為了讓飛槳開發者們掌握第一手技術動態、讓企業落地更加高效,飛槳官方在7月至10月特設【飛槳框架3.0全面解析】系列技術稿件及直播課程。技術解析加程式碼實戰,帶大家掌握包括核心框架、分布式計算、產業級大模型套件及低程式碼工具、前沿科學計算技術案例等多個方面的框架技術及大模型訓推最佳化經驗。本文是該系列第六篇技術解讀,文末附對應直播課程詳情。
大模型時代是人工智能領域的一個重要發展階段,推理部署的重要性隨之愈發凸顯。它關乎到模型在產業套用中的效能表現、執行效率、成本控制以及使用者體驗的優劣, 是將大模型研究成果轉化為實際套用的重要橋梁,對於充分發揮大模型的潛力,推動人工智能技術的廣泛套用具有重要意義。
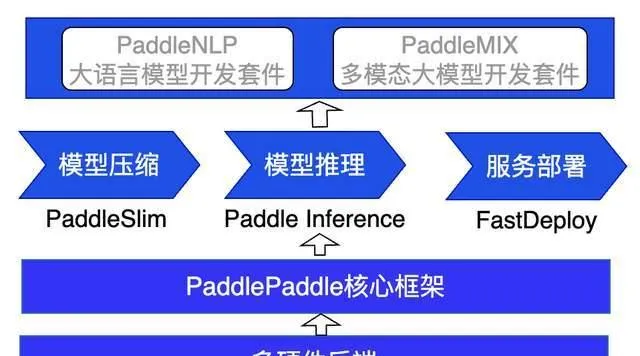
飛槳框架3.0的核心元件之一——飛槳推理引擎,本次也迎來了全面革新。此次升級 依托於高擴充套件性的中間表示(PIR)以及 靈活易用的 PASS 機制,顯著增強了推理部署的最佳化效率和效能。同時,新版本的推理引擎還引入了一鍵轉靜使用 Paddle Inference 推理介面,極大地簡化了從動態圖到靜態圖的推理流程,為使用者提供了更加便捷和高效的推理體驗。
針對大模型在產業上部署的嚴苛需求,飛槳框架3.0在從大模型壓縮到推理加速,再到服務化部署全流程部署能力上進行了深度最佳化。特別在飛槳的兩大重要套件——PaddleNLP 大語言模型開發套件與 PaddleMIX 多模態大模型開發套件中,我們精心準備了詳盡的全流程部署教程文件,旨在 幫助使用者輕松上手,快速實作從模型訓練到實際部署的無縫對接。
在硬件支持方面,飛槳推理引擎展現出了強大的相容性和靈活性。它不僅完美支持輝達 GPU 的多機多卡高效部署,還積極擁抱國產及國際領先的 AI 芯片生態,包括昆侖 XPU、昇騰 NPU、海光 DCU、燧原 GCU 以及英特爾 CPU 等多種硬件的推理支持。這一舉措確保了飛槳能夠 覆蓋更廣泛的部署場景,滿足不同使用者的多樣化需求,推動大模型推理技術在更多實際業務中的套用與落地 。
特點一
大語言模型無失真量化壓縮方案
基於 PaddleSlim 提供的多種大語言模型 Post Training Quantization(PTQ)訓練後量化技術,提供 WAC(權重/啟用/KV 緩存)靈活可配的量化能力,支持 INT8、FP8、4Bit 量化能力。 針對大模型啟用數值分布的特點,創新的提出並實作了分段啟用平滑(Piece-wise Smooth Search,PSS)演算法,相比業界常用的 SmoothQuant,有更好的平滑效果,量化損失更小。 在生成式語言大模型中,啟用的數值分布非常不平滑,導致量化損失較大。相比啟用,權重的數值分布相對平滑,對量化更友好。如下圖所示,(a) 和(b)分別為 Llama 7B 其中一個 FFN2層輸入啟用和權重的數值分布。為了最佳化啟用數值分布,可以將啟用的異常值遷移到權重,使啟用和權重整體的量化損失更小。業界常用的方法是 SmoothQuant,在啟用通道維度上乘以一個平滑系數向量 ,同時在對應的權重上除以相同的平滑系數向量。
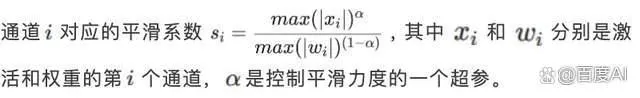
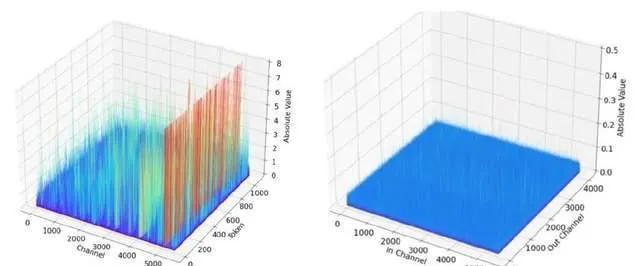

