生成式AI時代,數據能力成為企業差異化競爭的關鍵。
「每家企業都可以用業界最好的基礎大模型,但差異化來自如何利用自身數據構建具有真正商業價值的生成式AI套用。」近日在一次溝通會上,亞馬遜雲科技大中華區產品部總經理陳曉建這樣表示。
目前, 檢索增強生成(RAG)、微調、持續的預訓練,是企業套用大模型的主要方式。 在這些核心場景中,數據是繞不開的關鍵,尤其是當企業希望量身客製垂直領域的AI套用時。
要打造更懂業務的生成式AI套用,企業需要具備哪些數據能力?在幫助各個行業、各種規模的企業打造數據基座方面,亞馬遜雲科技分享了自身的經驗與技術工具。

針對微調和預訓練的數據能力:儲存、加工與治理
要做好微調和預訓練,企業需要解決三個主要的數據問題:找到合適的儲存方案來承載海量數據;清洗加工原始數據為高質素數據集;高效的數據治理。
在儲存方面, 海量的多模態數據和儲存效能是企業的核心挑戰。微調和預訓練使用的數據往往都在TB甚至PB級別,而且檔格式多種多樣,需要進行抽取處理轉換。同時,微調和預訓練大模型需要極高的儲存效能。從而避免因為數據傳輸瓶頸造成高昂計算資源的浪費,或是吞吐量瓶頸導致更長的訓練時間。
亞馬遜雲科技物件儲存服務Amazon S3能夠應對企業執行大數據分析、人工智能 (AI)、機器學習 (ML) 和高效能計算 (HPC)等儲存需求。透過對冷、溫、熱數據的智能分層,Amazon S3可以大幅降低數據儲存成本。目前亞馬遜雲科技上超過20萬個數據湖都使用了Amazon S3。
檔儲存服務Amazon FSx for Lustre能夠提供亞毫秒延遲和數百萬IOPS的吞吐效能。LG集團的AI研究中心LG AI Research借助Amazon FSx for Lustre加速模型訓練,降低了35%的成本。
預訓練模型時, 數據清洗加工 的過程非常復雜且耗時,包括數據收集、數據清洗篩選、數據去重、分詞等步驟。以公開搜集的2TB英文數據集為例,經過清洗、去重後變成1.2TB的數據,再經過分詞處理才能變成大約3000億的tokens。
無伺服器數據整合服務Amazon Glue可以更快地整合數據,連線不同資料來源並簡化相關程式碼工作。大數據服務Amazon EMR serverless能夠更快地執行大數據應用程式和PB 級數據分析,並且成本不到本地解決方案的一半。
在數據治理方面, 企業需要跨多個賬戶和區域高效尋找數據,並進行精準的數據存取控制。
Amazon DataZone讓企業能夠跨組織邊界大規模地發現、共享和管理數據,並透過統一數據管理平台對多源多模態數據進行有效編目和治理。

將專有數據與大模型結合的數據能力:向量數據儲存
前面提到的數據儲存、加工與治理,只是使用大模型的基礎準備工作。
基礎模型自身有較大的局限性,比如缺乏垂直領域專業知識、缺乏時效性、幻覺問題,以及使用者私密數據的安全問題等。因此,只有讓企業私有數據與大模型相結合,才能讓大模型解決業務問題。
試想一個場景,一家保險公司想要針對客服場景開發一個對話智能體。當一個新客戶咨詢「我想購買汽車保險」時,對話智能體能夠自動推薦產品。這就需要大模型了解企業的保單產品和報價體系,理解使用者畫像和上下文語意等等。

這背後離不開檢索增強生成RAG能力。RAG首先將不同類別的源數據透過分詞處理和向量化,儲存到向量儲存中,再執行語意相似度搜尋,匹配提示詞中語意相似的上下文。
這一過程中,向量數據儲存是非常關鍵的。 最理想的情況,是將向量搜尋和數據儲存結合在一起。 這樣企業無需添加額外的元件和費用,也無需遷移現有數據,就能實作更快的向量搜尋。
目前,亞馬遜雲科技已經在八種數據儲存服務中添加了向量儲存與檢索功能,幫助企業更低成本使用RAG能力。
將數據儲存服務和向量檢索能力相結合,能夠發揮二者優勢互補的作用。
以制造業中被廣泛套用的知識圖譜為例,知識圖譜擅長結構化知識,但不能理解自然語言,只能做嚴格推理。基礎模型正好相反,能夠理解自然語言但缺乏專業知識。兩者結合可以獲得更精確的專業知識以減少幻覺,也可以對不準確的回答進行溯源和糾偏。
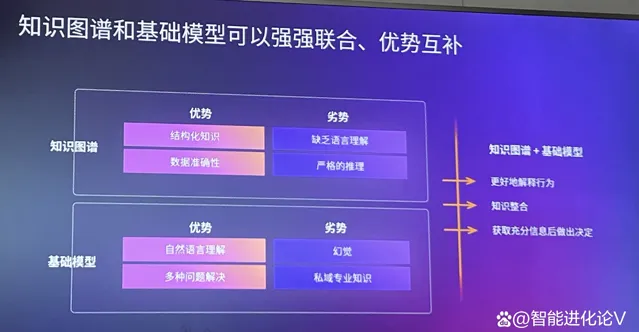
加速生成式AI套用的數據能力:基礎模型緩存與無伺服器服務
在生成式AI套用開發方面,基礎模型緩存與無伺服器數據服務,能夠大幅降本增效,讓企業集中精力於AI業務創新。
對於一個生成式AI套用,如果頻繁呼叫基礎模型將會導致成本增加和響應延遲。相對於數據庫呼叫通常毫秒級甚至微秒級的響應時間,基礎模型每次呼叫時長往往達到秒級。
而很多時候,終端使用者大部份問題是類似甚至重復的。 透過緩存給出回答,不但能夠減少模型呼叫,還可以節約成本。
Amazon Memory DB記憶體數據庫本身就是一個高速的緩存,同時也支持向量搜尋。它能夠儲存數百萬個向量,能夠以99%的召回率實作每秒百萬次的查詢效能。這對於欺詐檢測和即時聊天機器人等場景至關重要。
此外, 相比自建數據庫和托管數據庫,無伺服器數據庫服務能夠幫企業最大限度減少復雜的運維工作,並根據需求快速擴縮資源。
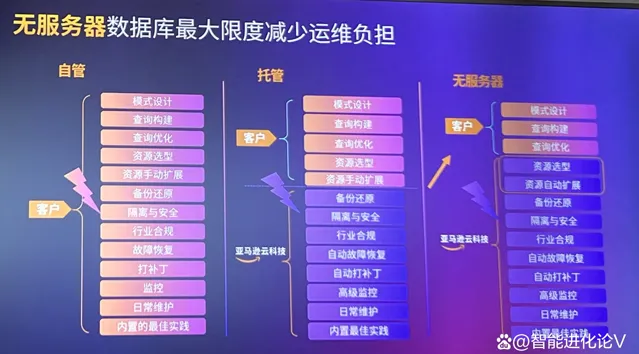
綜上,構建生成式AI套用,一切要從數據做起。
只有當企業將自身數據與基礎模型結合,構建出具有獨特價值的生成式AI套用,才能打造出「數據-模型-套用」正向迴圈的數據飛輪。
END
本文為「智能進化論」原創作品。











