今年到 CNCC 現場參會的朋友,想必都對 CNCC 2024 舉辦所在地——超過 6200 畝的橫店圓明新園印象深刻!
雖然園內建築身臨其境,並且薅了主辦方一把羊毛,免門票遊覽了圓明新園與橫店多個著名旅遊景點,但園子實在是太大了。參會人數超過 1 萬 2,園內車輛、美食供不應求,小編表示腿已經走斷。
也是急中生智,我們想到:是否能用 AI 幫我們在橫店點一杯咖啡?
結果,智譜真的做到了!
在今年的 CNCC 上,智譜釋出了一個新功能:自主智能體 AutoGLM,智譜將其稱為是一個可模擬使用者點選螢幕的手機操作助手,以及點選網頁的瀏覽器助手。
我們現場實測,整體操作非常絲滑:可以透過一句話下達任務指令,AI根據我的指令,開啟了美團,按照我的要求點了咖啡,過程中除了付款環節不需要人的任何參與。
智譜這次釋出的 GLM-4-Voice 情感語音模型「活人感」簡直溢位螢幕,不僅能「呼吸」,撒嬌也信手拈來,時不時有種「 AI 林誌玲」的哎呀調調,話語間內建波浪號「哎~呀~」……
並且,我們真的成功在 CNCC 會場喝上了AI點的咖啡!
目前 Web 能力已經透過「智譜清言」外掛程式對外公開使用,不過手機端僅開放了安卓使用者體驗:https://chatglm.cn/main/gdetail/6715f75ec8d0a702dff1e4e6?lang=zh
從文本到文生圖、文生影片,再到語音,事實上智譜本次的新技術成果釋出反映了在通往 AGI 追夢之路上的重新思考。
在 CNCC 大會第二天上午的主題圓桌論壇中,香港大學馬毅教授提到,人類智能在大自然的前進演化過程中有兩個「原生大模型」,一個是 DNA,另一個是語言;而之所以稱這兩個特征為大模型,是因為其本質上都具備自我學習的能力。
盡管今年的大模型已經發展到了一個新高度(如 o1 的復雜推理),但現在大模型知識豐富、智能不足的短板仍是行業共識。如圓桌論壇中唐傑所言,我們距離 AGI 的實作還很遙遠,這中間的研究趨勢至少包含三步:多模態、推理與自我學習。
在 AI 能夠自我推理、自我學習之前,多模態是必須跨過的一步,因為人類的智能學習規律就是文本、影像、語音乃至觸覺、嗅覺等更多五官共同學習、相輔相成。

(智譜發了一個AGI行程圖)
而 AutoGLM,其實是智譜在工具能力上的新研究,也是智譜所思考的 AGI 實作路徑之一。
「活人感」滿滿的 AI 助手
在進一步分析理解智譜的 AGI 技術路徑之前,我們先來看一下智譜在語音模態上所取得的最新突破——
當前,智譜清言情感語音助手在響應和打斷速度、情緒感知、情感共鳴、語音可控表達、多語言多方言等方面均實作了突破。
AI 科技評論對於這一系列功能革新進行了一番實測:
首先,我們給小智進行了一個比較常規的英語陪練測試,在糾正發音方面她確實表現良好,甚至日語練習的切換也相當絲滑。
隨之,聽說「小智」還精通北京腔、台灣腔、東北腔和粵語,作為廣東人,可不能放過這個為難她的機會,於是,我們測試了「各個國家有各個國家的國歌」這段入門級粵語繞口令。
實測發現,小智的粵語發音其實不算非常地道,甚至有一股泰國味。不過,在這之中,值得表揚得是,她能在領悟到我們的訴求是需要粵語回答時,自動將「旁白」部份也切換為粵語。
之後,她又加贈了一段「吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮」的粵語繞口令展示,還想讓我們也試試看。
而面對我們刻意為難提出的「加快語速」要求,小智也一寵到底,隨著倍速居然能明顯體會到她的情緒愈發激動,甚至伴隨有呼吸聲。
整體上看來,可謂是「活人感」十足。
同時,本屆 CNCC 落地橫店也給了小智些許施展拳腳的機會,我們帶著小智一同遊覽了知名景點「秦王宮」,並讓她化身李白澎湃激昂作詩一首。
小智寫的詩是這樣的:
