他曾經參與Q*專案,是這個創新技術的創造者之一。
當記者追問Lukasz Kaiser關於Q*的更多細節時,OpenAI的公關人員差點跳起來捂住他的嘴。他們顯然不想讓這個話題繼續下去。

柯曼在接受采訪時,很幹脆地拒絕了有關問題的回答,他說:「我們現在還不想說這個話題呢。」意思很明確,他們還沒準備好公開討論這件事。
OpenAI現在得把神秘Q*當作頭等大事來保密。這玩意兒太重要了,一旦泄露出去,後果不堪設想。所以,大家都得緊咬牙關,打死也不能說出去!
Noam Shazeer,也就是現在Character.AI的創始人,其實才是谷歌在生成式AI領域最大的功臣。早在2012年,他就參與了谷歌的生成式AI搜尋專案。到了2017年,他還提出了訓練萬億參數大模型的建議,不過可惜,這個建議沒得到公司高層的認可。總的來說,他提供的資訊比那些在商業論壇上互相吹捧的大佬們有價值多了。
【Attention is all you need】這篇文章是在2017年發表的,現在已經被參照了超過11萬次,可見它的影響力有多大。簡單說,這篇文章就是告訴我們,只要我們集中註意力,就能做好很多事情。所以,大家要記得哦,註意力可是成功的關鍵呢!

這不僅僅是大模型技術的起源之一,像是ChatGPT這樣的。它裏面提到的Transformer架構和註意力機制,也都用在了許多讓世界發生改變的AI技術上,比如Sora和AlphaFold。這真的是個傳奇,毫無疑問!
谷歌為什麽能取得這麽棒的成果呢?但為啥後來在大模型比賽中又沒能保持領先呢?
2012年,整個故事就此展開。
【谷歌害怕Siri搶飯碗】
2011年底,蘋果釋出了Siri,它的目標就是在對話中回答你的問題。Siri可以幫你解決各種問題,你只需要跟它對話就可以了。
谷歌高層現在超級緊張,覺得Siri可能會把他們的搜尋流量給搶走了。
2012年那會兒,有個團隊挺拼的,他們就想著在搜尋頁面上直接回答大家的問題,不用再點選啥連結跑到別的網站去。就這樣,他們努力開發新功能,希望能給大家提供個更方便的搜尋體驗。
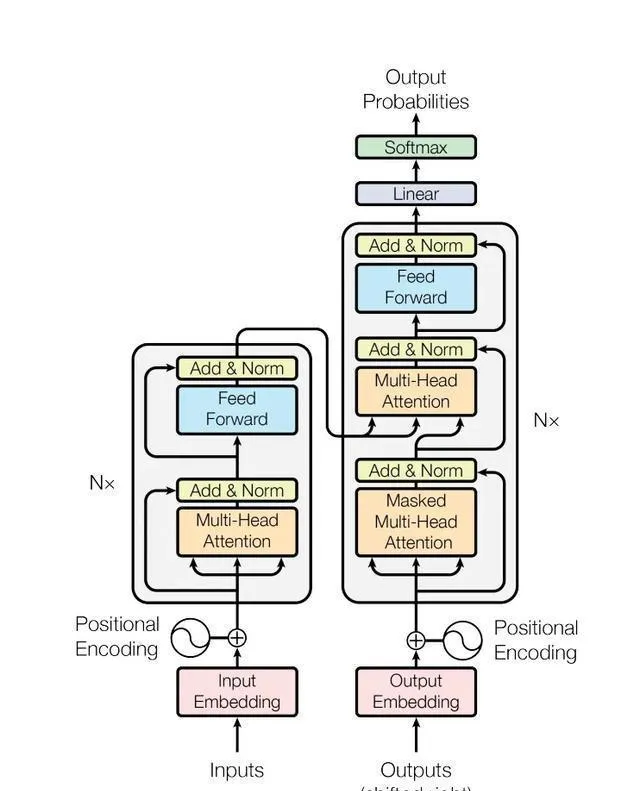
最後,這些努力終於催生出了Transformer架構,這個架構真的很神奇,它能在數據和算力上不斷擴充套件,給整個AI領域帶來了巨大的突破。簡單來說,就是因為這個架構,AI變得更加強大和靈活了。
在那個時候,Jokob Uszkoreit(現在是AI生物技術公司Inceptive的聯合創始人)決定放棄攻讀博士學位,加入了這個團隊。他的加入,可以說是Transformer專案的最初起點。
他是個地道的德國人,碩士學歷,是在柏林工業大學完成的。他老爸Hans Uszkoreit,在語言學界可是個響當當的人物,不僅是個著名的計算語言學家,還是歐洲科學院的院士呢。

