衡宇 發自 凹非寺
量子位 | 公眾號 QbitAI
一筆近5個億新融資,投向AI大模型領域。
量子位獨家獲悉,清華系AI創業公司無問芯穹
完成了近5億元
A輪融資
。加碼的股東陣容很全、很豪華:
一口氣新增15家股東,涵蓋北京上海等地的國資/地方基金
,順為資本/達晨財智等市場化頭部VC
,還有券商直投
和產業CVC
。
至此,這家成立1年零4個月的創業公司,已經累計融資近10億元
。
該公司沒有透露最新估值。但更具風向意義的是,據統計,這已經是目前國內大模型賽道累計融資額最高的AI Infra公司。
沒有之一。
那麽,問題來了——如此吸金的AI創業公司,是怎麽煉成的?
無問芯穹聯合創始人、CEO夏立雪,在對話中給出了答案。
融這麽多的錢的,為什麽是無問芯穹?
去年5月31日,無問芯穹成立。
但這家公司在AI領域積澱的開端遠在這一天之前。
準確來說,團隊生根於清華NICS-EFC實驗室
。該實驗室成立於2008年,全稱「Nanoscale Integrated Circuits and System Lab, Energy Efficient Computing Group」,專註於電子工程領域。
該實驗室的領導者,正是無問芯穹的發起人、也是這家公司的靈魂人物:清華電子系系主任——汪玉。
夏立雪是汪玉的學生,是汪玉做博導後帶的博士;聯合創始人、CTO顏深根同為清華人,現在是電子工程系副研究員,曾任商湯科技數據與計算平台部執行研究總監,帶隊搭建過萬卡集群。
聯合創始團隊中的另一位重要成員,首席科學家、上海交通大學長聘教軌副教授戴國浩,當初也是從清華電子系拿下學士及博士學位。
怎麽說呢,這個陣容,就真的很清華(電子)。
這幾人帶隊,在無問芯穹組建了150多人的隊伍,其中100多人專註於AI大模型軟硬件技術研發。
此謂人和。

咱們再繼續來說清華NICS-EFC實驗室。
往前看,2016年時,這個實驗室成功孵化出AI芯片公司深鑒科技,兩年後,深鑒被全球最大的FPGA(可編程芯片)廠商賽靈思以3億美元收購。
深鑒科技走的路線是從演算法等軟件層面提升芯片效率,而其「發源地」NICS-EFC實驗室,一直有另一條不同的路線:
協同軟硬件,做聯合最佳化。
夏立雪說,這條路線的價值在AI 1.0時代很受掣肘。
因為泛化能力不足,每個小場景都需要量體裁衣般單獨最佳化,需要一個特定的模型。
不過,2022年底,ChatGPT問世,大模型時代即AI 2.0時代轟轟烈烈開始了。
「大模型的出現是一個重要轉折點,因為它能用相同的模型來支持不同的場景。」夏立雪解釋道,「這樣一來,我們之前積累的經驗和技術只需進行一次最佳化,就能解決多個場景的需求。」
與此同時,AI 2.0也給AI Infra層帶來了更大的未來價值。
現在,可能只需付出20%的努力,就能支撐80%的場景。
大模型時代的到來,無疑給無問芯穹的成立和後續發展帶來了「天時」。
而無問芯穹之所以備受市場看好,除了上述的人和、天時,地利也不可或缺。
當下的形勢,外部算力入口變細,而國內芯片仍處於成長期。
不完全統計,宣布擁有千卡規模的中國算力集群已不少於100個,絕大部份集群已經或正在從同構轉向異構。
現在國內的算力有種好像既供大於求,又供小於求。
算力中心不知道該賣給誰,同時很多人又需要使用已經被產品化的「電」來做各種事情的。
骨感而特殊的本地需求,迫切呼喚有人能把不同廠商的異構芯片資源整合起來,發揮出最高效率。
「唯一具備全棧技術能力的創業團隊」
於是此次宣布的A輪、四種資方入股的投資,也算是無問芯穹做這件事的底氣所在。
無問芯穹自己算了一筆賬,提出了一個AI模型算力公式:
芯片算力 × 最佳化系數(軟硬協同)× 集群規模(多元異構)= AI模型算力

