過去一年多,生成式人工智能(AI)套用的爆炸式增長刺激了對人工智能伺服器的需求,以及對人工智能處理器的需求猛增。這些處理器中的大多數(包括 AMD 和 Nvidia 的計算 GPU、Intel 的 Gaudi 或 AWS 的 Inferentia 和 Trainium 等專用處理器以及 FPGA)都使用高頻寬記憶體 ( HBM ),因為它提供了當今可能的最高記憶體頻寬。
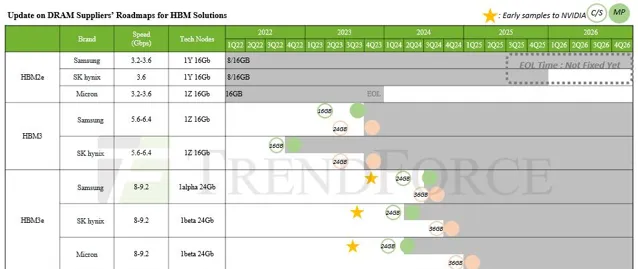
因此,根據TrendForce 的說法,記憶體制造商美光、三星和 SK 海力士在 2023 年將 HBM 產量提高以後,並在 2024 年進一步提高,例如三星就在最近宣布了擴產計劃。
這些承諾將成為業界的挑戰。
雖然HBM很不錯,但有很多 AI 處理器,特別是那些設計用於執行推理工作負載的處理利用 GDDR6/GDDR6X 甚至 LPDDR5/LPDDR5X 。
此外,還可以給執行 AI 工作負載(針對特定指令進行最佳化)的通用 CPU 準備使用商用記憶體,這就是為什麽在未來幾年我們將看到 MCRDIMM 和 MRDIMM 記憶體模組將顯著提高容量和頻寬達到新的水平。
但我們必須強調的是,HBM 仍將保持頻寬王者地位。
HBM:不惜一切為頻寬
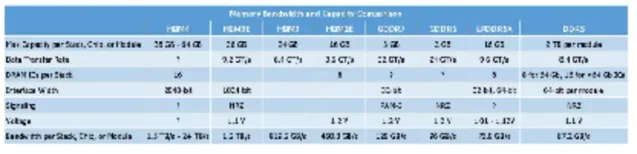
考慮到現代類別記憶體的效能規格和功能,HBM 在頻寬需求大的應用程式中如此受歡迎的原因顯而易見。每個堆疊的速度約為 1.2 TB/s,任何傳統記憶體都無法在頻寬方面擊敗 HBM3E。但這種頻寬是有代價的,並且在容量和成本方面存在一些限制。
人工智能工程聯盟MLCommons的執行董事 David Kanter 表示:「HBM 不僅具有優越的頻寬,而且還具有功耗,因為距離很短。」 「主要弱點是它需要先進的封裝,目前限制了供應並增加了成本。「但 HBM 幾乎肯定會永遠占有一席之地。」
HBM 的這些特性使得 DDR、GDDR 和 LPDDR 類別的記憶體也用於許多需要頻寬的套用,包括 AI、HPC、圖形和工作站。美光表示,這些容量最佳化和頻寬最佳化類別記憶體的開發正在迅速進行,因此人工智能硬件開發人員對它們有明確的需求。
美光計算和網絡業務部高級經理 Krishna Yalamanchi 表示:「HBM 是一項非常有前途的技術,其市場未來增長潛力巨大。」 「目前套用主要集中在人工智能、高效能計算等需要高頻寬、高密度、低功耗的領域。隨著越來越多的處理器和平台采用它,該市場預計將快速增長。」
有分析人士指出,自 2012 年以來,訓練模型以每年 10 倍的速度增長,而且看起來[增長]並沒有放緩。」
特別有趣的是,那些需要 HBM 的公司往往會在一夜之間采用該標準的最新版本。
為此Gartner預測,高頻寬記憶體的需求預計將從 2022 年的 1.23 億 GB 激增至 2027 年的 9.72 億 GB,這意味著 HBM 位需求預計將從 2022 年占 DRAM 整體的 0.5% 增加到 2027 年的 1.6%這一激增歸因於標準 AI 和生成 AI 套用中對 HBM 的需求不斷升級。