烏茲哥現在回想起來,覺得谷歌高層當初對Siri那麽緊張真是小題大做了。事實上,Siri從來就沒能給谷歌帶來什麽真正的威脅。不過話說回來,他也挺高興有這個機會深入鉆研人工智能和對話系統的。
2012年,AlexNet在電腦視覺領域大放異彩,引領了神經網絡的復興。谷歌公司看到了這個機會,於是鼓勵員工嘗試類似的技術。他們希望利用這些技術,開發出能夠自動補全電子郵件的功能,或者建立一些相對簡單的客戶服務聊天機器人。可以說,谷歌在那一年裏,對神經網絡和人工智能充滿了期待和熱情。
那個時候,大家都覺得長短期記憶網絡LSTM是個挺好的方案,但這個辦法有個問題,就是它只能一個接一個地處理句子,不能提前看到文章後面可能有啥線索。這樣一來,它就不能充分利用文章裏的所有資訊了。
大約在2014年,烏茲哥開始嘗試一種新方法,也就是現在大家所熟知的「自註意力」方法。
【註意力機制誕生】
烏茲哥覺得,自註意力模型或許比迴圈神經網絡還要快、還要好使,而且它處理資訊的方式特別合GPU的胃口,因為GPU擅長並列處理嘛。
不過那時候,很多人包括他的那個學術大神級別的老爸都覺得這是個不靠譜的選擇,覺得放棄迴圈神經網絡就像是走上了歪路。
烏茲哥費了不少勁,終於讓幾位同事同意嘗試他的新想法,並在2016年成功發表了一篇論文。

這個研究其實只用了很少的文字訓練,就是那個SNLI數據集,裏面大概有57萬個英語句子,都是人寫的。
別的研究人員就像是參加答題闖關遊戲,答對一題就拿了點小獎金然後走人。但烏茲哥不一樣,他覺得自註意力機制還有更大的潛力。於是,他在公司裏到處找人,想把他的想法推銷出去。
在2016年的一天,他終於遇見了誌趣相投的Illia Polosukhin,也就是現在區塊鏈公司NEAR Protocol的創始人。

【集齊8位元圓桌騎士】
菠蘿哥在谷歌已經打拼了三年,他所在的團隊是專門負責給搜尋問題提供直接答案的。
菠蘿哥碰到了一些挑戰,因為使用者希望他們的問題能在幾毫秒內得到回應。但是,那時候還沒有一個能滿足這麽快速回應需求的解決方案。所以,菠蘿哥的工作進展就沒那麽順利了。
烏茲哥和菠蘿哥一起吃飯,聊著聊著就聽說這事兒了。烏茲哥一聽,立馬就大力推薦他的自註意力機制。他覺得這個方法真的很不錯,所以就毫不猶豫地安利給了菠蘿哥。
菠蘿哥曾經說過,他覺得A自註意力特別像科幻小說【你一生的故事】和電影【降臨】裏那種外星人「七肢桶」的語言。那種語言沒有先後順序,而是像幾何圖案那樣排列的。他覺得特別有意思,就像是一種全新的思考方式。

總之啊,菠蘿哥最後不僅答應試試看,還找來了第三位小夥伴Ashish Vaswani一起合作。他們倆一起先後創辦了Adept AI和Essential AI,真是挺厲害的!
瓦斯哥是個印度人,他在南加州大學讀完博士之後,就加入了谷歌大腦。他覺得神經網絡這東西特別厲害,能幫助人類更好地理解這個世界。

這三位研究人員一起制定了Transformer的設計文件。從一開始,他們就決定使用「變形金剛」這個名字,這個名字有兩層意思。一方面,他們希望這個系統能像變形金剛一樣,能夠靈活地改變接收到的資訊。另一方面,這個名字也來源於菠蘿哥小時候喜歡玩變形金剛玩具的經歷,算是他們之間的一個小插曲。
菠蘿哥在谷歌待了沒多久,就決定離開去創業了。與此同時,其他的小夥伴們也陸續加入了這個小團隊。大家一起努力,一起奮鬥,為了實作共同的夢想而不斷前進。
2017年初,有個叫Niki Parmar的人(我們就簡稱她為帕姐)加入了進來。她和瓦斯哥都是印度人,也都上過南加州大學,之後兩人還一起創業。

