素的基礎上,Grendel還在這兩個數據集上實作了3-4倍的速度提升
。
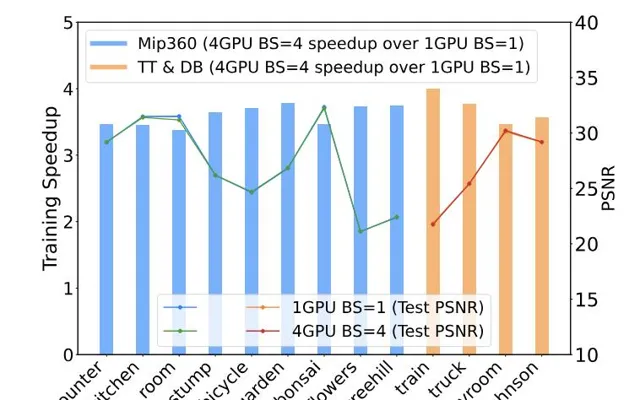
特別是在4K場景
中,單卡訓練不僅速度慢,還容易出現記憶體不足,所以使用Grendel在多卡上進行並列訓練不僅帶來量的改變,也帶來了質的突破。
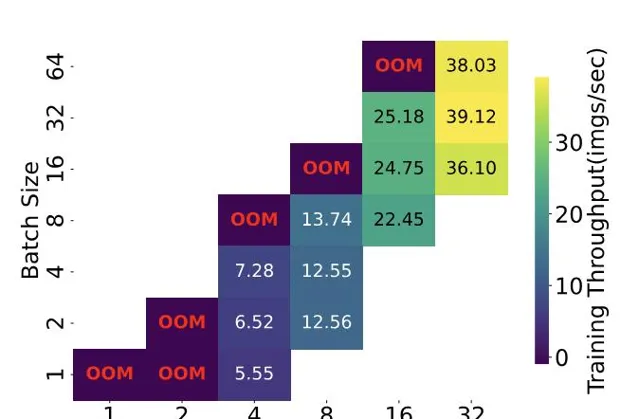
另外,透過支持更大的批次(batch size)和動態負載均衡,Grendel可以更充分地利用多GPU資源,避免計算力的浪費。
例如在Mip-NeRF360數據集上,Grendel透過增加批次和動態均衡負載,可以將4卡並列的加速比從2倍提高到近4倍。

那麽, Grendel究竟是如何實作的呢?
將高斯潑濺過程拆解
在開始介紹Grendel的原理之前,先來解答這樣一個問題:
單張卡不夠用,用多卡似乎是很容易想到的思路,為什麽以前沒見到有多卡方案呢?
這就涉及到了高斯潑濺模型獨特的計算方式——高斯潑濺分為多個不同階段,每個階段的並列粒度不同
,需要進行切換。
這與大多數神經網絡模型的單一粒度並列方式大相徑庭,甚至高斯潑濺根本沒用到任何神經網絡。
這就導致了現有的針對神經網絡訓練的多卡並列方案(如數據並列、模型並列等),難以直接套用於3D高斯潑濺。
另外,在高斯潑濺模型的訓練過程中,不同粒度的過程之間需要進行大量的數據通訊,加大了並列方案的難度。

這也正是Grendel的設計當中需要解決的問題。
首先,Grendel將3D高斯潑濺的訓練過程劃分為三個主要階段——高斯變換(Gaussian transformation)、渲染(rendering)和損失計算(loss computation)。
針對這三個階段Grendel采用混合粒度的並列策略,在不同的訓練階段使用不同的並列粒度。
高斯變換
階段采用高斯粒子級(Gaussian-wise)並列,將高斯粒子均勻分布到各個GPU節點;
渲染和損失計算
階段采用像素級(pixel-wise)並列,將影像分割成連續的像素塊,分配到各個GPU節點。
在高斯變換和渲染階段中間,Grendel透過稀疏的全對全通訊,將每個GPU節點上的高斯粒子傳輸到需要它們進行渲染的GPU節點。
由於每個像素塊只依賴於其覆蓋範圍內的高斯粒子子集,Grendel利用空間局部性,只傳輸相關的粒子,從而減少了通訊量。

完成損失計算後,在每個GPU節點上,系統會根據損失函數計算渲染管線各個參數的梯度,並透過反向傳播回傳給高斯粒子的各個內容參數。
之後,系統將各GPU計算出的梯度進行聚合,得到批次數據的總梯度,並據此更新高斯粒子的內容參數。
接著就是重復從高斯變換到參數更新的步驟,直到模型收斂或達到預設的訓練輪數。
另外,為了處理渲染階段的負載不均衡問題,Grendel引入了動態負載均衡
機制:
在訓練過程中,Grendel會記錄每個像素塊的渲染時間,用於預測當前叠代的負載分布,然後動態調整像素塊到GPU節點的分配,盡量使各個節點的渲染時間接近。
為了進一步提高GPU利用率和訓練吞吐量,Grendel支持批次訓練,即在每個訓練叠代中並列處理多個輸入影像,並根據批次大小動態調整學習率,以保證訓練的穩定性和收斂性。
作者簡介
Grendel的第一作者,是紐約大學電腦博士生、清華姚班19級校友趙和旭,主要研究方向是分布式機器學習。
在清華期間,趙和旭曾在清華NLP實驗室孫茂松團隊參與研究,接受劉知遠副教授的指導。
他還曾經在Eric Xing組存取,最佳化了一個分布式機器學習中的通訊問題,論文被MLsys2023接收。
另外三名華人作者,Weng Haoyang(翁顥洋)也來自姚班;Daohan Lu來自紐約大學,是謝賽寧的博士生;還有Ang Li博士,是一名浙大校友,現在美國PNNL實驗室從事研究。
趙和旭在紐約大學的兩位導師Jinyang Li教授和Aurojit Panda助理教授,以及紐大知名學者、ResNeXt一作、DiT(Sora核心架構)共同作者謝賽寧助理教授,都參與指導了這一專案。

論文地址:
https://arxiv.org/abs/2406.18533
專案主頁:
https://daohanlu.github.io/scaling-up-3dgs/
GitHub:
https://github.com/nyu-systems/Grendel-GS