「秦王宮中念群臣,壯誌淩雲繪風雲。金戈鐵馬盡奔騰,萬古英雄氣不容。」
還挺有鼻子有眼的。
之後我們也嘗試上了難度,想要前述古詩的東北腔讀法,不過,小智貌似沒有完全理會,她「哎呀媽呀」一聲張口就來,隨性發揮了一篇東北腔版秦王宮誇誇小作文。
小智還時常戲癮大作,我們也讓她即興給我們講了一段鬼故事,並模仿了故事中的女鬼笑聲:
讀到這裏,小智所呈現的形象可能帶有一絲幽默,甚至有些調皮。但值得關註的是,她其實也能給出非常多建設性的建議,並且在安慰人這方面也很走心。
我們扮演了一個疲憊打工人的角色和她半夜訴苦,小智也給足了情緒價值,甚至能代入閨蜜視角給到積極正向的安慰。
實際上,在對話開頭,我們還告訴小智,在下班路上因為看到了彩虹而感到開心。
她不僅共情,還把這個內容默默記下了,下輪對話開啟時,其第一句招呼語便是「希望彩虹帶來的好心情能持續陪伴你,工作再忙也要記得照顧自己的情緒喲!」
這種每次開啟新一輪對話時 Call Back 的細節處理,確實讓人眼前一亮。
不過,我們也找到了 AI 無法替代人類智慧的證明,我們嘗試和小智玩海龜湯遊戲,湯面是「媽媽買回來一個大西瓜,我吃了,第二天我死了。」
小智推理出的答案是,西瓜可能有致命的細菌或者農藥殘留,不能否認其中有一定道理,但之後她似乎開始逐漸忘記海龜湯的遊戲規則,居然反問我們還有什麽具體細節,這個測試到此戛然而止。
「人情味」背後的技術支撐
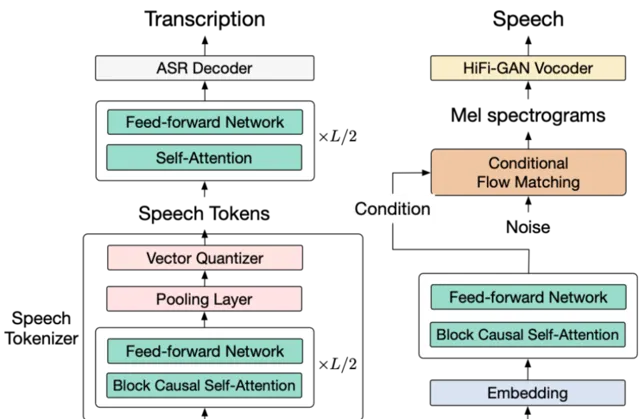
據智譜在 CNCC 現場的釋出介紹,AutoGLM 是基於智譜 GLM 大模型家族的新成員——GLM-4-Voice 情感語音模型。
熟悉智譜的朋友知道,今年初智譜推出第四代基座大模型 GLM-4 後,在 8 月的 KDD 2024 上又快速叠代升級了基座大模型 GLM-4-Plus,至此,大模型開始有了「眼睛」和「嘴巴」。
在語音上,8 月的智譜清言就已經可以即時影片通話。但 CNCC 釋出的新成果 GLM-4-Voice 無論在底層技術還是語音輸出效果上都更上一層樓。
作為端到端的語音模型,GLM-4-Voice 避免了傳統的 「語音轉文字再轉語音」 級聯方案過程中帶來的資訊損失和誤差積累,擁有理論上更高的建模上限。
與傳統的 ASR + LLM + TTS 的級聯方案相比,端到端模型以音訊 token 的形式直接建模語音,在一個模型裏面同時完成語音的理解和生成。
具體來看,智譜基於語音辨識(ASR)模型以有監督方式訓練了音訊 Tokenizer,能夠在 12.5Hz(12.5 個音訊 token)單碼表的超低碼率下準確保留語意資訊,並包含語速,情感等副語言資訊。
語音合成方面,則采用了 Flow Matching 模型流式從音訊 token 合成音訊,最低只需要 10 個 token 合成語音,最大限度降低對話延遲。
而在預訓練方面,為了攻克模型在語音模態下的智商和合成表現力兩個難關,智譜將 SpeecpSpeech 任務解耦合為 SpeecpText(根據使用者音訊做出文本回復) 和 Text2Speech(根據文本回復和使用者語音合成回復語音)兩個任務,並設計兩種預訓練目標適配這兩種任務形式:

圖|GLM-4-Voice 預訓練數據構造
能實作富有情感的對話背後,也離不開 GLM-4-9B 在深入對話理解上的支持。
智譜 GLM-4-9B 模型的上下文從 128K 擴充套件到了 1M tokens,使得模型能同時處理 200 萬字的輸入,大概相當於 2 本紅樓夢或者 125 篇論文的長度。
此次新釋出的 GLM-4-Voice 則在 GLM-4-9B 的基座模型基礎之上,經過了數百萬小時音訊和數千億 token 的音訊文本交錯數據預訓練,擁有了很強的音訊理解和建模能力。
智譜對 AGI 的探索與思考
