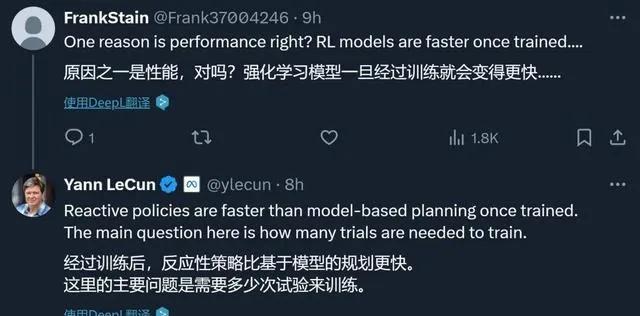
人工智能, 這個曾經只存在於科幻小說中的概念 ,如今正以驚人的速度滲透進我們生活的方方面面, 從刷臉支付到個人化推薦 ,從智能家居到自動駕駛,人工智能正在悄然改變著我們的世界,而在人工智能領域,有一位學者始終站在浪潮之巔,他就是被譽為「深度學習三巨頭」之一的YLC
LC不僅是M的首席人工智能科學家,更是摺積神經網絡之父, 他在人工智能領域的影響力不言而喻 ,而這位AI大佬的一番言論, 再次引發了業界的廣泛關註 ,他直言不諱地表示,自己並不看好強化學習這條技術路線,反而對模型預測控制(MPC)情有獨鐘,這一觀點猶如一顆石子,投入了平靜的湖面,激起了層層漣漪

圖片來源於網絡
LC的這番話
,並非電洞來風,事實上, 他一直以來都是強化學習的堅定批評者 ,在他看來, 強化學習雖然在某些領域取得了一定的成功 ,但其效率低下、泛化能力不足等缺陷,始終制約著它的進一步發展相比之下
, LC更傾向於將MPC作為人工智能發展的重要方向 ,MPC是一種基於模型的控制方法,它透過預測系統未來的行為,來選擇最優的控制策略,這種方法已經在工業控制領域套用多年,並取得了顯著的成效LC認為
,MPC具備強化學習所不具備的優勢, 例如可解釋性強、控制精度高、對模型的依賴性相對較低等 , 他相信 ,MPC將成為未來人工智能發展的重要方向
圖片來源於網絡
那麽
,LC為何對強化學習如此「不屑一顧」?MPC又有哪些過人之處, 能夠贏得這位AI大佬的青睞?要解答這些問題 ,我們還得從強化學習和MPC本身說起強化學習
,顧名思義, 就是讓機器透過不斷地試錯 ,從環境中學習到最佳的行為策略,就像我們小時候學習騎單車一樣,一開始總是會摔倒, 但透過不斷地練習 ,我們最終能夠掌握平衡,熟練地騎行強化學習在近年來取得了令人矚目的成就
, AG戰勝圍棋世界冠軍 ,OAIF在D2比賽中擊敗了職業戰隊, 這些都離不開強化學習技術的支持 ,強化學習也存在著一些難以克服的缺陷圖片來源於網絡
強化學習的樣本效率非常低
,這意味著,強化學習演算法需要大量的訓練數據才能學習到有效的策略, 以AG為例 , 它訓練了數月之久 ,才最終戰勝了人類頂尖棋手強化學習的訓練過程通常非常耗時,這是因為強化學習演算法需要不斷地與環境互動, 並根據反饋來調整策略 , 在復雜的環境中 ,這個過程可能需要數天甚至數周才能完成
強化學習的泛化能力也常常受到詬病
,這意味著, 強化學習演算法在訓練環境中學習到的策略 ,往往難以直接套用到新的環境中
圖片來源於網絡
強化學習的安全性也是一個不容忽視的問題,由於強化學習演算法的行為具有一定的隨機性,因此很難完全預測它在實際套用中會做出什麽樣的決策
正是由於這些缺陷
