
2011年的iPhone 4s釋出會上,Siri以智能語音助手的身份初次亮相,成為整場釋出會上最大的亮點。
當時許多人還未曾體驗過Siri的服務,但從媒體報道中建立了一個樸實的願望:就像【鋼鐵俠】中的賈維斯一樣,每個人都將擁有自己的智能助手,可以即時溝通,幫助我們解決各種問題。
即使Siri後來「跌落神壇」,人們對於「賈維斯」的期望始終沒有抹滅。AlphaGo、智能音箱、大模型……每一次現象級的創新背後,總有人在討論:【鋼鐵俠】中的賈維斯,離我們的生活還有多遠?
2024年大概率是願望成真的一年。
7月末,OpenAI宣布向部份付費使用者開放GPT-4o的影片通話版本,能夠即時與GPT進行影片互動問答,透過網絡攝影機辨識畫面,線上解答各種問題,比如即時轉譯、解線性方程式題等。
8月29日,智譜AI官宣智譜清言APP上線「影片通話」功能,成為首個可以透過文本、音訊、影像和影片來進行多模態互動和即時推理的AI助手。目前已經向部份使用者開放,並且開放了外部申請許可權,將持續叠代並逐步放開規模。
由此產生的一個話題是:為什麽頭部的大模型廠商都在死磕「影片通話」功能,對使用者體驗有什麽影響,「人手一個賈維斯」的願望能否照進現實?
01 解鎖AI新體驗
大模型引發的新一輪技術熱潮已經持續了近兩年時間,市場上出現了形形色色的AI助手,人機互動卻被「束縛」在了對話方塊中,停留在文本輸入的階段。某些產品推出了語音對話功能,但較高的延遲導致體驗不佳,而且無法理解語調起伏、笑聲等表達的情感資訊,僅僅是用語音替代文本輸入。
我們提前一天體驗到了智譜清言APP的「影片通話」功能,在內測群裏和其他進行了簡單交流,發現了一些有趣的套用場景:
第一個場景是作業輔導。
不同於OpenAI釋出會上演示的簡單方程式組解答,有群友直接將智譜清言用於孩子的作業輔導:
比如小學數學的互余角計算,智譜清言迅速理解了影片中題目的語意,並將問題進行了拆解,一步步引導孩子去計算,當孩子給出正確的答案後,智譜清言還在第一時間給出了「太棒了」的鼓勵。
而在英語教學的場景中,孩子用筆在紙上圈出了某個單詞,智譜清言精準辨識到了圈住的詞匯,並給出了正確的發音,甚至在孩子的朗讀出現錯誤時,「耐心」地進行了讀音矯正,就像是一個坐在孩子身邊的「英語老師」。
第二個場景是產品介紹。
有時買到的商品是英文包裝,可能看不懂使用說明和註意事項,是否可以用「影片通話」功能填補資訊差呢?
我們將網絡攝影機對準了星巴克買來的一款咖啡豆,因為存在折痕,一些英文字母出現了變形,但智譜清言依然準確辨識出了商品資訊,包括產品名稱、配料、產地、風味、品牌等基礎內容。
接下來詢問了咖啡豆的制作和儲存建議,即便是遠遠超出影片畫面中的資訊,智譜清言同樣給出了確切的答案:做美式超合適,味道正好;保存咖啡豆要放在陰涼幹燥的地方,避免受潮或曬太陽......
