微軟推出iPhone能跑的ChatGPT級模型,網友:OpenAI得把3.5淘汰了
人工智能的發展如同一場永不停歇的馬拉松,各大科技巨頭爭相角逐,你追我趕。就在Llama 3剛剛露出水面之際,微軟卻悄然投擲了一記重磅炸彈,讓整個AI圈為之震動。
這場AI軍備競賽的最新戰報來自微軟研究院。他們剛剛釋出的Phi-3系列小模型技術報告,猶如一陣清風,吹散了人們對大模型霸權的迷思。其中,僅有3.8B參數的Phi-3-mini模型,在多項基準測試中竟然超越了參數量高達8B的Llama 3。這一驚人成果,無疑為小模型陣營註入了一劑強心針。

更令人矚目的是,微軟此次打出了"手機就能直接跑的小模型"王牌。經過4bit量化後的Phi-3-mini,在iPhone 14 pro和iPhone 15使用的蘋果A16芯片上,能夠達到每秒12 token的處理速度。這意味著,現在我們的掌上器材也能執行媲美ChatGPT水平的開源模型了。想象一下,在地鐵上、咖啡廳裏,隨時隨地都能與智能助手進行高質素對話,這樣的未來已經悄然來臨。
為了讓開源社區更好地使用這一成果,微軟還特意將Phi-3系列設計成與Llama系列相容的結構。這一舉措無疑會加速AI技術的普及,讓更多開發者能夠站在巨人的肩膀上繼續創新。
微軟的野心並不止步於此。除了迷你版的Phi-3-mini,他們還同時推出了小杯和中杯版本。Phi-3-small擁有7B參數,為了支持多語言,特意換用了tiktoken分詞器,並額外增加了10%的多語種數據。而14B參數的Phi-3-medium更是在更多數據上進行了訓練,在多數測試中已經超越了GPT-3.5和Mixtral 8x7b MoE這樣的強勁對手。

有趣的是,微軟在技術報告中還玩了一個小花招。他們讓Phi-3-mini自己解釋為什麽構建小到手機能跑的模型如此令人驚嘆。這種自解釋的能力,不禁讓人聯想到人工智能是否已經開始具備某種程度的自我意識。
然而,真正令人驚嘆的並非模型的大小,而是其背後的技術創新。微軟研究團隊發現,單純增加參數量並不是提升模型效能的唯一途徑。相反,精心設計的訓練數據才是關鍵所在。他們利用大語言模型本身去生成合成數據,再配合嚴格篩選的高質素數據,讓中小模型的能力實作了質的飛躍。
這種"科書級別"據策略,讓Phi-3系列在訓練階段就接觸到了最精華的知識。為此,微軟團隊可謂下了血本,投餵了多達3.3萬億token的訓練數據,其中Phi-3-medium更是達到了4.8萬億token。他們不僅大幅強化了數據的"教育水平"過濾,還增加了更多樣化的合成數據,涵蓋邏輯推理、知識問答等多種技能。

