文 | 智能相對論
作者 | 陳泊丞
日前,輝達CEO黃仁勛和Meta創始人馬克朱克伯格開展了一場「爐邊談話」。
兩人作為當今人工智能領域的領袖人物,一邊憑借AI芯片的絕對優勢占據著算力領域的至高地位,另一邊借助開源大模型Llama 3.1強勢崛起成為開源領域的標桿。這樣的對話為未來AI的發展趨勢呈現了不同的視角。

黃仁勛對話朱克伯格
兩位大咖的對話為我們描繪了AI技術未來的發展藍圖:從開源的AI演算法,到先進的人形機器人,到未來即將普及的智能眼鏡,AI技術發展充滿了機遇與挑戰。未來AI手機、AIPC、AI汽車、智能眼鏡、伺服器等等各類產品都會實作智能化升級,復雜的模型、海量的數據和計算,都極大地依賴於AI算力支持。
AI算力也正在從專用計算擴充套件到所有的計算場景,逐步形成「一切計算皆AI」的格局。
事實上,算力廠商們的動作也見證了市場對算力發展的要求。一方面,CPU、GPU、NPU等各種PU,也都被用於了AI計算。
另一方面,在適配不同場景套用的通用伺服器上,浪潮資訊也在致力於提供兼具高效能與低成本的選擇。前不久,基於2U4路旗艦通用伺服器NF8260G7,浪潮資訊創新采用領先的張量並列、NF4模型量化等技術,實作了伺服器僅依靠4顆CPU即可執行千億參數「源2.0」大模型,再度成為通用AI算力的新標桿。
在今天的市場上, 算力的產業地位正在迅速崛起。對應人工智能發展的三駕馬車,算力、演算法、數據三者終於到達了一個地位相當的狀態,走向「並駕齊驅」。
要知道,在AI技術發展的前期,中國龐大的互聯網使用者群體和豐富的線上數據資源,側重於數據的發展。而美國在電腦科學、數學和統計學等基礎學科方面有著悠久的研究傳統,則更聚焦演算法的研發。對比兩者,算力在前期的關註度就顯得弱了許多。
時至今日,三駕馬車並駕齊驅。大眾對人工智能的發展思路也愈發清晰——AI產業的爆發是演算法、算力與數據三者協同發展的結果。而這樣的狀態也就代表著AI產業正在進入一個全新的階段。
人工智能產業 來到了「過彎點」
現階段,大模型技術的加速叠代,帶來了千億級大模型的持續湧現與精進。相關的AI套用也在以前所未有的速度和規模滲透到各行各業,並融入日常的生活和工作中。
人工智能產業正在從初步探索進入到了廣泛套用的「過彎點」。在這個過程中,AI的三駕馬車也到了全面協同發展的關鍵時刻,才能為場景套用的跨越式升級提供必要的技術支持。
以銀行的防欺詐系統為例,早期的系統是基於大數據構建的,透過經驗預設規則和統計模型來判斷、檢測可疑交易。如今,基於更高效能的通用算力整合大數據系統和金融防詐的AI模型,銀行防欺詐系統實作了功能升級,不僅具備更高的準確性和更低的誤報率,而且還能夠根據新的數據自我學習和調整,快速適應新的欺詐模式。
演算法、算力和數據三者協同,構成當前AI套用的基本範式。一個成功的AI專案往往需要在這三個方面都做出適當的投入和最佳化。
演算法相當於AI的大腦,負責處理資訊、學習知識、做出決策。而數據是演算法的基礎,如果沒有足夠的數據,即使是再先進的演算法也無法發揮出應有的效果。
而在此基礎上,不管是演算法的執行還是數據的處理,都離不開算力的支持。特別是在涉及到大量的數據處理、復雜的模型訓練以及即時的推理需求等場景中,AI對算力的要求,同時隨著場景的規模化普及,還得進一步兼顧經濟性。
現如今,針對AI產業的三駕馬車,演算法、算力和數據層面的升級依舊在同步進行,三者之間的協同在AI行業發展的驅動下達到了新高度。AI產業的加速發展,需要三駕馬車的步伐更加一致。
是時候全面調整 三駕馬車的狀態了
人工智能的廣泛套用必然要建立在三駕馬車協同發展的基礎上。在接下來的時間內,針對人工智能產業的升級就需要解決一個關鍵問題,即如何保持三駕馬車並駕齊驅的穩定狀態。
一、技術「並駕」:一馬當先並非最佳,三馬同行最為穩定。
算力、演算法、數據三者相輔相成,單一的技術領先無法帶來AI產業的全面爆發,必須要另外兩項迅速補齊,才能對應解決相關的技術問題。
例如,在當前,千億級參數、甚至萬億級參數的大模型加速發展,帶來了更強大的資訊處理和決策能力,為智能湧現提供了基礎。但是,演算法層面的突破,必然要有算力、數據層面的升級,才能發揮出套用的效果。簡單來說,如果沒有足夠的算力帶動千億級大模型的訓練、推理等需求,那麽再強大的模型也沒有「用武之地」。
要加速人工智能的發展,支撐千行百業最廣泛的通用場景,千億級大模型必須要和大數據、數據庫、雲等場景相融合,實作高效執行。
