【科創板日報】2月19日訊(記者 黃修眉) OpenAI再次以大模型Sora引爆全球。A股龍年開市第一天,包括當虹科技、博匯科技、萬興科技、因賽集團在內涉及文生影片的上市公司股價也受此提振,均強勢漲停。
針對上述公司在多模態模型與AIGC方面的布局與現狀,【科創板日報】記者以投資者身份致電上述公司董秘辦。
整體來看,各家公司都在緊鑼密鼓地研發或階段性地釋出多模態大模型及其落地套用。業內人士也表示,多模態將AI大模型的新一輪革命,同時也是未來人工智能套用的主要形式。
集合式系統賦能多領域
當虹科技此前在互動平台表示,該公司擁有自研的AIGC工具集,於2023年上半年釋出了以靜態照片生成三維體積影片的方案,支持6DOF(六自由度)視角自由移動,並且透過點雲模型轉換及壓縮演算法實作高達800倍的視覺無損壓縮,實作不同模態之間相互切換。
當虹科技董秘辦人士向記者表示,「上述提到的工具集擁有文生圖、圖生影片、文生影片等多種技術與功能,集合在公司研發的AIGC影片內容智能生成系統上,該系統融合了大模型技術,能夠將多種媒介內容,如文本、圖片、音訊、影片等,高效智能地轉化為高品質的影片內容,但並不是可以下載的APP形式。」
「公司也正在研發與AI相關的其他多模態系統,目前正在進行最佳化與偵錯。」上述董秘辦人士稱,「從技術底座來看沒有太大問題,都在進行之中,但具體到產品的形式甚至釋出時間等,目前無法確定。」
對於「公司多模態AI領域是否有自己核心技術活產品布局」的問題,博匯科技證代辦人士向【科創板日報】記者表示,該公司的多模態處理技術主要套用於傳媒安全領域,以AI多模態辨識引擎為支撐,透過運用人工智能、大數據等技術,提升對文本、圖片、音訊、影片等多類別數據的處理分析能力。
【科創板日報】記者註意到,博匯科技擁有以視聽大數據采集技術、分析技術、視覺化技術三大核心技術為軸心的視聽數據處理技術群,在公司所涉及的領域,特別是在對視聽數據處理要求極高的廣播電視領域得到了廣泛套用。
對於「公司是否有研發C端客戶套用」的問題,當虹科技則表示該公司存在相關研發和套用,但其主業以賦能政務和企業為主。博匯科技則表示,該公司目前暫未針對C端客戶進行套用研發。
「從科創板的定位和對上市公司的要求來看,科創板聚焦AIGC業務的公司不太可能只涉及或者以C端業務為主。有長期關註人工智能及其套用的業內分析師向【科創板日報】記者表示,「他們更多是以大模型、大數據為基礎,研發國產化的文、圖、音訊、影片整合系統賦能各個行業,特別是涉及到資訊數據安全的領域。」
值得一提的是,博匯科技2023年11月在互動平台表示,已完成全國產化雙引擎分布式系統及桌上型國產化影片處理平台的研發。
AI內容生成套用受關註
除上述科創板公司業務涉及多模態模型外,萬興科技與因賽集團也因旗下消費級套用產品受到投資者關註。
需要一提的是,當虹科技、博匯科技聚焦影片/視聽相關技術,集合多種技術與產品,賦能傳媒、教育、安防、汽車等行業,客戶以政務與企業為主;萬興科技與因賽集團除提供上述兩端解決方案外,同時也開發了多款針對C端使用者的APP/小程式。
2024年1月30日,萬興科技正式釋出國內首個音影片大模型萬興「天幕」。這是一個以音影片生成式AI技術為基礎的多媒體創作垂類大模型,由影片大模型、音訊大模型、圖片大模型、語言大模型組成,聚焦數碼創意垂類創作場景。

萬興天幕多媒體大模型AI創作【江湖恩仇錄】 圖源:公司官方公眾號
萬興科技董秘辦人士向記者表示,該公司旗下影片創意產品萬興喵影/Filmora可用於各類影片的創作和剪輯,萬興錄演/Demo Creator可用於演示影片的錄制與編輯等。
根據天幕大模型釋出會數據,2023年8月至12月,萬興喵影使用AI功能的使用者數上漲243%;2022年1月至2023年1月,萬興播爆活躍使用者數提升700%。
對於影片生成大模型,萬興科技董事長吳太兵此前公開表示,大模型正在從圖文1.0時代進入到以音影片多媒體為載體的2.0時代。
而對於因賽集團是否有類似Sora的產品,萬興科技董秘辦人士向【科創板日報】記者表示,該公司AIGC專案團隊將在三月進行文生影片功能的開發,等待時機成熟後投入公測。
關於InsightGPT的進展,因賽集團2024年1月接受投資者調研時披露,InsightGPT內測版已於近期開放影片智能剪輯功能供合作夥伴、投資機構、券商分析師等進行試用體驗。
預計2024年2月底前,開放體驗圖生影片相關行銷套用產品;預計2024年3月底前,開發實作文生影片功能,之後推出公測版正式啟動商業化。
AI大模型的新一輪革命
【科創板日報】記者註意到,從最終呈現的形式看,相比單模態,多模態大模型同時處理文本、圖片、音訊以及影片等多類資訊,更符合人類接收、處理和表達資訊的方式,也更能夠成為人類智能助手。
目前谷歌已推出多模態大模型Gemini 1.5 Pro;Meta已陸續開源ImageBind、AnyMAL等多模態大模型;OpenAI近期密集劇透GPT-5,重點突破語音輸入和輸入、影像輸出以及最終的影片輸入方向,或將實作真正多模態。
華福證券研究所電腦團隊分析師施曉俊2月18日發文認為,多模態是AI大模型的新一輪革命。多模態提升大模型泛化能力,多元資訊環境下實作「多專多能」,在垂直領域具有廣闊的套用場景和市場價值,施曉俊稱。
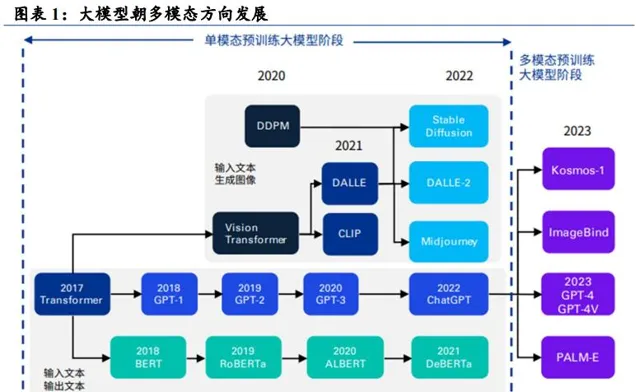
圖源:華福證券研報
【科創板日報】記者註意到,相比較文本生成,影片生成大模型以及套用由於數據、算力等多方面原因,導致目前產品數量較少。
網絡上,谷歌Gemini與Sora進行對抗訓練的影片,也能讓人發現Sora生成的部份場景存在疑似不符基本常識的情況,效果似乎並不完美。
整體來看,多模態模型對行業會帶來怎樣變化暫未可知。對上述上市公司業務的後續發展,【科創板日報】記者將持續關註報道。