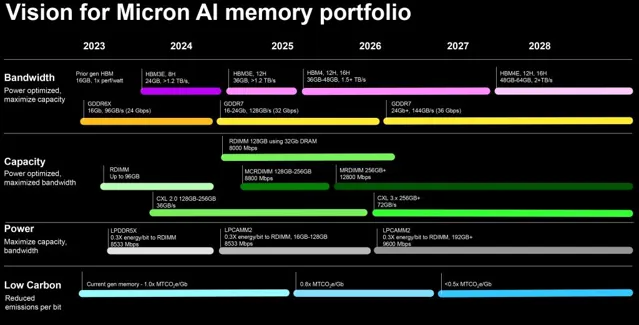
Gartner分析師認為,HBM收入將從2022年的11億美元增至2027年的52億美元,而HBM價格相對2022年的水平將下降40%。Gartner指出,由於技術進步和記憶體制造商的承諾不斷增加,HBM 堆疊的密度也將增加,從 2022 年的 16 GB 增加到 2027 年的 48 GB。與此同時,美光似乎更為樂觀,預計在 2026 年左右推出 64 GB HBMNext (HBM4) 堆疊。HBM3 和 HBM4 規範允許構建 16-Hi 堆疊,因此可以使用 16 個 32-Gb 器件構建 64 GB HBM 模組,但這將要求記憶體制造商縮短記憶體 IC 之間的距離,其中包括使用新的生產技術。
鑒於 Nvidia 占據了計算 GPU 市場的最大份額,該公司很可能成為業界最大的 HBM 記憶體消費者,並且這種情況將持續一段時間。
但我們也不得不承認,HBM難度極大。
HBM:太貴了,太難了
生產 HBM 已知良好堆疊芯片 (KGSD) 從根本上來說比生產傳統 DRAM 芯片更為復雜。首先,用於 HBM 的 DRAM 器材與用於商用記憶體(例如 DDR4、DDR5)的典型 DRAM IC 完全不同。記憶體生產商必須制造 8 或 12 個 DRAM 器材,對其進行測試,然後將它們封裝在預先測試的高速邏輯層之上,然後測試整個封裝。這個過程既昂貴又漫長。
「HBM 堆疊基於 3D 堆疊 DRAM 架構,該架構使用矽通孔 (TSV) 垂直連線多個芯片,這與商用 DRAM 根本不同,」Yalamanchi 說。「這種帶有 TSV 的堆疊架構可實作非常寬的記憶體介面(1024 位)、高達 36 GB 的記憶體容量,並可實作超過 1 TB/s 的高頻寬操作。DRAM 儲存體和數據架構從根本上進行了重新設計,以支持此類並列寬介面。」
這些並不是一個可怕的成本增加因素,這些工具和方法是根據 3D NAND 建立的,您可以透過矽通孔進行連線,所需要做的就是移植現有的 TSV 方法(來自 3D NAND),」DataSecure 技術長兼 Boolean Labs 技術長兼首席科學家 Michael Schuette說。
但用於 HBM 的 DRAM 器材必須具有寬介面,因此它們的物理尺寸更大,因此比常規 DRAM IC 更昂貴。這也是為什麽美光行政總裁 Sanjay Mehrotra 認為,為滿足人工智能伺服器的需求而增加 HBM 記憶體產量將影響所有 DRAM 類別的位元供應。
Mehrotra 在早前的電話會議上表示:「高頻寬記憶體 (HBM) 生產將成為行業位供應增長的阻力。」 「HBM3E 芯片的尺寸大約是同等容量 DDR5 的兩倍。HBM 產品包括邏輯介面芯片,並且具有更加復雜的封裝堆疊,這會影響良率。因此,HBM3 和 3E 需求將吸收行業晶圓供應的很大一部份。HBM3 和 3E 產量的增加將降低全行業 DRAM 位供應的整體增長,尤其是對非 HBM 產品的供應影響,因為更多產能將被轉移到解決 HBM 機會上。美光Mehrotra 在最近的電話會議上表示:「高頻寬記憶體 (HBM) 生產將成為行業位供應增長的阻力。」 「HBM3E 芯片的尺寸大約是同等容量 DDR5 的兩倍。HBM 產品包括邏輯介面芯片,並且具有更加復雜的封裝堆疊,這會影響良率。因此,HBM3 和 3E 需求將吸收行業晶圓供應的很大一部份。HBM3 和 3E 產量的增加將降低全行業 DRAM 位供應的整體增長,尤其是對非 HBM 產品的供應影響,因為更多產能將被轉移到解決 HBM 機會上。」
