AI漫長的歷史中,ChatGPT絕對是濃墨重彩的一筆。正是它引爆了AI大模型概念,也讓以往高高在上的AI飛入了尋常百姓家,開始融入每個人的日常工作、生活,AI PC、AI手機、AI邊緣也都在大踏步前進,變革千行百業。
有調研數據顯示,預計到2026年,AIGC相關投入將超過3000億美元,到2028年,80%以上的PC都會轉換成AI PC,而在邊緣套用中AI的普及率也將超過50%。

AI大模型等套用最需要的當然是高算力,GPU加速器隨之變得炙手可熱,但是AI的發展與變革同樣是多元化的,CPU通用處理器、NPU神經網絡引擎也都在各司其職,貢獻自己的力量。
尤其是傳統的CPU,也在緊跟時代的腳步,全方位擁抱AI,Inte第五代至強(Emerald Rapids)就是一個典型代表。

Intel 2023年初釋出的第四代至強(Sapphire Rapids),年底就升級為第五代,速度之快前所未有,主要就是為了跟上形勢,尤其是AI的需求,很多指標都是為此而最佳化的。
這包括更多的核心數量、更高的頻率、更豐富的AI加速器,都帶來了效能和能效的提升,對於AIGC非常有利。
還有多達3倍的三級緩存,可以減少對系統記憶體的依賴,記憶體頻寬也同時進一步提升。
軟件生態方面,Intel提供了全方位的開發支持與最佳化,尤其加大了對主流大模型、AI框架的支持,特別是PyTorch、TensorFlow等等,在AI訓練、即時推理、批次推理等方面,基於不同演算法,效能提升最多可達40%,甚至可以處理340億參數的大模型。

根據Intel提供的數據,五代至強SPECInt整數計算效能提升21%,AI負載效能提升最多達42%,綜合能效也提升了多達36%。
具體到細分領域,影像分割、影像分類AI推理效能提升最多分別42%、24%,建模和模擬HPC效能提升最多42%,網絡安全套用效能提升最多69%。
網絡與雲原生負載能效提升最多33%,基礎設施與儲存負載能效提升最多24%。
有趣的是,Intel指出五代至強也有很高的性價比,其中一個評估標準就是同時支持的使用者數,五代至強可以在BF16、INT8精度下同時滿足8個使用者的即時存取需求,延遲不超過100ms。
五代至強的優秀,也得到了合作夥伴的驗證,比如阿裏雲、百度雲都驗證了五代至強執行Llama 2 700億參數大模型的推理,其中百度雲在四節點伺服器上的結果僅為87.5毫秒。
再比如京東雲,Llama 2 130億參數模型在五代至強上的效能比上代提升了多達50%。


接下來,Intel至強路線圖推進的速度同樣飛快,今年內會陸續交付Granite Rapids、Sierra Forest兩套平台,均升級為全新的Intel 3制程工藝。
其中,Sierra Forest首次采用E核架構,單芯片最多144核心,雙芯整合封裝能做到288核心,今年上半年就能問世。
Sierra Forest主要面向新興的雲原生設計,可提供極致的每瓦效能,符合國家對器材淘汰換新的要求,而且因為內核比較精簡,可以大大提高同等空間內的核心數量。
緊隨其後的Granite Rapids,則依然是傳統P核設計,具備更高頻率、更高效能。
Granite Rapids針對主流和復雜的數據中心套用進行最佳化,尤其是大型程式,可以減少對虛擬機器的依賴。
到了2025年,Intel還會帶來再下一代的至強產品,代號Clearwater Forest,無論制程工藝還是技術特性抑或效能能效,都會再次飛躍。

那麽問題就來了,Intel至強的更新換代如此頻繁,尤其是五代至強似乎生命周期很短,它究竟值不值得采納部署呢?適合哪些套用市場和場景呢?
五代至強釋出之初,Intel從工作負載最佳化效能、高能效計算、CPU AI套用場景、營運效率、可延伸安全功能和質素解決方案五個方面進行了介紹。
現在,我們再換一個維度,從另外五個方面了解一下五代至強的深層次價值。
一是制程工藝改進。
五代、四代至強都是Intel 7工藝,都采用了Dual-poly-pitch SuperFin晶體管,但也改進了關鍵的技術指標,特別是在系統漏電流控制、動態電容方面,它們都對晶體管效能有很大影響。
透過這些調整,五代至強在同等功耗下的整體頻率提升了3%,其中2.5%來自漏電流的減少,0.5%來自動態電容的下降。
二是芯片布局。
受到芯片整合復雜度、制造技術的限制,現在主流芯片都不再是單一大芯片,而是改為多個小芯片整合封裝。
四代至強分成了對稱的四個部份,做到最多60核心,五代至強則變成了映像對稱的兩部份,核心數反而提升到最多64個。
之所以如此改變,是因為切割的小芯片越多,彼此互相通訊所需要的控制器、介面和所占用的面積也更多,還會額外增加功耗,並降低良品率。
透過芯片質素控制,五代至強可以更好地控制芯片面積,並且在相對較大的面積下獲得很好的良率,映像對稱的布線也更靈活。