在 PaddleSlim 中實作了此方案,並在 PaddleNLP 中提供了基於 Llama 3.1等模型的完整 壓縮教程 。實驗表明,我們提出的 PSS 演算法處理後的啟用和權重的數值分布均更加平滑,量化精度更高,可以看下圖(a),量化後的精度優於 SmoothQuant。下圖(b)給出了啟用、權重、KV Cache 透過 INT8、FP8量化後的精度值與浮點模型對比情況,可以看到 無論是基於 INT8的 W8A8(C8),還是基於 FP8的 W8A8(C8)精度均接近無失真 。
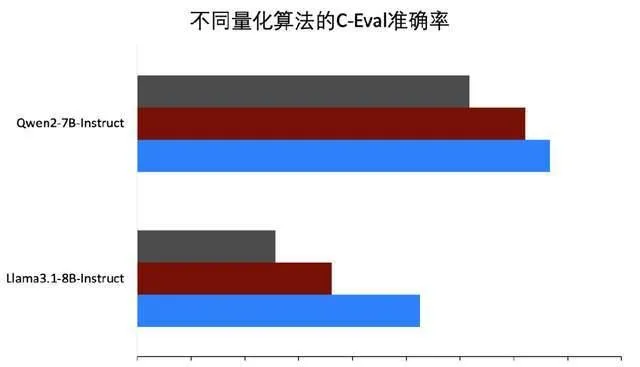
(a) PSS 效果
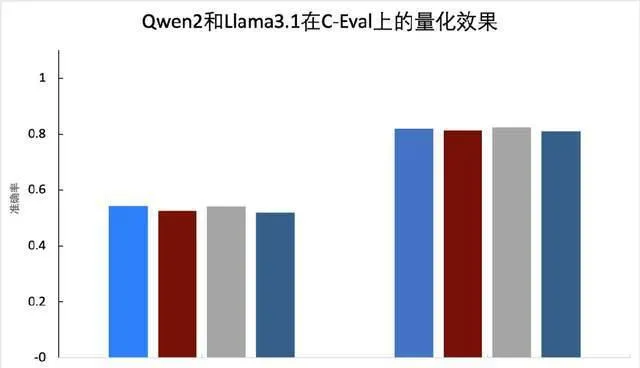
(b) 量化效果
特點二
大語言模型高效能推理最佳化
支持 Llama 3.1 405B 高效能部署
本次更新中,我們基於 PaddleInference 構建了大模型高效能推理方案,支持 Llama 3.0、Llama 3.1、Mixtral 等一系列大語言模型推理 。支持 Weight Only INT8及 INT4推理,支持權重、啟用、Cache KV 進行 INT8、FP8量化的推理,註意力機制支持 PageAttention、FlashDecoding 等最佳化,支持基於 TensorCore 深度最佳化。
FastDeploy 基於輝達 Triton 框架專為伺服器場景的大模型服務化部署設計了解決方案。提供了支持 gRPC、HTTP 協定的服務介面。後端推理引擎采用 PaddleInference,服務與推理協同最佳化,支持流式輸出、異步排程,支持連續批次處理(continuous batching),對 Prefill 與 Decode 的計算混合排程,減少對解碼時延的影響。 在集群化服務部署上,FastDeploy 可靈活控制連續批次處理插入的新請求數量,支持請求動態拉取的方案,實作各例項更好地負載均衡,帶來更低的首 Token 時延和更佳的使用者體驗。
Llama 3.1於7月份剛開源,其中 Llama 3.1 405B 是開源社區中最大的模型,飛槳推理部署也快速支持了此模型,支持 INT8、INT4、FP8的高效能部署,下面是在 PaddleNLP 大語言模型套件中的推理流程。
準備環境
(此處詳細程式碼請進入百度AI公眾號內同篇文章檢視)
模型推理
(此處詳細程式碼請進入百度AI公眾號內同篇文章檢視)
更詳細的內容和最佳實踐可以可以參考文件教程 :
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/predict/inference.md
特點三
跨模態模型一鍵轉靜推理
DiT 擴散模型效能領先
▎一鍵轉靜使用 Paddle Inference 推理介面
飛槳框架的設計上遵循動靜統一的理念,靜態圖的圖最佳化有助於提升推理效能,以往為了使用 Paddle Inference 的靜態圖推理,使用者需要先匯出模型、再編寫推理程式碼,為了更方便使用者直接進行靜態圖推理、或動靜混合方式推理,
推出了
paddle.incubate.jit.inference()介面可一鍵轉靜推理
,並且支持使用 Paddle TensorRT 後端進行推理,具體使用範例如下,可以看到增加一行程式碼即可。在多模態模型的高效能推理加速中,我們也用此功能,透過靜態圖 PASS 最佳化能力獲得加速。