後面幾位成員加入的方式都有點兒出乎意料,挺有戲劇性的。
英國小夥子Llion Jones(我們親切地叫他囧哥)2009年從伯明翰大學碩士畢業,但剛開始那幾個月找工作挺費勁的,只能靠著救濟金過日子。不過,他並沒有放棄。2012年,他先加入了Youtube團隊,後來又進了谷歌研究院,可以說是混得風生水起。
他是團隊裏最後一個離開谷歌的,去年在日本建立了Sakana AI這家公司。

囧哥是從同事Mat Kelcey那裏聽說Transformer的,但Kelcey對這個專案並不太看好。
Kelcey是個貝葉斯理論的信徒,他的頭像顯示AI認為他有60%的機率是個技術高手。但後來他意識到,自己沒能加入Transformer團隊,才是他這一生中最大的遺憾。
話說回來啊,那個Aidan Gomaz,就是第六位大佬,大家都叫他割麥子。他可是現在AI公司Cohere的創始人哦。這個割麥子可真是個天才,他在多倫多大學讀大三的時候就加入了Hinton的實驗室。他可不是那種等著別人來找他的人,他主動給谷歌裏那些寫過超有趣論文的大佬們發郵件,申請合作。這就是割麥子的厲害之處,年紀輕輕就這麽有幹勁和眼光!

有一天,Lukasz Kaiser(我們簡稱他為凱哥,他現在在OpenAI當研究員)找到割麥子,說想讓他來實習。過了幾個月後,割麥子才後知後覺地發現,原來這個實習是專門給博士生準備的,他一個本科生本來是沒資格參加的。

凱哥是從波蘭來的,他原本從事的是理論電腦方面的工作。但後來,他和另一位合作夥伴發現,自註意力這個概念對他們正在研究的分布式計算的大型自回歸模型問題來說,是個非常有前途並且比較激進的解決方案。於是,兩人決定加入Transformer團隊,一起探索這個新的方向。
當這六個人(菠蘿哥已經開始了自己的創業之路)聚在一起時,團隊決定把研究的焦點放在機器轉譯上。他們用BLEU基準測試來對比機器轉譯的結果和人工轉譯的效果,以此評估模型的效能。這樣,他們就可以知道機器轉譯的效果如何,並與人工轉譯做個比較。
早期版本的Transformer表現還挺不錯的,但跟LSTM方案比起來,其實也就差不多,沒有特別突出的優勢。
這時,我們的第八位重要人物Noam Shazeer(我們就叫他沙哥吧)閃亮登場了。他在杜克大學讀完書後,2000年就加入了谷歌,那時候整個公司才200人左右,
後來他成了谷歌內部的傳奇大佬,參與了谷歌搜尋的拼寫修改功能,還管過早期的廣告系統。在2021年,他離開了谷歌,創辦了Character.AI。

沙哥說,他當時正在辦公樓走廊裏閑逛,剛走到凱哥旁邊,就聽見瓦斯哥和帕姐在激烈討論。瓦斯哥在解釋怎麽運用自註意力,帕姐聽起來特別激動。
沙哥原先就覺得,這是一群既聰明又有趣的人在搞一個很有前途的專案。後來,在凱哥的一番勸說下,沙哥決定加入他們,一起幹這件大事。
經過漫長的等待,現在,8位元傳奇人物都已經亮相了,真是讓人興奮啊!
【沖刺NIPS】
沙哥的作用太關鍵了,他憑借自己的想法對整個程式碼進行了大改造,直接讓系統煥然一新,上了一個新台階。
團隊一下子變得鬥誌昂揚,大家都開始全力以赴,想要在2017年NIPS(後來更名為NeurIPS)的截止日期5月19日之前完成任務。他們充滿了動力,都在拼命努力,希望能夠按時完成工作。
離截止日期還有兩周時,他們幾乎整天都待在辦公室,就在咖啡機旁邊,幾乎沒怎麽睡過覺。
作為實習生,割麥子在不斷地嘗試和偵錯,像瘋了一樣探索各種技巧和網絡模組的排列組合,希望能找到最佳的組合方案。他認真地對待每一個細節,不斷嘗試,以期望能夠在這個領域獲得更好的表現。
最後啊,在沙哥的指導下,我們搞出了現在這個大家都熟悉的Transformer架構,真的是超級「簡約」啊,比試驗中其他的方案都簡潔多了。他們都說:
Noam,我們都叫他沙哥,他可是個有魔法的家夥,就像巫師一樣!
沙哥真是個高手,但他自己可能都沒意識到。當他看到論文的草稿,發現自己竟然是第一作者時,他還真挺吃驚的。
商量了半天,他們決定不按照學術界那種一作二作通訊作的規矩來了,而是隨機排個序。為了表示大家都做出了平等的貢獻,他們還在每個人的名字後面都加了個星號,並在註腳裏特別說明大家都是平等的貢獻者。這樣一來,誰也別想爭個高下,大家都平等對待。
在大家討論論文標題的時候,英國小哥出了一個主意,他覺得可以借用披頭四樂隊的歌【All You Need Is Love】,然後改成【Attention is all you need】。大家覺得這個想法不錯,就一致透過了。