在大模型還沒火起來之前,智譜團隊就嘗試過將其能掌握的所有中英文語料、影像、影片、語音等數據一起輸入,參數規模甚至過萬,但卻發現:相較團隊早期訓練過的文本模型 GLM-10B 來說,萬億參數規模的多模態大模型反而在文本能力上有所下降。
從人類智能的角度來看,五官是我們認識視覺最直接的介質,並且視覺、聽覺與語言能力之間往往能相互增強。但在對 AI 多模態模型的探索中,結果卻是相反:文本模態的智能水平並沒有因為影像模態而增強,反而削弱。這個「非共識」的發現也影響了行業對 AGI 路徑的思考。
多模態是實作 AGI 的必經之路是業界共識。但是,多模態的研究要怎麽展開?這其實是一個尚未形成共識的開放性問題,也是未來國產大模型需要繼續思考的問題。
盡管 OpenAI 釋出的 GPT-4V 與 GPT-4o、谷歌釋出的 Gemini 讓業內人員認為,多模態的發展應該朝著像海外 OpenAI 與 谷歌的技術路線去發展。但科學的懷疑、驗證精神在多模態研究中仍不可或缺。
比如,目前文生圖、文生影片或圖生影片等多模態的研究,就沒有與主流的基礎文本推理大模型結合起來,不同模態之間的 Gap 還很遠。如何將不同模態結合起來,也是一個亟待解決的問題。
根據 AI 科技評論對智譜過去三年的觀察,智譜的 AGI 路徑事實上是:先聚焦文本大模型的能力提升,但在 GLM-3、GLM-4 等基座大模型釋出後,智譜很快就將影像、視覺、語音等提升了日程,並同時不忘叠代程式碼模型、影片生成模型等。
智譜不僅聚焦單一模態的單點能力提升(如 ChatGLM3),也註重雙模態、多模態的結合——但無論從哪個角度來看,智譜版的「Her」都具備了比現有國產大模型公司更全面的模態能力。
根據智譜 CEO 張鵬的介紹,在智譜看來,人工智能的分級從大語言-多模態-使用工具-自學習,也可以分為 L1 到 L5 這五個等級。除了 L1 到 L3 這三塊為大家共識的分級外,L4、L5 就體現了前文所說的「AI 自我學習」能力:

從這個維度來看,智譜本次在 CNCC 釋出的手機助手能幫我們現場點咖啡,已經是達到 L3 的工具使用階段。
而且 CNCC 現場獨家據悉,智譜在本月底將推出生成影片模型 CogVideoX 的升級版本 CogVideoX-Plus,張鵬透露的升級亮點是:60幀幀率、4K畫質、10s時長、任意比例圖生影片、運動穩定性大幅提升。

智譜內部認為,目前我們距離 AGI 的道路只走了 42%。
他們根據大腦的能力,將 AGI 的技術維度分為了視覺、聽覺、語言等多模態感知與理解能力;此外,還有 AI 模型的長短期記憶能力、深度思考與推理能力、情感與想象力等。
此外,作為人的身體指揮器官,大腦還能調動身體的各個部份協同運轉,使用各種工具——而這個方向,就是目前具身智能、具身大腦所探討追求的方向。
如果將大腦的能力區域劃分為 AGI 的技術路線圖,如下圖所示,事實上目前的 AGI 科技樹還有絕大部份沒有被點亮。也就是說,在 42% 以外,智譜與當前包括 OpenAI 在內的其他大模型公司還有很長的路要走。
同時,當 AGI 參考人類大腦的能力畫出如上技術路線分布圖後,智譜的 AGI 研究也超越了追趕 OpenAI 的階段。這也是一份技術指南,能夠告訴大家:除了 GPT-o1 的推理能力,智譜還會發力其他的方向,如自我學習,模型指揮「肢體」執行工作任務等。
GPT-o1 體現的思維鏈從 2022 年開始,經歷過從一兩步推理到一致性推理、再到復雜多步推理的提升。從研究趨勢上來看,多模態與推理都是實作 AGI 的必經之路,但無論是智譜 GLM 多模態家族、還是 GPT-o1,都體現出綜合系統單點突破、循序漸進的第一研究原理。
在追趕 AGI 的路上,我們應該樂觀,但也要清楚認知目前所處的位置,不斷追趕。 雷峰網雷峰網











