01 研究背景
神經網絡的靈感來源於生物學中最精密的電腦--大腦,它是對計算原理的深刻重述。類似的高維、高度互聯的計算架構也出現在活細胞內的資訊處理分子系統中,如訊息傳遞級聯和遺傳調控網絡。在其他物理和化學過程中,甚至是那些表面上扮演非資訊處理角色的過程中,是否也能更廣泛地發現類似於神經計算的集體模式?
02 研究成果
在這裏,芝加哥大學Arvind Murugan、Jackson O’Brien和加州理工學院Erik Winfree、Constantine Glen Evans研究了多組分結構自組裝過程中的成核現象,表明高維濃度模式可以透過類似神經網絡計算的方式進行區分和分類。具體來說,他們設計了一組 917 個 DNA 瓦片,它們能以三種不同的方式進行自組裝,從而使競爭性成核敏感地取決於三種結構中高濃度瓦片的共定位程度。該系統經過電腦訓練,可將一組 18 度灰 30 × 30 像素的影像分為三類。在實驗中,150 h退火過程中和退火後的熒光和原子力顯微鏡測量結果表明,所有經過訓練的影像都能正確分類,而影像變化測試集則檢驗了結果的穩健性。與以前的生化神經網絡相比,他們的方法雖然速度較慢,但結構緊湊、穩健且可延伸。他們的發現表明的物理現象(如成核)在高維多組分系統中發生時,可能具有強大的資訊處理能力。相關研究工作以「Pattern recognition in the nucleation kinetics of non-equilibrium self-assembly」為題發表在頂級期刊【Nature】上。

03 圖文速遞
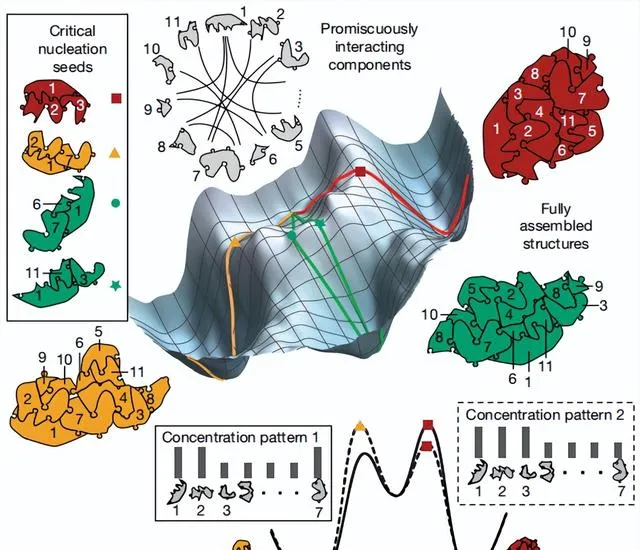
圖1. 成核模式辨識的概念框架
在這裏,他們將這種聯系重新表述為異質成核動力學的固有特征,並利用 DNA 納米技術透過實驗證明了其在高維模式辨識方面的能力。當相同的部件能以不同的幾何排列形成多個不同的集合體時,就會出現這種現象。成核是透過自發形成臨界種子進行的,種子隨後長成結構。由於種子的成核率在很大程度上取決於種子中各組分的體積濃度,而且許多不同的種子和途徑都可能是可行的,因此特定結構的總體形成率是濃度模式的復雜函數。此外,由於結構之間共享成分,對資源的競爭導致了贏家通吃(WTA)效應,從而加劇了集中模式之間的差異。
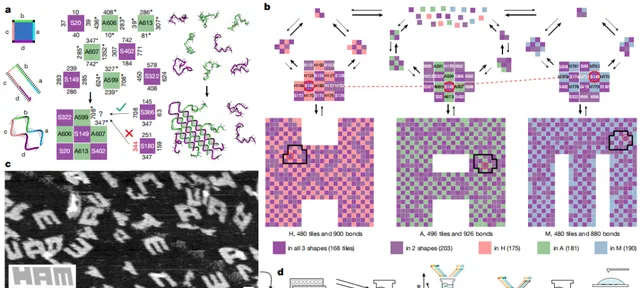
圖2. 917種分子的多種混合物,可以從一組分子組裝成三種不同的結構
為了透過實驗探索這些原理,他們利用了 DNA 納米技術為分子自組裝編程提供的強大基礎。Watson-Crick堿基配對的動力學和熱力學已廣為人知,這使得我們能夠對 DNA 瓦片進行系統的序列設計,從而可靠地自組裝成周期性、唯一尋址和演算法模式化的結構,這些結構具有數百到數千種不同的瓦片類別。這些類別的自組裝所產生的結構和相互作用的性質各不相同:在周期性和唯一尋址結構中,每個分子成分通常在每個方向上都有一個獨特的可能結合夥伴。對於演算法模式(如多元組裝),一些成分有多個可能的結合夥伴,因此在自組裝過程中,根據哪個成分與相鄰瓦片形成的結合更多,來決定哪個成分連線在給定位置。
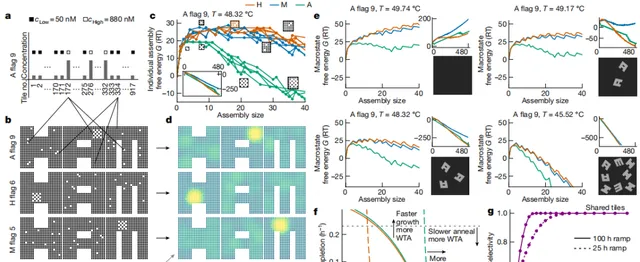
圖3. 理論表明,當高濃度瓦片以一種形狀共存時,選擇性成核比以其他形狀共存多
請看圖 3 中的範例,SHAM 混合體中某些共享瓦片的濃度得到了提高。這些高濃度瓦片在結構A中共定位,但分散在H和M上。因此,這種模式將降低 A 的成核動力學勢壘,同時保持 H 和 M 的高勢壘。根據經典成核理論預測的臨界種大小,可以估算出共聚促進成核的典型區域 K,在溫度較高時,K 通常較大。因此,他們預計模式辨識的速度和復雜性之間存在權衡,溫度越高(K 越大),分辨能力越強--代價是實驗速度越慢,而溫度越低(K 越小),分辨能力越弱。