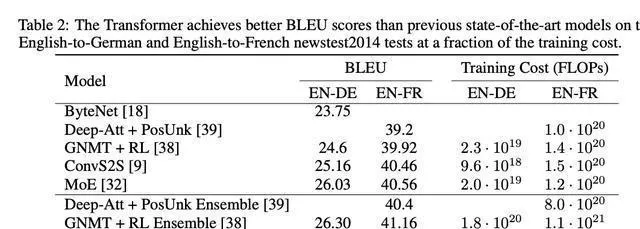
他們開發了兩個模型,一個叫基礎版,一個叫大杯版。基礎版雖然只有65M,但卻能把其他同級選手都甩在身後。而那個213M的大杯版呢,更是厲害,它打破了BLEU測試的紀錄,而且運算起來還特別快。簡單說,這兩個模型都很棒,但大杯版尤其出色!
直到截止時間快到了,他們還在緊急地整理實驗結果。最後一刻,英法轉譯的數據才搞定,論文也是在最後關頭,只剩下兩分鐘的時候才送出的。
那次學術會議上的審稿人反應各不相同。第一個審稿人覺得論文還不錯,第二個審稿人評價非常高,而第三個審稿人只是簡單說了句「還可以」。
到了12月,當會議真的線上下舉行時,這篇論文瞬間引發了熱議。那個4小時的會議場地,簡直擠滿了渴望深入了解的科學家們。
谷歌當年的開放包容文化,對於Transformer的誕生歷程來說,是不可或缺的。可以說,正是這種文化氛圍為Transformer的誕生提供了肥沃的土壤。所以,要感謝谷歌的開放包容,才有了Transformer的今天。
這八個人能夠聚在一起,其實都是因為走廊裏偶然的一次相遇和午餐時的幾句閑聊。
【OpenAI摘桃子】
有一天,瓦斯哥在寫論文的時候,實在是太累了,整個人癱在辦公室的沙發上。他眼睛盯著窗簾看,竟然看出了幻覺,覺得那窗簾上的圖案看起來就像是大腦裏的突觸和神經元一樣。
那天他突然醒悟,他們正在做的事情不只是簡單的機器轉譯,而是有著更大的潛力和意義。
最終的目標就是能像人腦那樣,把語音、視覺等各種資訊都整合到一個統一的架構裏。這樣,我們就能更好地理解和處理各種資訊,讓機器變得更加智能和高效。
沙哥真是很有遠見啊,在套用方面他想得特別遠。就在他發表論文前後,他就給谷歌的高管寫了一封信,展示了他的想法。真是佩服他的勇氣和眼光!
他覺得公司應該放棄整個搜尋索引,然後訓練一個超大的神經網絡,這個神經網絡用的是Transformer架構。他這個想法基本上是要谷歌徹底改變他們組織資訊的方式。簡單來說,他就是建議谷歌大刀闊斧地改革一下。
當時凱哥他們都覺得這個想法挺離譜的。可現在一看,谷歌不就是往這個方向使勁兒嗎?就是時間早晚的問題了。
烏茲哥後來想了想,其實在2019年或者2020年,谷歌本來是有機會推出像GPT-3,甚至是GPT-3.5這麽牛的模型的。然後他提出了一個讓人深思的問題:
我們看到了希望,為啥就不試著去實作呢?
結果出乎意料,對手OpenAI的首席科學家Ilya Sutskever在論文釋出的那天就意識到了這個成果的重要性,他覺得「這正好是我們一直想要的」,於是他鼓勵同事Alec Radford立即開始對這個專案進行深入研究。
Radford最初搞出了GPT的雛形,後來OpenAI調集了一大幫人馬,有的是搞機器人的,有的是玩DOTA遊戲的,大家都轉行過來一起開發。於是就有了GPT-1、GPT-2……這些就是另外一回事兒了。
Transformer架構的初衷,就是要設計出一個能在數據和算力上都實作擴充套件的模型,而這也正是它成功的秘訣。簡單說,就是要讓它既可以處理更多的數據,又可以應對更大的計算量,這樣模型才能更加強大、準確。