第三個場景是廚房助手。
因為每天中午都面臨「吃什麽」的煩惱,於是萌生了一個想法:讓智譜清言辨識菜品,並給出建議的菜譜和制作方法。
我們同時將白菜、幹辣椒、大蒜和生姜放在案板上,然後詢問都要哪些食材,可以用來做什麽菜。沒想到的是,智譜清言準確說出了每一種食材的種類,並給出了辣椒炒白菜的建議。
進一步詢問應該怎麽做,智譜清言詳細給出了鍋熱加油、姜蒜炒香、加入紅辣椒、香味出來後放切好的白菜等一整套流程。而當我們進一步詢問「做醋溜白菜還需要哪些食材」時,智譜清言的答案再次讓人驚艷:「做醋溜白菜的話,還需要點醋和糖」。
可以看到,上面的幾個「小兒戲」並不能難倒智譜清言,比答案更重要的其實是整個問答的過程: 不僅能夠準確辨識網絡攝影機拍攝到的內容,聽懂語音指令並準確執行,即使打斷它也能迅速給出反應。相較於機械式的一問一答,在體驗上越來越接近人與人的自然交流。
02 到底難在哪裏
對智譜清言APP的「影片通話」功能做個總結的話,主要解決了三個痛點:
1、新的資訊輸入模式,不再局限於文字和語音,而是文本、影像、音訊和影片等多個模態,AI可以自己「看世界」了;
2、新的對話交流模式,過去的對話交流大多是一問一答式的,合理但不符合真實習慣,現在已經可以做到「隨時打斷」;
3、新的人機互動場景,簡單高於一切,影片和語音帶來了近乎零門檻的使用者教育,意味著人機互動可能迎來革命性更新。
上面提到的情景,曾不只一次出現在科幻電影中。除了前面提到的【鋼鐵俠】,【流浪地球】【Her】【銀翼殺手2047】等電影中都有類似的橋段。因為最符合人類習慣的互動,從來都不是鍵盤,而是對話。
要實作「影片通話」功能,到底難在哪裏呢?就大模型而言,必須要滿足兩個方面的能力要求。
首先是多模態能力。
簡單來說,模態就是資訊輸入和輸出的表現形式,包括文字、影像、語音、影片等等。為什麽多模態能力重要呢?因為人類認識世界的方式本身就是多模態,眼睛、耳朵、嘴巴、手腳等承載了不同的資訊感知,AI想要替代人類的工作,幫助人類學習、認識和理解這個世界,前提正是多模態數據處理能力。
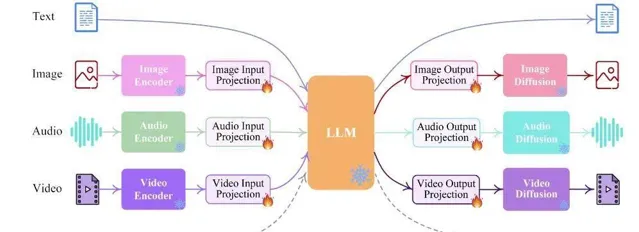
其次是模型推理速度。
人類對話的普遍間隔時間是250毫秒,偏離這個間隔越久,互動就越「不自然」,體驗也就越「不爽」。目前大模型存在的問題在於:推理時長往往在3秒以上,直接影響了使用者體驗和業務效率。OpenAI曾公開GPT-4o的語音延遲數據,平均為 320 毫秒,智譜AI尚未公布詳細數碼,但實際體驗和GPT-4o相當。
也就是說,大模型的競爭就是一場開卷考試,追求的目標一致,且路徑逐漸清晰,比拼的其實是技術硬實力。
以智譜清言為例,之所以成為國內首個面向C端開放「影片通話」功能的產品,離不開兩個核心優勢:
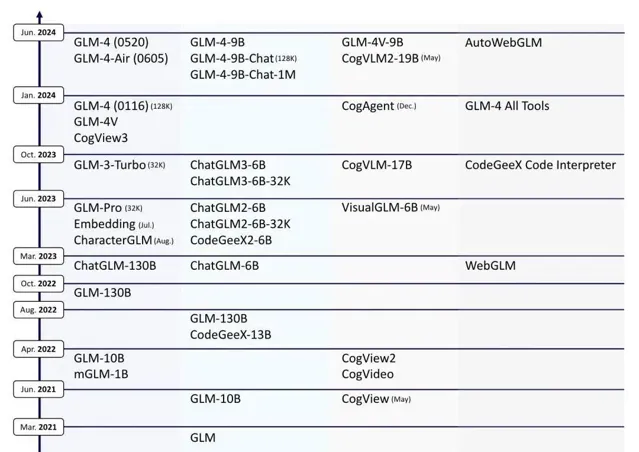
一個是時間上的先發優勢。 早在2021年3月,智譜AI團隊就推出了GLM系列大模型,2021年5月推出了推出了將中文文字生成影像的文生圖模型CogView,2022年在CogView2的基礎上研發了影片生成模型CogVideo……超過國內同行近兩個的時間優勢,讓智譜AI在多模態能力上有著更深的沈澱。