HBM3E 本質上是具有顯著減速的 HBM3,因此雖然 DRAM 制造商必須確保良好的良率,然後調整其生產方法以更有效地構建 8-Hi 24 GB 和 12-Hi 36 GB HBM3E KGSD,但新型記憶體將並不代表 HBM 生產的重大轉變。相比之下,它的繼任者將會。計劃的 HBM3E 產能提升對我們的位供應能力也產生了類似的影響。」
HBM3E 本質上是具有顯著減速的 HBM3,因此雖然 DRAM 制造商必須確保良好的產量,然後調整其生產方法以更有效地構建 8-Hi 24 GB 和 12-Hi 36 GB HBM3E KGSD,但新型記憶體將並不代表 HBM 生產的重大轉變。相比之下,它的繼任者將會。
HBM4 將記憶體堆疊介面擴充套件至 2048 位,這將是自八年前推出該記憶體類別以來 HBM 規範最重大的變化之一。對於記憶體制造商、SoC 開發商、代工廠以及外包組裝和測試 (OSAT) 公司而言,將 I/O 引腳數量增加兩倍,同時保持相似的物理占用空間,極具挑戰性。三星表示,HBM4 需要從目前用於 HBM 的微凸塊鍵合(這已經很困難且昂貴)過渡到直接銅對銅鍵合,這是一種用於整合的最先進技術未來幾年的多芯片設計。
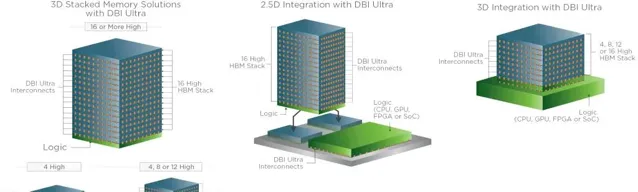
「如果我看看 [即將推出的 HBM4 規範] 和 2048 位寬介面,這將使引腳數達到約 5500 個引腳,這與大多數伺服器 CPU 或 GPU [就引腳數而言] 處於同一水平,」Schuette說。「如果您嘗試在小封裝設計中布線,最終會得到 20 層重新分布層/中介層之類的東西,如果您選擇更大的封裝、更少的層數,最終會超過允許的最大走線長度」。
SK 海力士甚至設想 HBM4 必須以 3D 方式整合在片上系統上才能實作最大效率,但這將進一步增加成本。
「在接下來的幾年中,我認為我們可能會透過更緊密的整合(例如 3D 堆疊)獲得卓越的效能和效率,但這可能會更加昂貴,」Kanter說。
Schuette 認為,由於 HBM4 的引腳數極高,使用具有插入器和重新分配層的傳統方法將具有 2048 位介面的 HBM4 堆疊連線到主機處理器可能非常困難。
「最微小的扭曲就會導致連線不良,」Schuette 解釋道。「如果它只是一個接地引腳,你可能不會註意到,但如果它是一個訊號引腳,你就完蛋了。
但 3D 封裝技術將需要更復雜的器材,因此很可能至少在最初只有代工廠自己會在 2025 年至 2026 年的某個時候提供 HBM4 整合。