但如果沒有高層的規劃和推動,谷歌可能就只能停留在這個階段了。單靠員工自己的努力,已經無法滿足「Scaling Law」持續發展所需的人力、物力和財力了。換句話說,如果沒有高層的支持和指導,谷歌的發展可能會受到限制,因為單靠員工的力量是不足以支撐整個公司的發展需求的。
OpenAI的組織方式真是獨特,它既能做到從下往上那種靈活多變,又能保持從上往下那種一心一意。有了這種結合,他們在這條路上走得更遠,那幾乎是板上釘釘的事兒了。
OpenAI的CEO柯曼曾經說過,他覺得谷歌的高層好像都沒明白Transformer到底有多重要。
除了菠蘿哥那家最早結束的區塊鏈公司,其他成員後來都加入了和Transformer有關的專案。
2019年那會兒,有個實習生才剛畢業沒多久,就帶頭搞起了Cohere這個公司。他們主要給企業提供大模型的解決方案,現在這家公司已經值22億美元啦!真是個挺厲害的小夥子!
從2021年開始,團隊成員陸續選擇離開。
瓦斯哥和帕姐可真是不簡單,他們倆一塊創辦了Adept AI公司,這家公司現在估值已經達到了10億美元呢!後來,他們又合作搞了一個Essential AI,這次他們融到了800萬美元的資金。這兩個公司都是做自動化工作流程的,厲害吧!
沙哥是個超厲害的人,他搞了個AI角色扮演聊天平台叫Character.AI,現在這家公司可值錢了,差不多有50億美元呢!最酷的是,它的使用者活躍度和留存率都比OpenAI還要高,真是太牛了!
烏茲哥回到了德國,他創辦了一家名為Inceptive的生物AI技術公司,這家公司現在的估值達到了3億美元。不僅如此,烏茲哥還透露說,他的父親,一位資深的計算語言學家,也在籌備一家新的AI公司,這家公司也是基於Transformer技術的。真是太厲害了!
凱哥是唯一一個沒有創業的人,但他在2021年加入了OpenAI,後來還參與了GPT-4和Q*專案,真是太厲害了!
最後走的是囧哥,他可真是個牛人。23年前,他跑到日本去創了個叫Sakana AI的公司,現在竟然估值2億美元了!真是讓人佩服。他最新搞出來的東西也特厲害,就是把擅長不同領域的大模型都融合在一起,然後再加上前進演化演算法,就搞出了個更強大的模型。這簡直就是黑科技啊!
許多在谷歌工作多年的老員工都說,谷歌好像變了。以前那裏是個充滿創新精神的樂園,現在卻變得越來越像一個只看重利潤、講究規矩的官僚機構了。
就算是在2020年谷歌釋出了Meena聊天機器人之後,沙哥還是發了一封內部信,標題就是「Meena吞噬世界」。他在這封信裏得出的關鍵結論是:
簡單來說,語言模型將逐漸深入我們生活的各個角落,而且在全球的算力裏面,它也會變得特別重要。我們可以預見,它在未來會扮演非常重要的角色。
這簡直就是未蔔先知啊,幾乎完全預測到了現在ChatGPT時代正在發生的事情。真是讓人驚嘆!
不過,那時候谷歌的高層還是不為所動,重要的決策者們不僅沒當回事,還嘲笑了他。
谷歌以前就像是掌握了整個AI世界的所有密碼,但是呢,他們不小心把整個密碼串都弄丟了。真是讓人吃驚啊!











