
圖片來源@視覺中國
文 | 適道
2024年的開年震撼同樣來自OpenAI。節後還沒開工,Altman就帶著繼ChatGPT的第二個殺手級套用Sora大殺四方。適道看完那條長達60s的演示影片後,腦中只有一句話:大家誰都別想玩了。快速回歸理智,Sora統治之下,是否還有其他機會?我們從a16z釋出的展望——「Why 2023 Was AI Video’s Breakout Year, and What to Expect in 2024」入手,盤一盤這條賽道留給其他玩家哪些空間。
01 用好巨頭「殲滅戰」視窗期
OpenAI推出Sora不讓人意外,讓人意外的是Sora之強大難以想象。
細數2023年AI影片賽道,有兩條非常清晰的邏輯。
一是AI生成影片發展之迅猛。2023年初還出現公開的文生影片模型。僅僅12個月後,就有Runway、Pika、Genmo和Stable Video Diffusion等數十種影片生成產品投入使用。
a16z認為,如此巨大的進展說明我們正處於大規模變革的起步階段——這與影像生成技術的發展存在相似之處。文本—影片模型正在不斷演化進步,而影像—影片和影片—影片等分支也在蓬勃發展。
二是巨頭入場只是時間問題。2024年註定是多模態AI爆發之年。然而,細數2023年21個公開AI影片模型,大多數來自初創公司。
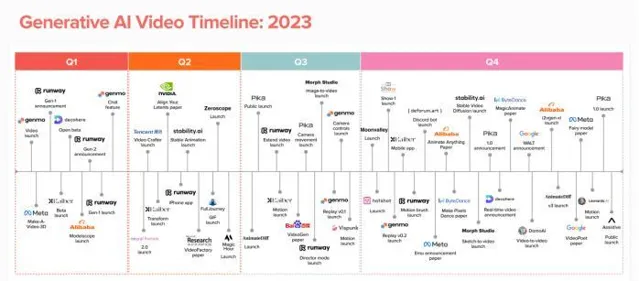
表面上,Google、Meta等科技巨頭如湖水般平靜,但水面之下暗流湧動。巨頭們沒有停止發表影片生成的相關論文;同時,他們還在不聲明模型釋出時間的前提下對外釋出演示版本的影片,比如OpenAI釋出Sora。
明明演示作品已經成熟,為何巨頭們不著急釋出呢?a16z認為,出於法律、安全以及版權等方面的考慮,巨頭很難將科研成果轉化成產品,因此需要推遲產品釋出,這就讓新玩家獲得了先發優勢。
適道認為,最關鍵因素是「網絡效應」並不重要——正選玩家不是贏家,技術領先才是贏家。有了能生成60s影片的Sora,你還會執著於生成4s影片的Pika嗎?
但這不代表初創公司徹底沒戲。因為在該規律下,巨頭們的動作不會太快,初創公司需要抓住「視窗期」,盡量快速釋出產品,圈一波新使用者,賺一波快錢,尤其是在國內市場。
補充前阿裏技術副總裁、目前正在從事AI架構創業的賈揚清的觀點:1.對標OpenAI的公司有一波被其他大廠fomo收購的機會。2. 從演算法小廠的角度,要不就演算法上媲美OpenAI,要不就垂直領域深耕套用,要不就選擇開源。(創業邦)
02 「學霸」Sora強在哪裏?
目前,絕大部份AI影片產品還未解決核心難題:可控性、時間連貫性、時長。
可控性:用文本「描述」控制畫面中人物的運動軌跡。
當然,一些公司可以為使用者提供影片生成前的可控性。例如,Runway的Motion Brush讓使用者高亮影像的特定區域,並決定它們的動作。
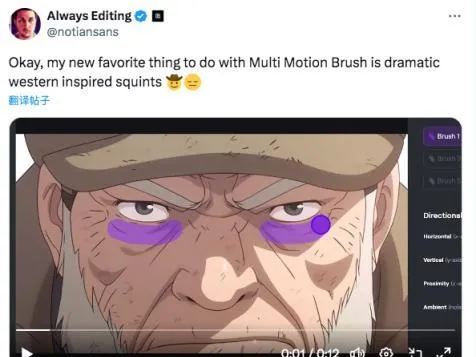
時間連貫性:人物、物體、背景在不同幀之間保持一致,不發生扭曲。
時長:能夠制作超過幾秒的影片?
影片的時長和時間連貫性息息相關。許多產品都限制影片時長,因為在時長超過幾秒後就無法保證任何形式的一致性。如果你看到一個較長的影片,很可能是由很多簡短片段構成,而且往往需要輸入幾十甚至上百條指令。
而Sora的強大在於突破了以上難題。
1、時間連貫性——前景人來人往,但主體始終保持一致
2、時長——輕輕松松生成60s
3、可控性——畫家的手部動作非常逼真
不僅如此,Sora還能更好地理解物理世界。養貓的人應該明白這個影片的含金量,居然模擬出了貓咪「踩奶」!