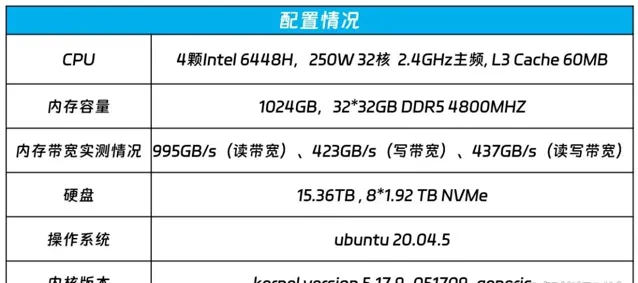
但這一目標對計算、記憶體、通訊等硬件資源需求量非常大。為了滿足更多使用者的AI算力需求,算力廠商不得不考慮如何有針對性地去克服現有的算力瓶頸。以承載千億參數大模型推理的NF8260G7 AI通用伺服器來看,浪潮資訊在這方面就做出了專業的設計。
針對千億級大模型推理過程中的低時延以及所需的巨大記憶體需求,NF8260G7伺服器配置了4顆具有AMX的AI加速功能的英特爾至強處理器,記憶體方面,NF8260G7配置32根32G DDR5 4800MHZ的記憶體,記憶體頻寬實測值分別為995GB/s(讀頻寬)、423GB/s(寫頻寬)、437GB/s(讀寫頻寬),為滿足千億大模型低延時和多處理器的並行推理計算打下基礎。同時,浪潮資訊還對CPU之間、CPU與記憶體之間的高速互聯訊號走路線徑和阻抗連續性做了最佳化,從而更好地支撐大規模並行計算。
這樣的設計與升級,旨在面向演算法,進行算力的最佳化,為接下來千億級大模型的規模化套用提供了一個非常關鍵的支撐。
二、系統「齊驅」:三馬拉車,重在系統性最佳化。
隨著AI技術的發展,算力、演算法、數據三者的系統性越來越強。很多科技巨頭都在競相發力尋找「模型水平高、算力門檻低」的人工智能方案。AI相關的解決方案不再是單一技術的套用,而是綜合多個領域的突破實作整體系統性的升級。
舉個例子,谷歌的EfficientNet模型透過最佳化網絡架構,在ImageNet數據集上的精度相比傳統模型提升了約6%,而所需計算量減少了70%。可見,當前大模型廠商在推動算力升級的過程中,也會考慮到軟件層面的創新,提高算力和演算法之間的適配執行能力。
為了能讓通用伺服器更好的執行千億級大模型,浪潮資訊除了對伺服器本身進行創新升級外,也對千億級大模型的參數規模做了最佳化。基於源2.0的演算法研發積累,浪潮資訊將1026億參數的源2.0大模型摺積算子進行張量切分,為通用伺服器進行高效的張量平行計算提供了可能,最終提高了推理計算效率。
基於CPU伺服器的平行計算
同時,在這個過程中,浪潮資訊還采用了NF4量化技術,對模型進行「瘦身」,提高了推理的解碼效率等等。
NF4量化技術
當算力、演算法走向協同,系統性最佳化的結果,是建立在兩者協同的基礎之上,最終目的在於為AI產業的落地提供一個穩定、強大的技術底座。未來,AI產業的全面爆發就需要以更系統的理念去驅動三駕馬車的發展。
三、套用「加速」:產業落地需要「三駕馬車」的綜合最優解。
AI不再是實驗室的產物,而是市場競爭的商品。不管是千億級大模型的湧現,或是算力解決方案的升級,其根本的目標都是推動AI套用的加速落地,走向大眾,帶來實際性的經濟效益。因此,在技術層面之外,行業還需要考慮經濟層面的問題。
對比來看,盡管以輝達GPU芯片為核心的AI伺服器在處理機器學習、深度學習等高效能計算任務方面表現卓越,但是浪潮資訊等算力廠商依舊致力於研發和升級以CPU為核心的通用伺服器,這是為什麽?
根本原因就在於CPU在通用計算、能效比以及成本效益方面仍然不可替代。特別是關系成本效益的經濟性問題,本來就是當前限制諸多場景套用規模化落地發展的關鍵因素。因為AI專用基礎設施的成本居高不下,普通的企業很難承受。而浪潮資訊則是提供了一個更低成本、同時兼顧高效能的經濟性選擇,恰恰正是市場需要的。
基於通用伺服器NF8260G7的軟硬件協同創新,浪潮資訊成功實作了千億級大模型在通用伺服器的推理部署,同時還提供了效能更強,成本更經濟的選擇,讓AI大模型套用可以與雲、大數據、數據庫等套用能夠實作更緊密的融合,助力產業高質素發展。這樣的綜合最優解,才是產業實作規模化爆發最需要的條件。
結語
AI三駕馬車的系統性已經成型,更強大的算力可以支持更復雜的演算法模型,從而更好地處理大規模數據。同時,高質素的數據集有助於提升演算法的效果,反過來又需要更強大的算力來處理。而演算法的進步也可以減少對算力的需求,透過更高效的模型設計降低計算成本。
這種系統性的形成,將極大推動人工智能產業的發展,也為現階段AI廠商們的產品升級、技術叠代、服務進階提供了一個關鍵的大方向。但同時,也意味著新的挑戰,即如何去整合算力、演算法和數據三者之間的技術與資源,成就新的突破。
*本文圖片均來源於網絡