圖4. 共享瓦片特定形狀局部濃度模式實驗中的選擇性成核
為了在實驗中表征選擇性的基礎,他們系統地測試了一系列 37 種濃度模式,他們稱之為「旗幟」,因為每種模式都在其中一種形狀的某處使用了高濃度的瓦片圖案。他們沒有提高形狀所特有的瓦片的濃度,以避免對任何一種結構產生額外的熱力學偏差。他們將溫度從 48°C 緩慢降到 46°C(成核的預期範圍,比熔化溫度低幾度),以確保不同位置的標記之間成核溫度的穩健性,並探測緩慢偏離目標的成核。為了即時監測成核和生長情況,他們在每個形狀上的四個位置的相鄰瓦片上設計了不同的熒光團淬滅劑對,使用形狀之間不共享的瓦片。當特定結構的局部區域聚集時,每對熒光團都會熄滅。

圖5. 設計自組裝相圖,解決模式辨識問題
他們迄今為止的工作表明,所有濃度模式的空間(包括未經過實驗測試的模式)都由分別導致 H、A 和 M 各自選擇性組裝的區域組成。這些區域共同代表了這一自組裝系統的相圖,反映了它對濃度模式進行分類的決策。傳統研究的物理系統的相界通常是低維的,不能有效地解釋為決策邊界,而在像他們這樣的多組分異質系統中,相圖自然是高維的。更一般地說,無序多體系統中的相界往往是復雜的,因此隱含地解決了復雜的模式辨識問題,這一觀點也是神經網絡中Hopfield聯想記憶的基礎。
在這裏,成核是根據分子在不同結構中的共定位來解決一個特殊的模式辨識問題。Mosers研究的神經位置細胞中也存在類似的基於共定位的決策邊界,其復雜程度足以解決模式辨識問題,並允許進行統計上穩健的學習。在證明了多種自組裝可以解決特定的模式辨識問題之後,是否可以設計不同的分子來解決其他任務,如辨識或分類影像?在這裏,30 × 30 影像中每個像素位置的灰度值代表一種不同分子的濃度。為了解決上述難題,他們不需要合成具有新相互作用的新分子,而是透過最佳化選擇像素-瓦片對映θ(指定哪個現有瓦片應對應哪個像素位置),證明可以利用現有分子解決設計問題。除了節省 DNA 合成成本外,這種方法還有助於證明,可以事後利用隨機分子設計,透過修改問題對映到物理元件的方式來解決特定的計算問題,就像儲層計算中的做法一樣。
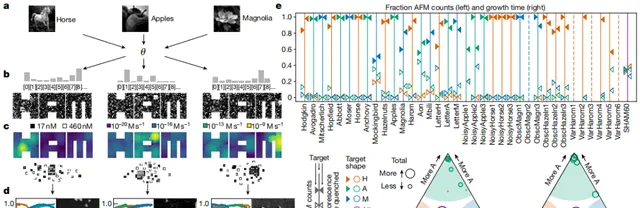
圖6. 利用已有的多種系統進行模式辨識的結果
在模式辨識實驗中,他們根據 18 幅訓練影像中的每一幅影像(使用最佳化的 θ)提高了 SHAM 混合料中瓦片的濃度,並對 18 種混合料中的每一種進行了 150 h的退火,退火溫度從 48°C 調至 45°C。經原子力顯微鏡成像和即時熒光淬滅驗證,他們發現 18 幅訓練影像產生了正確的晶核,即正確形狀的晶核多於其他形狀的晶核,而且除五種情況外,其他所有情況都具有高度(80% 以上)選擇性。
04 結論與展望
他們的工作將復雜的資訊處理作為一種新出現的現象,在這種現象中,自組裝在多組分極限下獲得了可編程和潛在可學習的相界,以解決特定的模式辨識問題,這與早先大型 N 神經網絡的結果類似。這種受神經網絡啟發的觀點可能有助於他們認識高維分子系統中的資訊處理,無論是在生物學還是在分子工程學中,這種資訊處理都深深地纏結在物理過程中:多組分液體凝結物、多組分活性物質和其他系統都可能具有類似的可編程和可學習的相界。
05 文章連結
連結:
https://www.nature.com/articles/s41586-023-06890-z