據報道,為了不斷縮小 DRAM 單元尺寸並控制記憶體功耗,三星打算在 HBM4 中使用 FinFET 晶體管。FinFET 的結合預計將最佳化即將推出的 HBM 器件的效能、功耗和面積縮放。然而,該技術對成本的影響仍不確定。此外,三星何時在標準 DRAM IC 中采用 FinFET 的時間表尚未確定。目前,三星僅確認 FinFET 將用於 HBM4。
Salvador 表示:「成本問題仍然存在,HBM4 的實施問題可能會延長 HBM3/HBM3E 的使用壽命,特別是在成本更加敏感的地方。」
Yalamanchi 表示:「人們想要采用最快版本的 HBM 並不是一個準確的假設,因為許多因素都會影響記憶體技術的選擇,例如成本、供應限制、平台準備情況和效能要求。」
由於架構和封裝成本根本不同,HBM 仍將是一種昂貴的記憶體類別,服務於不斷增長的利基市場。Michael Schuette 部份同意這一觀點。他認為,雖然 HBM 很好地服務於其目標市場,但它很難滿足更廣泛的市場需求。
「HBM 似乎仍然是一種利基產品,並且很可能仍然是一種產品,」Schuette 說。
HBM 能否在成本上與商品或專業記憶體競爭?
「我不想說永遠不會,因為那是一段很長的時間,」Kanter說。「但 HBM 要想具有成本競爭力,就需要大幅降低封裝成本和/或顯著增加 GDDR 成本。或者可能是根本性的技術轉變——例如,如果 GDDR 從高速銅訊號轉為光纖訊號。但我不確定那時是否會是 GDDR。」
LPDDR:低功耗選項
雖然 HBM 在效能方面無與倫比,但對於許多套用來說價格昂貴且耗電,因此開發人員選擇將 LPDDR5X 用於其頻寬要求較高的套用,因為這種類別的記憶體為他們提供了價格、效能和功耗之間的適當平衡。
例如,蘋果公司多年來一直在其 PC 中使用 LPDDR 記憶體,然後才成為一種趨勢。到目前為止,該公司已經很好地完善了基於 LPDDR5 的記憶體子系統,其效能是競爭解決方案無法比擬的。Apple 的高端桌上型電腦 — 由 M2 Ultra SoC 提供支持的 Mac Studio 和 Mac Pro — 使用兩個 512 位記憶體介面可擁有高達 800 GB/s 的頻寬。結合實際情況來看:AMD 最新的 Ryzen Threadripper Pro 配備 12 通道 DDR5-4800 記憶體子系統,峰值頻寬可達 460.8 GB/s。
像蘋果一樣,在其整個器材系列中使用 LPDDR5 有一些額外的好處,例如 LPDDR5 控制器 IP 和 PHY 在不同的 SoC 中重復使用,以及大量采購此類記憶體,這為談判提供了更好的籌碼。蘋果當然不是唯一一家將 LPDDR 記憶體用於高頻寬處理器的公司。Tenstorrent 將這種記憶體用於其 Grayskull AI 處理器。
「如今,它們似乎服務於不同的利基市場,並且存在差異化的廣泛趨勢,」Kanter說。「HBM 更面向數據中心,LPDDR 更面向邊緣。話雖如此,絕對有人針對類似的市場使用不同的記憶體類別。以數據中心為例——有些設計使用 HBM,有些設計使用 GDDR,有些設計使用常規 DDR,有些設計使用 LPDDR。」