這個公式有三個影響因子:
芯片算力:
指單芯片的理論算力,可以用單位能量的乘法計算數量來衡量。
最佳化系數:
指在單芯片算力有限的情況下,無問芯穹透過軟硬件聯合最佳化,提升芯片算力的利用效率,讓單芯片在任務上發揮出更大價值。
集群規模:
指無問芯穹透過多元異構算力適配技術,喚醒更多沈睡算力,擴大行業可用的整體算力規模。
這一公式最終結果,代表著國內能夠支撐的AI的體量。具體的值的意義,遠不如其所提供的一種認知,即軟硬件協同設計與多元異構適配,能夠在產業鏈中提供何等價值。
算力市場空間之廣闊有目共睹,理所當然的,背後的技術層棧要求也很高。
無問芯穹要實作模型與算力垂直打通,決心打造全棧技術能力。
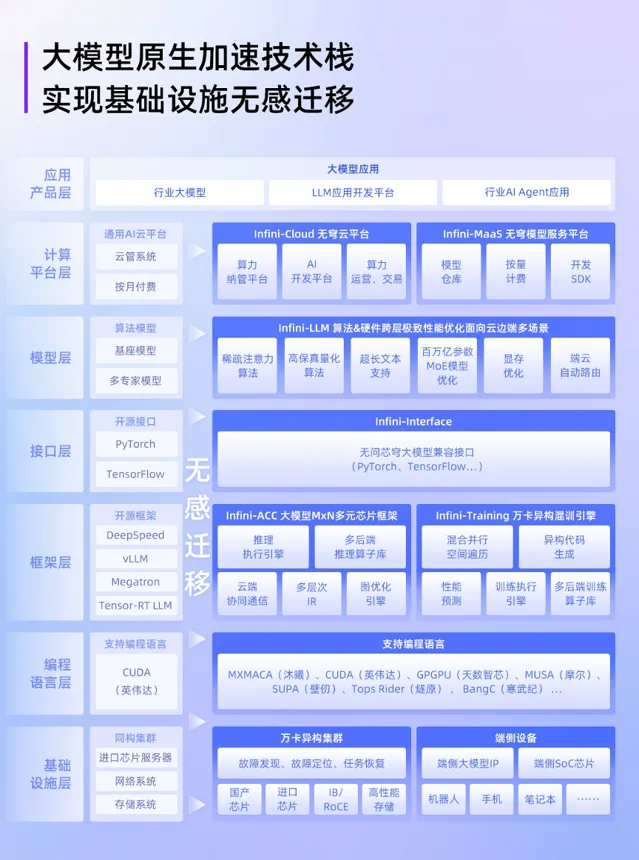
為什麽要做技術全棧?
首先,無問芯穹自問能做好。
從上層模型套用到底層算力硬件,能拆出好幾個層次來,包括集群層面、模型任務最佳化層面、框架層面、算子層面、硬件客製化和最佳化層面。
夏立雪分享到,過去一年裏,團隊已經積累了100多位技術成員,「我們是國內除大廠外,唯一具備全棧技術能力的團隊。」
其次,全棧技術有助於提供產品化服務。
具體案例是無問芯穹在今年釋出的Infini-AI異構雲平台。
它整合了全球首個支持單任務千卡規模異構芯片混合訓練平台,具備萬卡擴充套件性,支持包括AMD、華為異騰、 天數智芯、沐曦、摩爾執行緒、NVIDIA這6種芯片在內的大模型混訓,可一鍵發起700億參數大模型訓練。
向上直接對接各種集群,向下讓做模型和用模型的人簡簡單單就能用起來,打通中間層,這就是無問芯穹最主要的差異點。
這一思路還體現在無問芯穹的核心理念上。
自創業之初,「MxN」就是他們的核心理念。
什麽是「MxN」?就是打破不同芯片不同模型的阻隔,透過軟硬件協同最佳化的手段,實作M種模型和N種芯片的整合統一。
展開來說,是透過提供高效整合異構算力資源的好用算力平台,以及支持軟硬件聯合最佳化與加速的中介軟體,來達到大幅提升主流硬件和異構硬件利用率的目的。
打造一個AI原生的基礎設施,適應多模型、多芯片格局,最終讓異構芯片的算力表現媲美(甚至超過)輝達。

值得註意的是,無問芯穹很早就喊出了自己的目標:
實作大模型落地成本10000倍下降。
據了解,無問芯穹基本已經做到了1000倍下降。這1000倍是針對大模型,結合了在演算法層、硬件層、軟件層多個層次的聯合最佳化。
也正是因為做了跨層次聯合最佳化,才能產生「化學效應」,實作在模型層做壓縮,對應的在硬件層真實實作這些壓縮的加速算子。
不過,千倍和萬倍看上去只有一個「0」的差異,但並非多走幾步就能達成。
夏立雪表示:「我們已經實作了較深層次的軟硬協同,再往‘萬倍成本下降’會涉及到硬件,也就是說,若要實作模型與硬件的深度耦合,必須對硬件結構進行相應的調整
。」
所以,真正邁向成本萬倍下降,需要與芯片廠商共同在終端套用場景中探索並設計適應新需求的芯片結構。這不僅僅是一個理論上的構想,還需要真正投入到新芯片的設計和流片過程中。
這無疑是一個巨大的專案。
對此,無問芯穹表示,A輪融資所得款項中,有一部份將專門用於探索端上模型與端芯片的融合落地專案。
One More Thing
在商業模式上,無問芯穹沒有走最常見的軟件付費模式。
而是選擇了成為一個「淘寶」。
做智算領域的營運商,把軟件直接嫁接在各種集群的硬件基礎之上,賣tokens。
國內AI大模型領域頭部梯隊的許多熟面孔,譬如智譜AI、Kimi、生數等,都是它的客戶。
從這個角度講,無問芯穹已經初步搞定了在技術能力、產品能力、業務能力和商業模式的驗證。
下一步,無問芯穹的選擇是進行規模擴充套件。