Sora能夠實作如此突破,在於OpenAI走上了一條與眾不同的道路。
假設Sora是一個足不出戶的小朋友,他理解外部世界的方式是觀看五花八門的影片和圖片。
但Sora小朋友只能看懂簡單的資訊,OpenAI就為其量身打造了一套啟蒙學習課程——透過「影片壓縮網絡」技術,將所有「復雜」的影片和圖片壓縮成一個更低維度的表示形式,轉換成Sora更容易理解的「兒童」格式。
舉個不那麽恰當的例子。「影片壓縮網絡」技術就是將一部成人能看懂的電影內核轉換為一集Sora更容易理解的「小豬佩吉」。
在理解「學習資訊」階段,Sora進一步將壓縮後的資訊數據分解為一塊塊「小拼圖」——「時空修補程式」(Spacetime Patches)。
一方面,這些「小拼圖」是視覺內容的基本構建塊,無論原始影片風格如何,Sora都可以將它們處理成一致的格式,就像每一張照片都能分解為包含獨特景觀、顏色和紋理的「小拼圖」;另一方面,因為這些「拼圖」足夠小,且包含時空資訊,Sora能夠更細致地處理影片的每一個小片段,並考慮和預測時空變化。
在生成「學習成果」階段,Sora要根據文本提示生成影片內容。這個過程依賴於Sora的大腦——擴散變換器模型(Diffusion Transformer Model)。
透過預先訓練好的轉換器(Transformer),Sora能夠辨識每塊「小拼圖」的內容,並根據文本提示快速找到自己學習過的「小拼圖」,把它們拼在一起,生成與文本匹配的影片內容。
透過擴散模型(Diffusion Models),Sora可以消除不必要的「噪音」,將混亂的影片資訊變得逐步清晰。例如,塗鴉本上有很多無意義的線條,Sora透過文本指令,將這些無意義的線條最佳化為一幅帶有明確主題的圖畫。
而此前的AI影片模型大多是透過迴圈網絡、生成對抗網絡、自回歸Transformer和擴散模型等技術對影片數據建模。
結果就是「學霸」Sora明白了物理世界動態變化的原理,實作一通百通。而其他選手在學習每一道題解法後,只會照葫蘆畫瓢,被「吊打」也是在情理之中。
03 未來AI影片產品如何發展?
根據a16z的展望,AI影片產品還存在一些待解決空間。
首先,高質素訓練數據從何而來?
和其他內容模態相比,影片模型的訓練難度更大,主要是沒有那麽多高質素、標簽化的訓練數據。語言模型通常在公共數據集(如 Common Crawl)上進行訓練,而影像模型則在標簽化數據集(文本-影像對)(如 LAION 和 ImageNet)上進行訓練。
影片數據則較難獲得。雖然 YouTube 和 TikTok 等平台不乏可公開觀看的影片,但這些影片都沒有標簽,而且可能不夠多樣化(例如貓咪影片和網紅道歉等內容在數據集中比例可能過高)。
基於此,a16z認為影片數據的「聖杯」可能來自工作室或制作公司,它們擁有從多個角度拍攝的長影片,並附有指令碼和說明。不過,他們是否願意將這些數據授權用於訓練,目前還不得而知。
適道認為,除了科技巨頭,長期來看,以國外Netflix、Disney;國內「愛優騰」為代表的行業大佬也不容忽視。這些公司積攢了數十億條會員評價,熟知觀眾的習慣和需求,擁有數據壁壘和套用場景。去年1月,Netflix就釋出了一支AI動畫短片【犬與少年(Dog and Boy)】。其中動畫場景的繪制工作由AI完成。對標到國內,AI影片賽道大概率依然是互聯網大廠的天下。
其次,用例如何在平台/模型間細分?
a16z認為,一種模型不能「勝任」所有用例。例如,Midjourney、Ideogram和DALL-E都具有獨特的風格,擅長生成不同類別的影像。預計影片模型也會有類似的動態變化。圍繞這些模式開發的產品可能會在工作流程方面進一步分化,並服務於不同的終端市場。例如,動畫人物頭像(HeyGen)、視覺特效(Wonder Dynamics)和影片到影片( DomoAI)。
適道認為,這些問題最終都會被Sora一舉解決。但對於國內玩家而言,或許也是一個「中間商賺差價」的機會。
第三,誰將支配工作流程?
目前大多數產品只專註於一種類別的內容,且功能有限。我們經常可以看到這樣的影片:先由 Midjourney 做圖,再放進Pika制作動畫,接著在Topaz上放大。然後,創作者將影片匯入 Capcut 或 Kapwing 等編輯平台,並添加配樂和畫外音(由Suno和ElevenLabs或其他產品生成)。
這個過程顯然不夠「智能」,對於使用者而言,非常希望出現「一鍵生成」式平台。
據a16z展望,一些新興的生成產品將增加更多的工作流程功能,並擴充套件到其他類別的內容生成——可以透過訓練自己的模型、利用開源模型或與其他廠商合作來實作。
其一,影片生成平台會開始添加一些功能。例如,Pika允許使用者在其網站上對影片進行放大處理。此外,目前Sora也可以建立完美迴圈影片、動畫靜態影像、向前或向後擴充套件影片等等,具備了影片編輯的能力。但編輯效果具體如何,我們還要等開放後的測試。
其二,AI原生編輯平台已經出現,能夠讓使用者 「插入」不同模型,並將這些內容拼湊在一起。
可以預見的是,未來大批內容制作者將同時采用AI和人工生成內容。因此,能夠「絲滑」編輯這兩類內容的產品將大受歡迎。這或許是玩家們的最新機會。