LPDDR 儲存芯片的顯著優勢之一是其相對廣泛的介面和相當快的執行速度。典型的 LPDDR5 和 LPDDR5X/LPDDR6T IC 具有 32 或 64 位介面,支持高達 9.6 GT/s 的數據傳輸速率,這比批次生產的 DDR5 數據速率(8 或 16 位、截至 2023 年 10 月,速度高達 7.2 GT/s)更好。此外,移動記憶體自然比客戶端 PC 和伺服器的主流 DDR 記憶體消耗更少的功率。
對於 Tenstorrent 開發的應用程式來說,記憶體頻寬至關重要,但功耗也至關重要,這就是為什麽如今 LPDDR 的使用範圍遠遠超出了智能電話和客戶端 PC。
GDDR:價格與效能之間的平衡
Tenstorrent 為我們帶來了另一種類別的記憶體,該公司將在即將推出的 Wormhole 和 Blackhole AI 處理器中使用這種記憶體。與此同時,Nvidia 將 GDDR6 和 GDDR6X 用於各種用於 AI 推理的 GPU。
「GDDR 記憶體用於人工智能和其他套用,對於人工智能推理套用來說是一個不錯的選擇,因為 GDDR 仍然提供比 DDR 更高的頻寬和更低的延遲,」Yalamanchi 說。「與 HBM 相比,GDDR 的成本更低,復雜性也更低。例如,GDDR6可以在Nvidia用於人工智能推理的Tesla T4 GPU以及用於人工智能推理和圖形套用的 L40S 中找到。」
GDDR6 通常比 LPDDR 消耗更多功率,並且現代 GDDR6/GDDR6X 芯片配備 32 位介面(即比某些 LPDDR5X 更窄),但 GDDR6/GDDR6X/GDDR7 記憶體的執行速度要快得多。
事實上,GDDR7 有望以高達 36 GT/s 的速度執行,並且在如此高的數據速率下,基於它的記憶體子系統將比采用 LPDDR5X 的記憶體子系統快得多,特別是要記住,我們正在談論潛在的寬記憶體介面,例如 384 或 512 位。即使在 32 GT/s 數據傳輸速率下,384 位 LPDDR7 記憶體子系統也可提供 1,536 TB/s 峰值頻寬,遠遠高於 512 位 LPDDR5X-9600 記憶體子系統 (614.4 GB/s)。然而,我們可以猜測,LPDDR7 記憶體子系統也將比使用 LPDDR5X 的記憶體子系統更加耗電,但考慮到其效能,我們認為這是一個公平的權衡。
MCR-DIMM 和 MR-DIMM
如果沒有 MCR-DIMM 和 MR-DIMM,關於高效能記憶體解決方案的故事就不完整,它們是主要為伺服器設計的新型雙列 DDR5 記憶體模組,目前正在開發中。這些技術背後的理念是,在每個 CPU 的核心數量不斷增加的情況下,進一步提高記憶體模組的效率,並將其峰值頻寬提高到超過 DDR5 支持的速度。
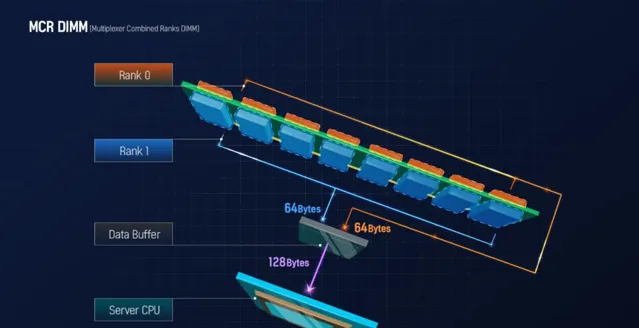
從較高層面來說,多路復用器組合列 DIMM (MCR-DIMM) 是配備多路復用器緩沖區的雙列緩沖記憶體模組。該緩沖區可以同時從兩個佇列檢索 128 字節的數據,並且它設計為以約 8800 MT/s 的高速與記憶體控制器配合使用(基於最近釋出的美光路線圖),即 400 MT/s高於原始 DDR5 規範規定的最大數據速率。這些模組旨在增強效能,同時簡化大容量雙列模組的構造。MCR-DIMM 得到了英特爾和 SK Hynix 的支持,並將獲得英特爾第六代至強可延伸「Granite Rapids」平台的支持,而美光計劃於 2025 年初推出 MCR-DIMM。