, LC對強化學習一直持懷疑態度 ,他認為,強化學習更像是一種「蠻力」方法,它依賴於大量的計算資源和數據,才能取得較好的效果與強化學習不同
,MPC是一種基於模型的控制方法, 它首先需要建立一個能夠描述系統行為的數學模型 ,然後根據這個模型來預測系統未來的狀態,並選擇能夠使系統達到預期目標的控制策略
圖片來源於網絡
MPC的優勢在於, 它能夠利用模型資訊來進行預測和最佳化 ,從而避免了強化學習中大量的試錯過程, MPC的控制策略通常具有較強的可解釋性 ,這使得人們更容易理解和信任它做出的決策
MPC已經在工業控制領域套用多年, 並取得了巨大的成功 , 在化工生產過程中 ,MPC可以用來控制反應溫度、壓力等關鍵參數,從而提高產品質素、降低生產成本
近年來, 隨著人工智能技術的快速發展 , MPC也開始與機器學習技術相結合 , 形成了一種新的控制方法 ,即ML-MPC,ML-MPC利用機器學習演算法來學習系統的模型,從而克服了傳統MPC方法中需要人工建立模型的局限性
圖片來源於網絡
LC對MPC的偏愛並非毫無道理, 他認為 , MPC具備強化學習所不具備的優勢 ,例如可解釋性強、控制精度高、對模型的依賴性相對較低等, 他相信 ,MPC將成為未來人工智能發展的重要方向
LC的觀點也並非沒有爭議, 一些學者認為 ,強化學習和MPC各有優劣,它們在不同的套用場景下都有各自的優勢,在遊戲、機器人控制等領域, 強化學習已經取得了令人矚目的成就;而在工業控制、自動駕駛等領域 ,MPC則更具優勢
未來
,強化學習和MPC將會如何發展?它們之間是否會融合,形成一種新的控制方法?這些問題, 還有待時間和實踐來給出答案 ,但可以肯定的是, LC的觀點 ,必將引發人們對人工智能發展方向的更深入思考圖片來源於網絡
在人工智能領域
,總有一些話題如同夜空中閃爍的星辰,吸引著無數研究者的目光, 而強化學習與模型預測控制(MPC)的「較量」 ,無疑是其中最耀眼的一顆, YLC ,這位深度學習領域的泰鬥級人物,對MPC的偏愛,更是為這場「較量」增添了一絲神秘的色彩LC對強化學習的「不看好」
, 並非一時興起 ,而是源於他對人工智能本質的深刻思考,在他看來,人類的學習並非完全依賴於海量數據的「餵養」,而是建立在對世界不斷觀察、預測和推理的基礎之上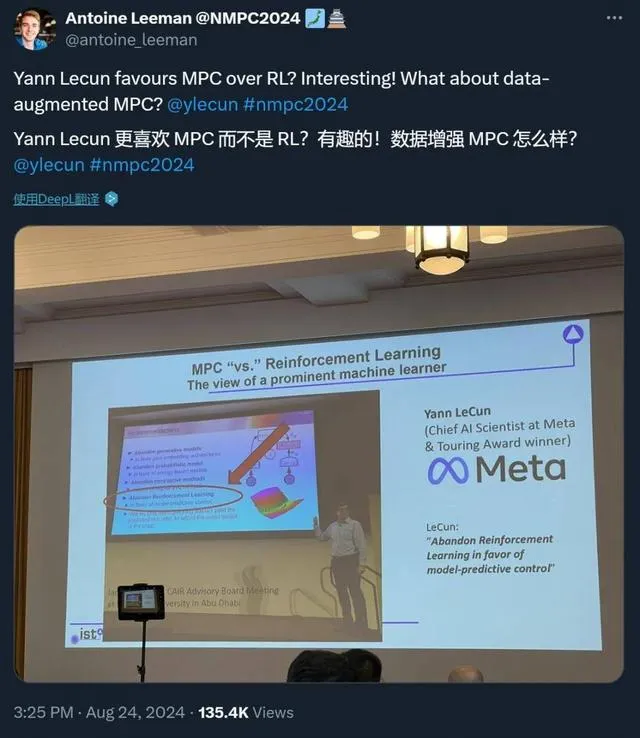
圖片來源於網絡
嬰兒不需要透過觸碰無數次滾燙的開水, 才能明白「燙」的含義;孩童也不需要無數次跌倒 ,才能學會走路, 他們總是在觀察中學習 , 在預測中行動 ,並在與世界的互動中不斷完善自身的認知模型
而強化學習