(此處詳細程式碼請進入百度AI公眾號內同篇文章檢視)
▎多模態模型高效能最佳化
多模態模型如 Stable Diffusion 及 DiT 結構在文本生成影像/影片領域、LLaVA 在圖生文領域套用廣泛,飛槳也對這些模型做了高效能推理最佳化。在 LLaVA 等圖生文模型上我們直接套用了大語言模型最佳化技術。針對文生圖及文生影片擴散類模型,我們 提供了豐富的通用圖最佳化,如 Norm 類融合、矩陣橫向融合、FlashAttention 融合高效能算子 。
以 DiT 模型最佳化為例,飛槳框架3.0核心設計PIR減少框架排程開銷,具備更豐富的圖最佳化 PASS,基於這些最佳化可直接提升推理效能。針對 DiT 模型中多個歸一化 Norm 算子與 Elementwise 計算新增了融合最佳化,此外,還透過矩陣橫向融合 PASS 將 GEMM 進行橫向融合計算,使原本零散的小 GEMM 操作,融合為大 GEMM 進行統一計算。還折疊了模型組網中公共子運算式,消除模型多層的冗余計算部份。將 DiT 模型動態圖推理從1325.6738ms 提升至219ms,效能提升6倍。NVIDIA A100 SXM4 40GB 硬件上測試,與 TensorRT-LLM v0.11.0效能相比,DiT 模型推理速度領先10.5%。此外,與 TensorRT v10.0效能相比, SD1.5模型推理速度領先7.9% 。
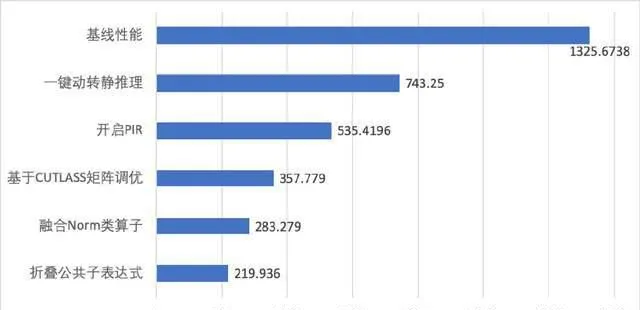
(a) DiT 模型推理最佳化
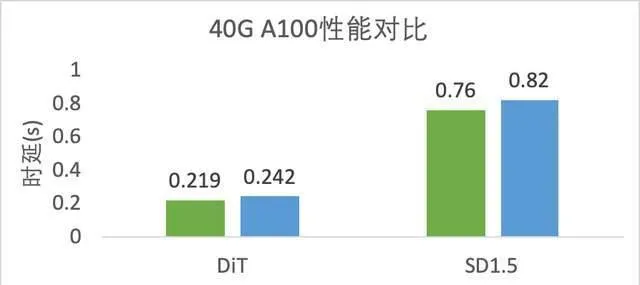
(b) 與 TensorRT/TensorRT-LLM 效能比較
特點四
多硬件大模型推理支持
基於飛槳框架還支持了昆侖XPU、昇騰NPU、海光DCU、燧原GCU、英特爾X86 CPU 等多種硬件的大模型推理, 不同硬件的推理入口保持統一,僅需修改 device 即可支持不同硬件推理 。
▎昆侖XPU 推理:
支持算子級別的融合最佳化,支持 PageAttention、KVCache 等常用大模型最佳化技術,模型算子粒度 API 對齊 GPU,使得動轉靜、推理、服務化部署可以統一支持。
文件傳送門:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/xpu
▎昇騰NPU 推理:
飛槳基於 ATB(Ascend Transformer Boost)構建了昇騰NPU 推理,ATB 推理加速庫是面向大模型領域,實作基於 Transformer 結構的神經網絡推理加速引擎庫,提供昇騰親和的融合算子、通訊算子、記憶體最佳化等,作為公共底座為提升大模型訓練和推理效能,飛槳在此基礎上,還支持了連續批次處理等功能實作推理成本的極致壓縮。
文件傳送門:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/npu/
▎海光DCU 推理:
飛槳對海光DCU-K100AI 大模型推理功能完全對齊 GPU,支持 W8A8C8等多種量化方法,支持 Llama 系列模型,飛槳也對 K100 AI 芯片進行了效能精調,大振幅提升推理效能。