多列緩沖 DIMM (MR DIMM) 在概念上非常相似:它們是具有多路復用器緩沖區的雙列模組,可同時與兩個列互動,並以超出 DDR5 指定速度的速度與記憶體控制器一起執行。該標準的第一代速度為 8,800 MT/s,第二代為 12,800 MT/s,第三代最終達到 17,600 MT/s。該技術得到 JEDEC 、AMD、Google 和 Microsoft 的支持。美光計劃於 2026 年開始出貨速度為 12,800 MT/s 的 MR-DIMM。此類模組將提供巨大的頻寬和容量,這是由於數據中心 CPU 內的內核數量不斷增加以及對頻寬的需求而需要的。
「如果不采用新的形式來實作分類記憶體,那將是愚蠢的,」Schuette 說。「伺服器要求與客戶端不同,伺服器上始終需要 ECC,而客戶端 PC 上則不需要。」
奇異和混合記憶體子系統
雖然使用特定類別的記憶體可能是芯片和系統開發人員最明顯的做法,但也有人選擇使用不同類別記憶體的混合記憶體子系統。
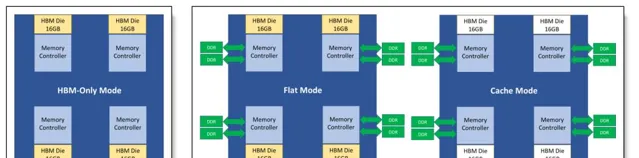
例如,英特爾的 Xeon Max CPU 搭載 64 GB 封裝 HBM2e,並支持高達 6 TB 的六通道 DDR5 記憶體,每個插槽最多使用 16 個 DIMM。這些 CPU 主要針對高效能計算 (HPC) 環境,可以在 HBM Only 模式、HBM Flat 模式(提供快速和慢速記憶體層)和 HBM Caching 模式下工作。
另一個例子是 D-Matrix 的 AI 處理器,內部配備 256 MB SRAM(150 TB/s),並支持高達 32 GB 的 LPDDR5 記憶體,但頻寬相當有限。這些芯片主要用於推理,其架構是針對此類工作負載量身客製的。
「一般來說,緩存或片上 SRAM 可以減少一些外部頻寬需求,」Kanter說。「因此,作為推斷,如果我們可以接受小於 100MB 的神經網絡,[緩存會有所幫助]。同樣,我們可以將記憶體整合得更緊密,以減少封裝外頻寬。但真正大型培訓系統的許多前沿工作,例如訓練下一代LLM,總是需要更多頻寬。」
雖然歷史上由不同類別記憶體組成的混合和奇異記憶體子系統已被廣泛使用,例如用於 Xbox 360 遊戲機的 ATI 的 Xenos GPU 以及基於 eDRAM 的「子芯片」或英特爾的 Xeon Phi 7200-對於同時使用 MCDRAM 和 DDR4 記憶體的系列協處理器,Schuette 認為此類記憶體子系統效率不高。
「我的觀點是,你會得到兩全其美的結果,」他說。「設計開銷巨大,復雜性很高,我什至不想進行故障排除。
另一方面,根據定義,所有具有 CPU 和加速器的系統都使用混合記憶體子系統,並且它們已被證明非常高效。
「如今許多人工智能系統都是混合系統,」Kanter說。「例如,許多訓練系統傾向於使用 HBM 作為加速器,但使用 DDR 作為主機處理器,而主機處理器實際上在這裏做實際工作。數據中心推理系統也類似。」
綜上所述,HBM雖然很好,但一統不了江湖。