,雖然在AG、OAIF等專案中取得了令人矚目的成就,但其「試錯」的學習方式,與人類的認知方式存在著本質區別, LC認為 ,這種依賴於海量數據和計算資源的學習方式, 效率低下且泛化能力有限 ,難以真正實作通用人工智能的目標相比之下,MPC則更符合LC對人工智能的理解, MPC的核心思想是 , 透過建立一個能夠準確描述系統行為的模型 , 來預測系統未來的狀態 ,並根據預測結果選擇最優的控制策略

圖片來源於網絡
這種「先預測
,後行動」的理念, 與人類的認知方式有著異曲同工之妙 , 當我們開車行駛在道路上時 ,會根據路況、車流等資訊,預測前方車輛的運動軌跡,並據此調整自己的駕駛行為,以確保行車安全MPC的優勢在於
,它能夠利用模型資訊來進行預測和最佳化, 從而避免了強化學習中大量的試錯過程 ,MPC的控制策略通常具有較強的可解釋性,這使得人們更容易理解和信任它做出的決策MPC也並非完美無缺
, 它最大的挑戰在於 ,如何建立一個能夠準確描述現實世界復雜性的模型, 在很多情況下 ,建立一個完全準確的模型幾乎是不可能的
圖片來源於網絡
為了克服這一難題, 研究人員開始探索將機器學習與MPC相結合 , 利用機器學習演算法從數據中學習系統的模型 ,從而實作更精準、更智能的控制, 這種融合了機器學習和控制理論的新方法 ,被稱為ML-MPC
ML-MPC的出現, 為MPC的發展註入了新的活力 ,它不僅可以解決傳統MPC方法中需要人工建立模型的難題,還可以利用機器學習演算法強大的數據處理能力,處理更加復雜、更高維的控制問題
可以預見
, ML-MPC將在自動駕駛、機器人控制、智能制造等領域發揮越來越重要的作用 ,而LC對MPC的推崇,或許也將加速ML-MPC的研究和套用
圖片來源於網絡
無論是強化學習
,還是MPC, 都只是通往通用人工智能道路上的不同探索路徑 , 它們各有優劣 ,也存在著各自的局限性強化學習
,如同一個充滿好奇心的孩子,它透過不斷地試錯,來探索世界的奧秘, 它的學習方式雖然效率低下 ,但卻充滿了無限的可能性MPC
,則像一位經驗豐富的工程師,它利用模型和演算法,來預測和控制系統的行為, 它的方法雖然嚴謹可靠 ,但卻缺乏一定的靈活性
圖片來源於網絡
或許, 未來的通用人工智能 , 既需要強化學習的探索精神 ,也需要MPC的嚴謹思維,只有將兩者有機地結合起來,才能創造出真正智能的機器
在人工智能的星辰大海中
,探索永無止境,而LC對MPC的偏愛, 也提醒著我們 ,不要被現有的技術路線所束縛,要勇於探索新的可能性,才能最終抵達彼岸LC與強化學習和MPC的故事, 還在繼續 , 而人工智能的未來 ,也必將更加精彩紛呈,讓我們拭目以待共同見證人工智能的下一個奇跡!
圖片來源於網絡
您對YLC的觀點有什麽看法?歡迎在評論區留言分享您的見解!
本文旨在傳遞積極向上的價值觀,無任何不良引導意圖。如有侵權,請聯系我們及時處理。