此外,微軟還采用了獨特的指令微調和RLHF訓練方法,大幅提升了模型的對話能力和安全性。這意味著,Phi-3系列不僅聰明,還更懂得如何與人類進行有意義的交流。
隨著Phi-3系列的問世,AI領域的競爭格局似乎又要重新洗牌。不少網友已經開始呼籲OpenAI盡快推出GPT-3.5的繼任者,以應對這來勢洶洶的挑戰。然而,無論競爭如何激烈,最終受益的必將是我們這些普通使用者。當AI技術變得更加親民,我們的生活也將隨之變得更加智能、便捷。
在這場AI革命中,我們見證了技術的飛速進步,也看到了科技巨頭們的雄心壯誌。但最令人期待的,或許是這些智能助手將如何改變我們的工作方式、學習方式,乃至思考方式。讓我們拭目以待,看看這場由微軟掀起的小模型風暴,將如何重塑我們的數碼未來。
然而,正如硬幣總有兩面,Phi-3系列雖然閃耀奪目,卻也並非完美無缺。微軟坦誠地指出,小模型畢竟受限於其參數規模,無法在模型本身儲存太多事實和知識。這一點從TriviaQA測試分數偏低可見一斑。為了彌補這一短板,微軟提出了一個聰明的解決方案——聯網接入搜尋引擎來增強模型的知識儲備。這種做法不禁讓人聯想到人類的學習過程,我們也常常需要借助外部資源來擴充自己的知識庫。
微軟研究院團隊顯然已經在小模型與數據工程這條道路上找到了自己的節奏。他們鐵了心要在這個方向上繼續深耕,未來還計劃進一步增強小模型的多語言能力和安全性等關鍵指標。這種執著與專註,無疑將為AI領域帶來更多突破性的創新。
值得一提的是,Phi-3系列的誕生並非偶然。從技術報告的作者陣容中,我們可以看到微軟亞洲研究院(MSRA)和微軟研究院雷蒙德團隊都投入了大量人力。這種跨地域、跨團隊的協作,充分展現了微軟在AI領域的全球化布局和雄厚實力。
Phi-3系列的核心秘訣,用一句話來概括,就是"數據為王"年,研究團隊就發現,單純增加參數量並不能保證模型效能的線性提升。相反,精心設計的訓練數據才是提升模型能力的關鍵所在。這種洞見引導他們走上了一條與眾不同的道路。
他們的方法可以說是別出心裁。比如,在篩選訓練數據時,他們會刪除那些僅僅增加知識量而不能提高推理能力的數據。舉個例子,某一天的足球比賽結果對於提升模型的整體能力可能並不那麽重要,因此這類資訊就會被剔除,留下更多能夠鍛煉模型推理能力的高質素數據。
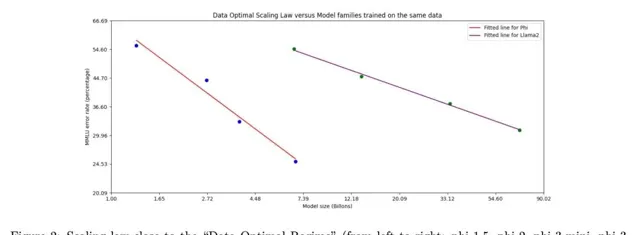
這種近乎苛刻的數據篩選策略,使得Phi-3系列能夠以更小的參數量在MMLU測試中獲得比Llama-2系列更高的分數。這無疑是一個重要突破,證明了在AI領域,巧妙的策略有時候比單純的規模更加重要。
Phi-3系列的訓練過程也頗具特色。他們不僅使用了大量的高質素數據,還采用了獨特的指令微調和RLHF(基於人類反饋的強化學習)訓練方法。這些技術的運用大大提升了模型的對話能力和安全性,使得Phi-3系列不僅能夠理解和執行復雜的指令,還能夠更好地遵循道德和倫理準則。
然而,正如每個新技術都會面臨挑戰一樣,Phi-3系列也存在一些待解決的問題。比如,如何在保持模型小巧的同時,進一步提升其知識儲備能力?如何在不增加模型規模的情況下,持續改善多語言處理能力?這些都是微軟研究團隊未來需要攻克的難題。
盡管如此,Phi-3系列的出現無疑為AI領域註入了新的活力。它向我們展示了,在追求更強大AI的道路上,不僅有參數規模的競賽,還有數據質素和訓練方法的較量。這種多元化的競爭格局,必將推動整個行業向更高水平邁進。
隨著Phi-3系列的釋出,我們似乎看到了一個新時代的曙光。在這個時代裏,強大的AI不再局限於大型數據中心,而是可以被裝進每個人的口袋。這意味著,AI技術的民主化行程正在加速,普通使用者也將很快能夠享受到頂尖AI帶來的便利。
隨著Phi-3系列的橫空出世,AI領域的格局似乎正在悄然改變。這個能在iPhone上流暢執行的ChatGPT級模型,不僅是技術實力的展現,更是對未來AI套用場景的一次大膽探索。
對於普通使用者而言,Phi-3的意義可能遠超我們的想象。試想一下,當每個人的智能電話都能執行一個媲美ChatGPT的AI助手時,我們的日常生活將會發生怎樣的變革?也許在不久的將來,我們可以隨時隨地獲得高質素的語言轉譯、個人化的學習輔導,甚至是深度的情感交流。這不僅僅是技術的進步,更是人機互動方式的一次重大飛躍。
然而,機遇與挑戰總是並存的。隨著AI技術的普及,我們也需要警惕可能出現的問題。比如,如何保護使用者的私密安全?如何確保AI不會被濫用?如何在享受AI帶來便利的同時,保持人類的獨立思考能力?這些都是我們需要認真面對和解決的問題。
對於整個AI行業來說,Phi-3的出現無疑是一記響亮的警鐘。它證明了,在追求更強大AI的道路上,參數規模並不是唯一的決定因素。精心設計的數據策略、創新的訓練方法,以及對實際套用場景的深入思考,才是推動AI技術進步的關鍵。這或許會引發整個行業對AI研發方向的重新思考。
有趣的是,就在Phi-3引發熱議的同時,不少網友開始呼籲OpenAI盡快推出GPT-3.5的繼任者。這種反應生動地反映了AI領域競爭的激烈程度。然而,我們也應該看到,良性的競爭最終將推動整個行業向更高水平邁進,受益的終將是所有使用者。
展望未來,我們有理由相信,像Phi-3這樣的小型高效模型將會得到更廣泛的套用。它們不僅能夠在智能電話上執行,還可能被整合到各種智能家居器材、可穿戴器材,甚至是日常使用的各種電子產品中。這意味著,AI技術將以一種更加無處不在、更加自然的方式融入我們的生活。
當然,技術的發展永遠不會停止。微軟已經表示,他們將繼續在小模型領域深耕,進一步提升多語言能力、安全性等關鍵指標。我們可以期待,在不久的將來,會有更加強大、更加智能的小型AI模型問世。
最後,讓我們回到標題中網友的那句話:"OpenAI得把3.5淘汰了。"句話背後,折射出的是整個AI行業日新月異的發展速度。在這個快速變化的時代,唯有不斷創新,才能始終立於不敗之地。對於我們普通使用者來說,最重要的或許是保持開放和好奇的心態,擁抱這些新技術帶來的變革,同時也要理性地看待它們的局限性。
畢竟,無論AI如何發展,它始終是為了服務人類,而不是取代人類。在這場AI革命中,我們既是見證者,也是參與者。讓我們攜手同行,共同探索AI帶來的無限可能,創造一個更加智能、更加美好的未來。