這是五代至強單個芯片的布局圖,可以看到中間是33個CPU核心和二三級緩存,其中一個核心作為冗余保留。
左右兩側是DDR5記憶體控制器,上方是PCIe、UIPI控制器,以及DLB、DSA、IAA、QAT等各種加速器,底部則是EMIB封裝和通訊模組,用於雙芯片內部高效互連。
說到連線,五代至強使用了高速內部互連Fabric MDF,包括七個SCF(可延伸一致性頻寬互連),每一個都有500Gbps的高頻寬,讓兩顆芯片在邏輯上實作無縫連線。

三是效能與能效。
看一下五代至強的關鍵效能指標:
- CPU架構升級到Raptor Cove,13/14代酷睿同款。
- 核心數量增加,最多60核心來到最多64核心。
- 三級緩存擴容,平均每核心從1.875MB增加到5MB,這是歷代提升最大的一次。
- DDR5記憶體頻率從4800MHz提升到5600MHz。
- UPI總線速度從16GT/s提供到20GT/s。。
- 芯片拓撲結構更改,四芯片封裝改為雙芯片。
- 待機功耗降低,透過全整合供電模組(FIVR)、增強主動空閑模式等技術實作。

四是三級緩存。
至強處理器以前每核心的三級緩存都只有1-2MB,這次直接來到了5MB,總容量最多達320MB。
在數據集不是很大的情況下,三級緩存本身就可以基本承載,無需轉移到系統記憶體,從而帶來極大的效能提升。
但是,緩存容量並不是單純堆起來的,因為大緩存會面臨可靠性問題,尤其是在大規模數據中心裏存在一個位元反轉的軟故障,緩存越大,故障機率越高,當錯誤足夠多而無法糾正的時候就會導致系統宕機。
這就需要超強的糾錯機制,五代至強就采用了新的編碼方式DEC、TED,一個緩存行出現兩個位錯誤的時候也可以糾正,三個位錯誤的時候也可以檢測,比傳統單位糾錯、兩位檢錯有著更強的容錯性,此外還有一些新的數據修復方案。
五是記憶體IO。
DDR5-4800升級到DDR5-5600,看似振幅不大,但其實很不容易,因為記憶體速度提升後,從芯片到基板需要全線進行最佳化匹配,包括供電和噪音控制等。
為了保證高頻下的訊號完整性,五代至強還加入了4-tap DFE功能,盡可能減少碼間幹擾(ISI)。
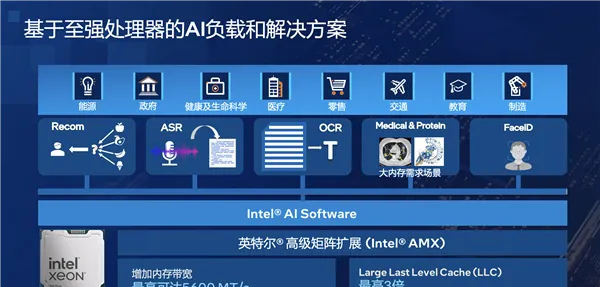
最後再單獨說說基於至強這樣的通用處理器的AI負載套用,以及相應的解決方案。
其實,AI套用並非只是大模型,還有大量的傳統非大模型AI套用,都非常適合在CPU上部署。
比如基因測序這樣的科學計算,2018年至今,至強每一代都有顯著提升,因為科學計算很多時候就是「暴力」計算,最考驗CPU的處理能力。
除了硬件上的支持,Intel還有強大的軟件生態最佳化,包括基於OpenVINO對整個模型進行最佳化、量化,在推薦、語音辨識、影像辨識、基因測序等方面Intel都做了大量的最佳化。
比如模型非常大的推薦系統、稀疏矩陣等套用,CPU的效率其實優於GPU,因為單個GPU不夠用的時候就得跨GPU,或者和CPU頻繁互動傳輸,而在與記憶體互通方面CPU的效率是更高的。
其他像是網絡、數據服務、儲存等等,至強無論效能還是能效都在行業處於領先地位,更關鍵的是系統故障率非常低。

對於通用的AI工作負載,Intel采用了AMX、AVX-512兩個指令集,並基於OpenVINO進行最佳化。
AMX適合處理BF16、INT8數據類別,比如推薦系統、自然語言處理、影像辨識與目標檢測等等。
AVX-512適合處理FP32、FP64數據類別,比如數據分析、機器學習等等。
在推理的過程中,指令集還可以進行靈活切分,透過加速器定向加速某一部份,替代基於GPU的AI模型是完全沒有問題的。
事實上,AI只是工作負載的一部份,更多的是通用負載,很多深度學習模型也都是「混合精度」,四代、五代至強執行它們的時候都可以根據需要在AMX、AVX-512之間靈活無縫切換。
針對大模型的加速,Intel也推出了自己的框架BigDL LLM,有很多框架層針對CPU進行了大量的最佳化,並針對模型做了量化。
另外,Intel擁有開放的生態,行業夥伴和友商都可以直接納用,這對Intel自身來說也是一件好事,可以帶動整個生態的發展,讓Intel的解決方案得到更廣泛的普及。
總的來說,在這個AI時代,CPU、GPU、NPU等各種計算引擎都有自己的獨特優勢,都有自己的適用場景和領域,不存在誰取代誰,更多的是靈活的選擇與協同的高效,需要結合具體業務的能效、成本等多方面綜合考慮。
CPU作為最傳統的通用計算引擎,始終都會占據不可替代的地位,無論是作為整個計算平台的中心樞紐,還是對各種通用負載、AI負載的靈活處理,未來依然可以橫刀立馬!