另一個是能力上的領先優勢。 比如智譜AI聯合清華KEG潛心打磨的CogVLM-17B,在多個數據集上獲得了SOTA或第二名的成績;新推出的GLM-4V-Plus,在MVBench、LVBench、OCRBench、MMVET等多個基準測試中的表現超過GPT-4o和Gemini 1.5Pro,達到國際先進水平。
03 「盛宴」剛剛開始
也許在一些人眼中,「影片通話」不過是一項尋常的功能創新,放諸到商業語境裏,卻有著不可小覷的作用。和每一次風口出現時一樣,大模型的概念剛走紅時,創業者們一窩蜂地湧入,試圖在新一輪的創業潮中搏一個機會。可直到現在,市場上還沒有跑出一款真正意義上的殺手級產品。
不少人將ChatGPT的走紅視作「AI的iPhone時刻」,可初代iPhone的銷量只有700萬台,並未覆寫諾基亞統治市場的格局;讓無數開發者從中獲利的App Store,則要追溯到2008年釋出的iPhone 3G。
初代iPhone的「歷史價值」,其實是電容屏和多點觸控。

諾基亞和摩托羅拉也曾推出多「大屏」手機,但采用的是電阻屏,需要用觸控筆才能操作,導致使用門檻高且場景有限。相比之下,多點觸控的電容屏允許使用者直接用手指操作、輸入和互動,極大地降低了使用者的學習成本,賦予了開發者更大的想象空間,進而才有了流動互聯網的繁榮。
沿循這樣的邏輯,「對話方塊」就像是電阻屏,「影片通話」功能讓大模型的人機互動前進演化到了電容屏時代。
個中差別並不難解釋。
作為一個深度使用大模型能力的普通使用者,之前我們的需求主要集中在文本生成、影像生成和影片生成,比如讓AI寫簡單的影片指令碼、生成文章配圖和影片素材,核心場景並未脫離「工作」的範疇。
體驗了智譜清言的「影片通話」功能後,我們深切地感受到:多模態能力和毫秒級的推理速度,在生活中有著無處不在的套用場景,比如出國旅遊時開啟網絡攝影機將餐廳的選單轉譯成中文、工作面試前讓AI扮演面試官提前模擬面試、早上出門時開啟影片詢問今天的穿著怎麽樣、吃零食前先讓AI辨識計算卡路裏……對應的生活場景不可計數。

對於開發者而言,「卷模型還是卷套用」的爭論有了確切的答案:大模型打破能力上的枷鎖後,開發者可以在更多場景中開發有價值的套用。
譬如我們曾走訪過一家工業企業,為了解決大型電腦械器材的維修問題,這家企業采用了AR眼鏡+遠端工程師的模式,即由當地工作人員戴著AR眼鏡采集即時數據,後端的維修工程師進行遠端指導,在一定程度上節約了工程師的差旅和時間成本,但培養一個工程師的時間成本近乎無解。
現在無疑有了新的解法:這家企業可以將工程師的經驗和知識用於訓練專有大模型,然後透過「影片通話」功能為現場員工賦能,在AI的指導下一步步解決問題,每個人都能擁有資深工程師的能力。
把思維再發散一些的話,幾乎所有的場景,都可以利用「影片通話」能力重新做一遍,包括但不限於作業輔導、英語家教、景區導覽、數碼客服等等,等待開發者的不再是同質化競爭的局面,而是深入一個場景做深做實。
當想象力不再被制約的時候,就是價值加速變現的拐點,也是大模型盛宴開場的積極訊號。
04 寫在最後
年初的一場演講上,智譜AI CEO張鵬曾斷言:2024年一定是AGI元年,而多模態是AGI的一個起點。
2024年已經過去三分之二,回頭再來審視張鵬的判斷,正一步步被驗證。同時也意味著,大模型行業的演進正走在一條可預見的道路上,不斷在圖文的基礎上融合聽覺、視覺等模態的認知能力,加速邁向AGI時代。