文件傳送門:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/dcu_install.md
▎燧原GCU 推理:
燧原GCU 基於飛槳外掛程式式松耦合統一硬件適配方案(CustomDevice)支持大模型推理,算子層面極致融合最佳化如位置編碼、註意力機制、歸一化算子等,使得大模型推理效能顯著提升。
文件傳送門:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/llm/gcu
▎X86 CPU 推理 :
飛槳 CPU 整合 xFT(xFasterTransformer)加速引擎,基於 xDNN、oneDNN、OMP、x86-SIMD-sort 等加速庫,結合 AVX512、AMX 加速指令,提供 x86架構下高效能推理能力。飛槳 CPU 支持 FP16/BF16、Weight Ony INT8等精度類別推理,支持使用 HBM 加速大模型推理。
文件傳送門:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/llm/docs/inference.md
總結
基於飛槳框架3.0新一代中間表示PIR及更低成本的 PASS 開發機制,飛槳推理部署全面升級,並持續提升大模型推理效能。量化壓縮,支持 INT8、FP8、INT4多種量化精度,支持對大模型權重、啟用、KV Cache 量化的靈活組合,提供 PSS 大模型無失真量化解決方案。推理部署,支持 KV Cache 量化以及 NVIDIA GPU上FP8量化推理,支持 PageAttention最佳化,支持 FlashDecoding 長輸入序列最佳化技巧,支持基於 TensorCore 最佳化註意力機制融合算子。服務部署上,全新升級,支持對自回歸解碼生成模型進行連續批次處理,采用 Prefill 與 Decode 混合排程模式,支持服務與推理異步排程,提供高可用的大模型服務化部署方案。在飛槳 PaddleNLP 大語言模型套件中支持了 Llama 3.1/3.0、Mixtral 等系列大語言模型推理,包括 Llama 3.1 405B 的多卡推理部署。在飛槳PaddleMIX多模態大模型套件中新增 DiT 等擴散模型最佳化。並新增昆侖XPU、昇騰NPU、海光DCU、燧原GCU、英特爾CPU 多硬件的大模型推理最佳化。
▎官方開放課程
7月至10月特設【飛槳框架3.0全面解析】直播課程, 技術解析 加 程式碼實戰 ,帶大家掌握核心框架、分布式計算、產業級大模型套件及低程式碼工具、前沿科學計算技術案例等多個方面的框架技術及大模型訓推最佳化經驗,實打實地幫助大家用飛槳框架3.0在實際開發工作中提效創新!

▎飛槳動態早知道
為了讓優秀的飛槳開發者們掌握第一手技術動態、讓企業落地更加高效,根據大家的呼聲安排史上最強飛槳技術大餐!涵蓋飛槳框架3.0、低程式碼開發工具 PaddleX、大語言模型開發套件 PaddleNLP、多模態大模型開發套件 PaddleMIX、典型產業場景下硬件適配技術等多個方向,一起來看吧!

溫馨提示:以上僅為當前籌備中的部份課程,如有變動,敬請諒解。
▎拓展閱讀
【飛槳官網】
https://www.paddlepaddle.org.cn/
【企業合作入口】
https://paddle.wjx.cn/vm/m3sxpfF.aspx#











